
In den Search Quality Rater Guidelines erklärt Google seine Sicht auf die perfekten Suchergebnisse. Eine Überarbeitung der Richtlinien zeigt, dass es Wörterbücher, Lexika und ähnliche Seitentypen künftig schwerer haben werden.
Search Quality Rater sind Freelancer, die für Google die Suchergebnisse anhand einer einheitlichen Bewertungsgrundlage einschätzen. Google nutzt diese Bewertungen, um die Qualität der Suchergebnisse zu messen und mögliche Verbesserungen zu bewerten.
Damit alle Search Quality Rater ihre Bewertungen auf einer einheitlichen Grundlage abgeben, gibt es die Search Quality Rater Guidelines. In diesem (mittlerweile öffentlichen) PDF-Dokument legt Google detailliert dar, was gute und was schlechte Treffer für bestimmte Keywords sind.
In der Vergangenheit hat Google in diesen Richtlinien die Konzepte von E-A-T (Expertise, Authority und Trustworthiness) und YMYL (Your Money, Your Life) erklärt. Aber auch die Weiterentwicklung der Suchintention auf Know, Do, Website und Visit in Person entstammt diesen Guidelines.
Heute hat Google die Search Quality Rater Guidelines das erste mal seit rund 10 Monaten überarbeitet. Neben einigen Ergänzungen und Klarstellungen ist besonders ein neuer Teil interessant für SEOs:
Unter dem Titel “Rating Dictionary and Encyclopedia Results for Different Queries” widmet Google der Bewertung von Treffern aus Wörterbüchern, Lexika und vergleichbaren Seiten nun ganze drei Seiten in den Richtlinien.

Inhaltlich geht es Google dabei um die Unterscheidung, dass diese Treffertypen zwar in der Regel “themenrelevant” für das Keyword sind, sie aber die Nutzerintention des Suchenden nicht erfüllen.
Google weist darauf hin, dass die meisten Nutzer die Bedeutung des Wortes bereits kennen. Die beste Bewertung soll diesen Treffern künftig nur noch zugeteilt werden, wenn Ergänzungen in der Suche wie “was ist xzy” darauf hindeuten, dass die Nutzerintention nach solchen Seiten verlangt. Beispiele aus den Guidelines:
- obsequious (unterwürfig) – dem “durchschnittlichen” Nutzer eher unbekannt. Vermutete Intention: Erklärung der Bedeutung, daher 4/5 für einen Wörterbuchtreffer
- rainbow – der Nutzer sucht keine Erklärung des Wortes Regenbogen, sondern eher Bilder, Marken oder lokale Geschäfte. Daher 2/5 für einen Wörterbuchtreffer
- cafeteria – Nutzer kennen den Begriff und suchen ein lokales Geschäft, keinen Wikipedia-Eintrag, daher 2/5 für Wikipedia
- history of atm machines – der Nutzer sucht hier explizit einen Lexikoneintrag zu Geldautomaten, daher 4/5 für Wikipdia
- atm near me – hier sucht der Nutzer sehr deutlich den nächstgelegenen Geldautomaten, also 1/5 für den Wikipedia-Eintrag
- atm – die Nutzerintention ist durch die Suche selber nicht klar, Google geht aber davon aus, dass die meisten Nutzer einen Geldautomaten suchen. Der Wikipedia-Treffer kriegt daher zwischen 0,5 und 1 von 5.
Interessant ist diese Entwicklung, da zahlreiche Wörterbücher, Lexika und vergleichbare Seitentypen in den letzten Jahren zu einer hervorragenden Sichtbarkeit in den Suchergebnissen gekommen sind. So hat wiktionary.org zum Beispiel derzeit die 13. höchste Sichtbarkeit in Deutschland und ist dabei in Google erfolgreicher als booking.com oder spiegel.de.
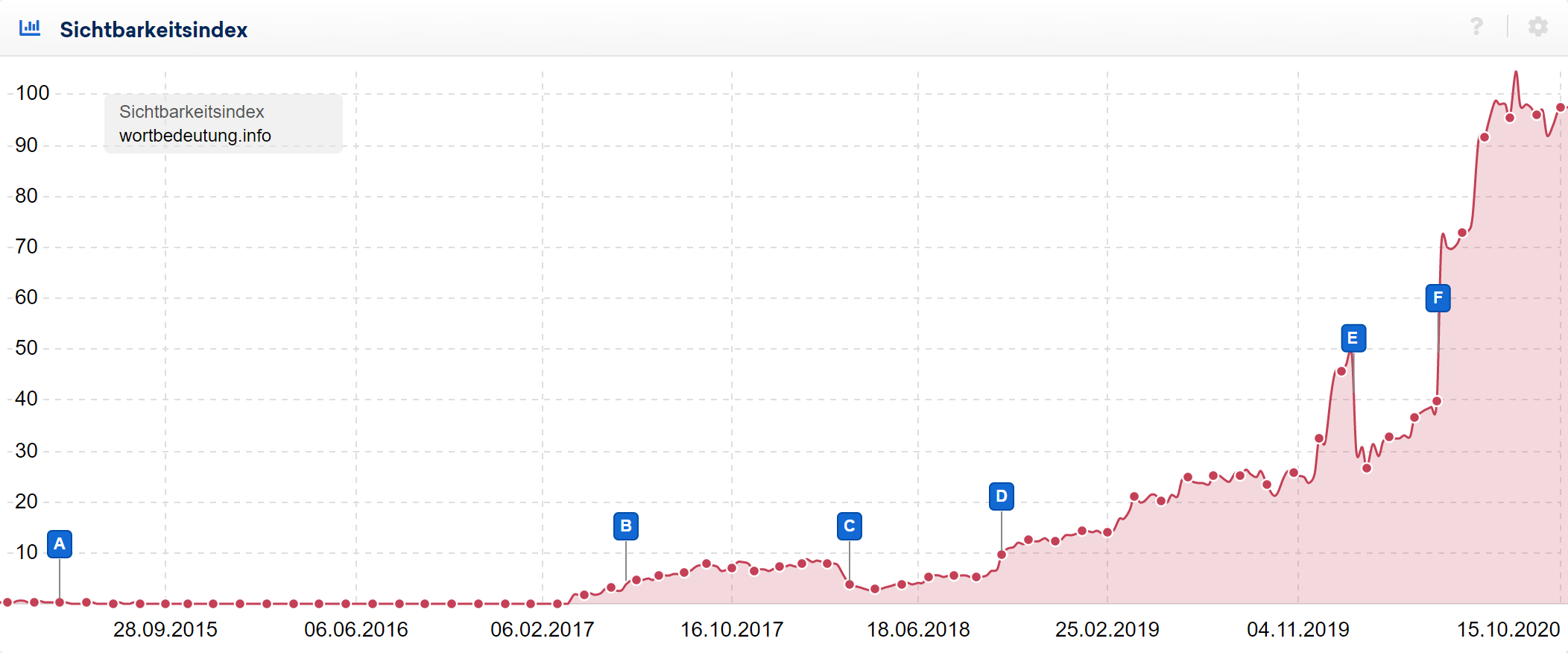
Unter den 100 erfolgreichsten Domains in Deutschland sind mit wiktionary.org, duden.de, pons.com, linguee.de, reverso.net, linguee.com, leo.org, dict.cc und wortbedeutung.info insgesamt mindestens neun Domains, auf die diese Änderungen der Guidelines zutreffen.
Wichtig ist noch im Hinterkopf zu behalten, dass Änderungen an den Guidelines keine automatischen Ranking-Änderungen nach sich ziehen. Aber doch ist klar, dass Google seine Sichtweise auf Wörterbücher und Lexika geändert hat. Interessant wird sein, ob die beliebten Glossare noch auf der “erlaubten Seite” stehen werden, wenn Google diese Änderungen in den Algorithmus überführt …