
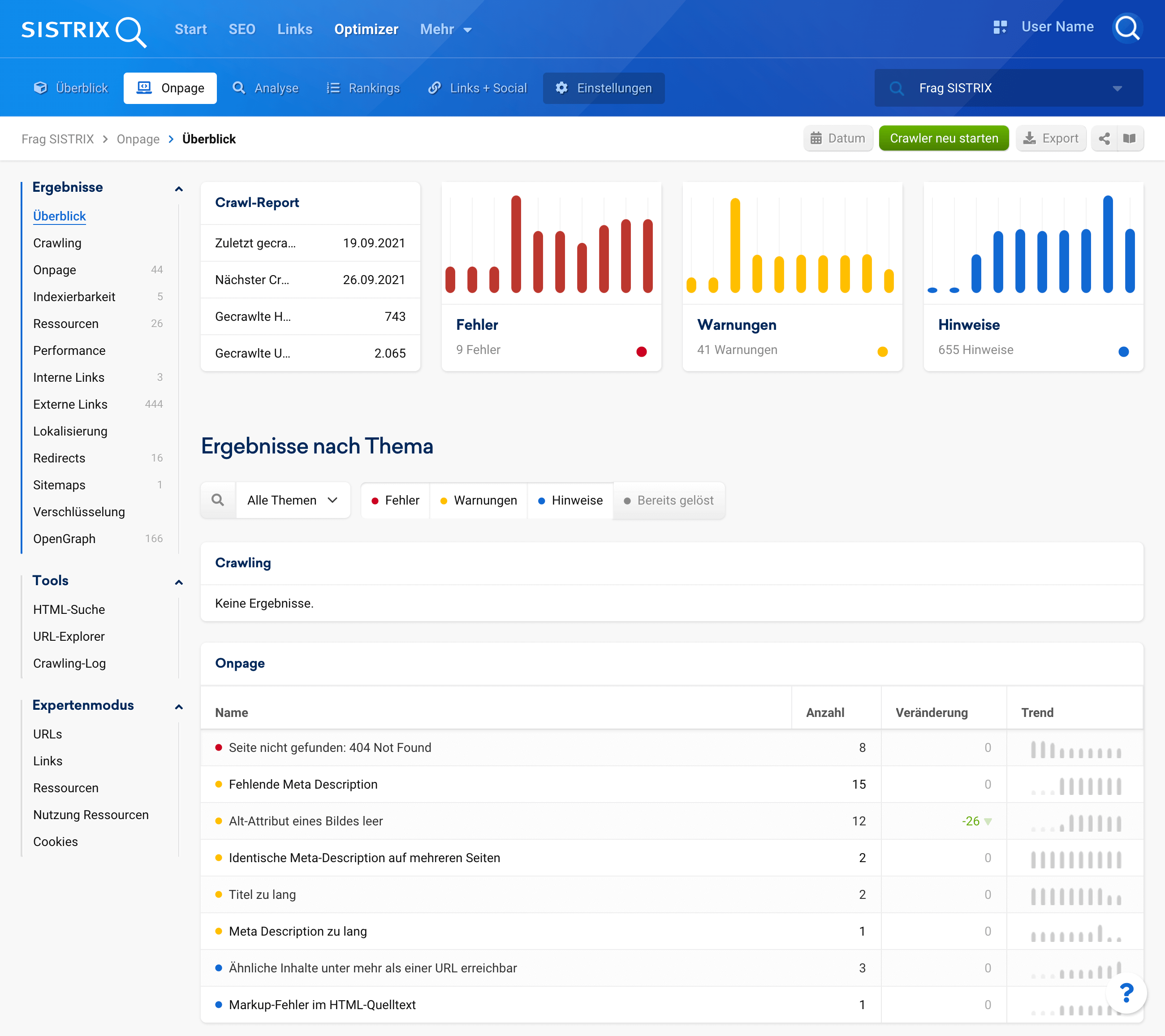
Suchmaschinenoptimierung
Der einfachste Weg zu einer technisch fehlerfreien Webseite
Technische Mängel einer Website sind Erfolgsverhinderer. Der SISTRIX Optimizer erkennt die Schwachpunkte in der Onpage-Optimierung und liefert Lösungsvorschläge. Sortiert nach Wichtigkeit, für schnelle Erfolge.
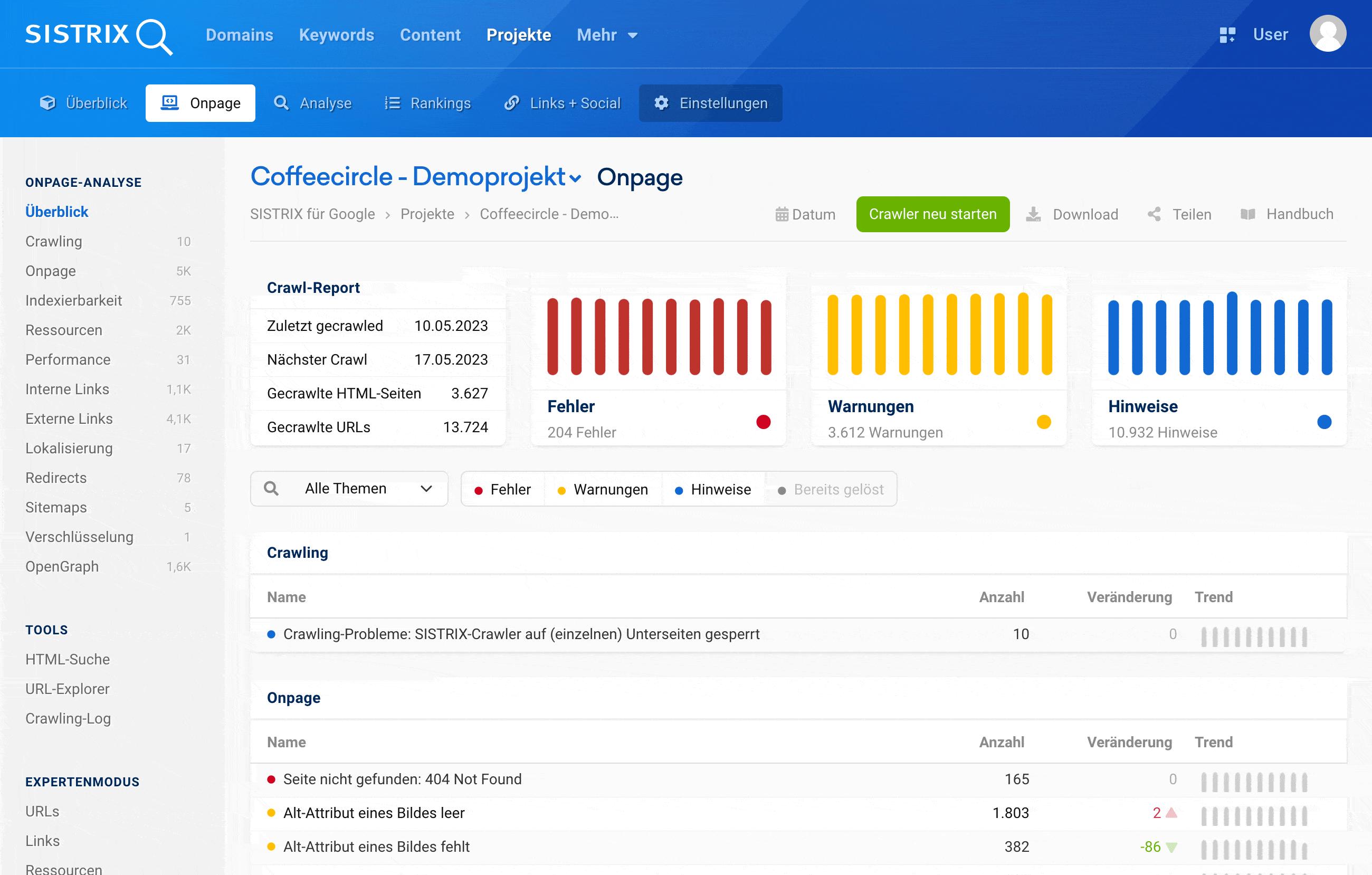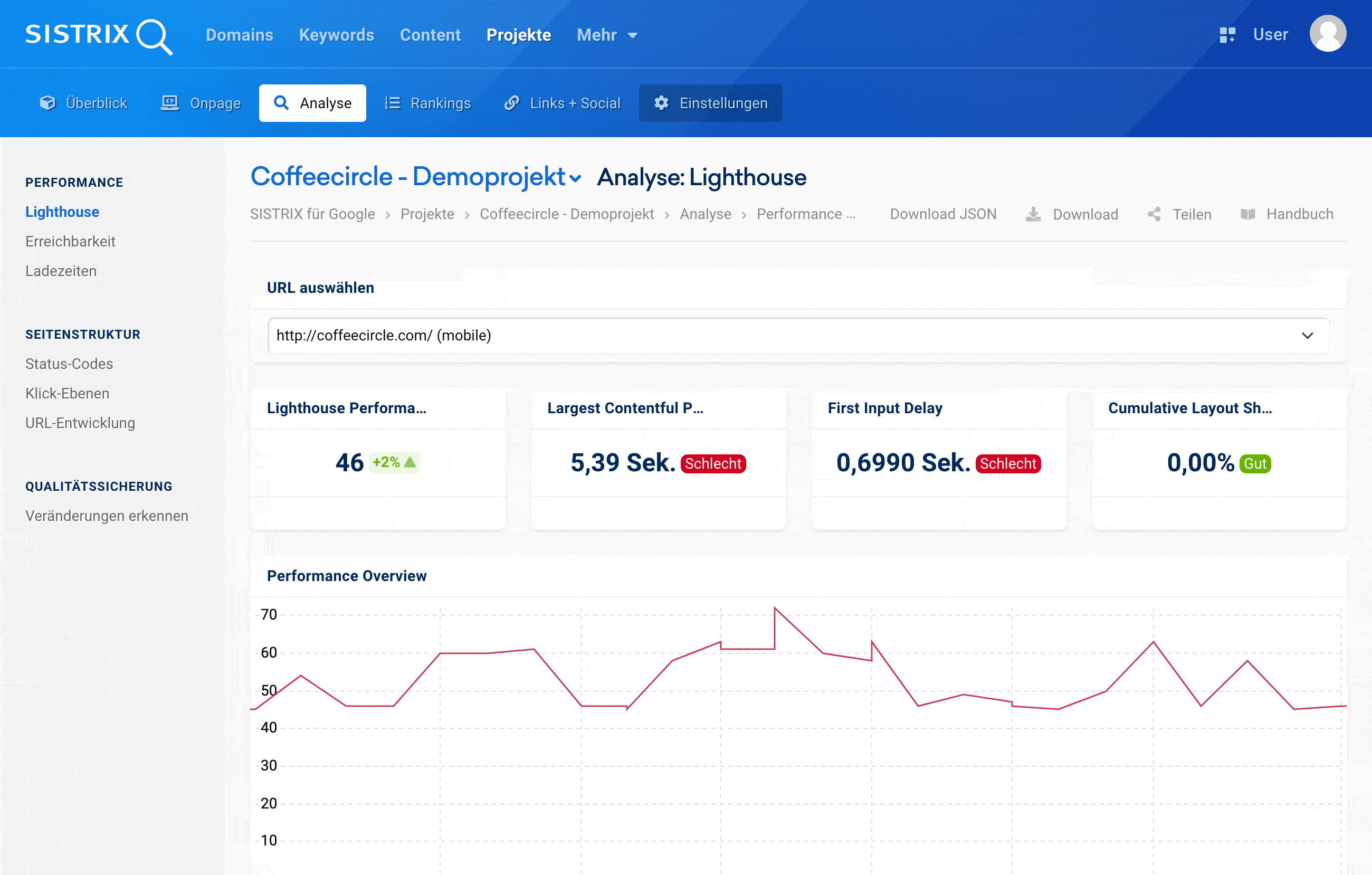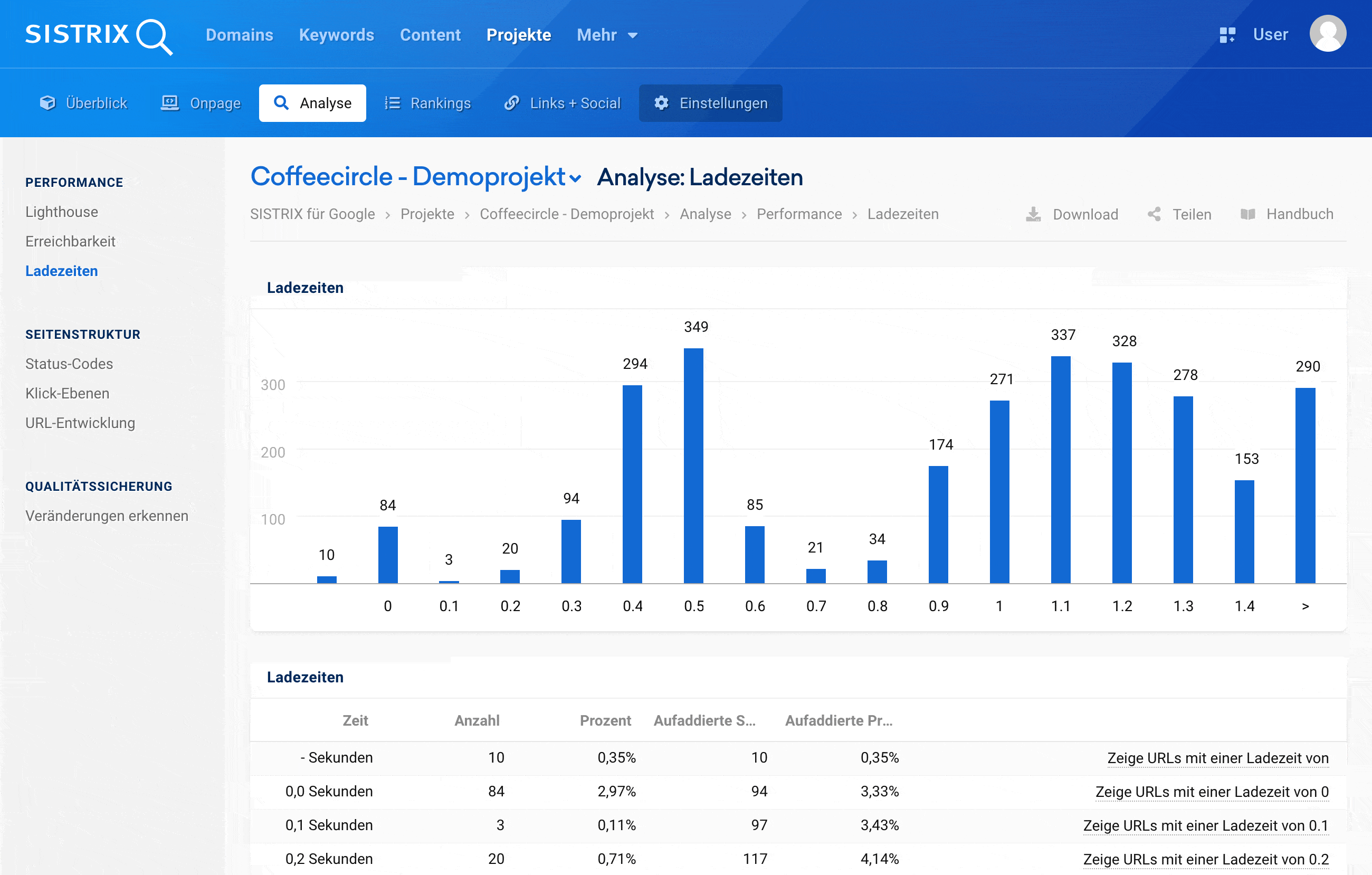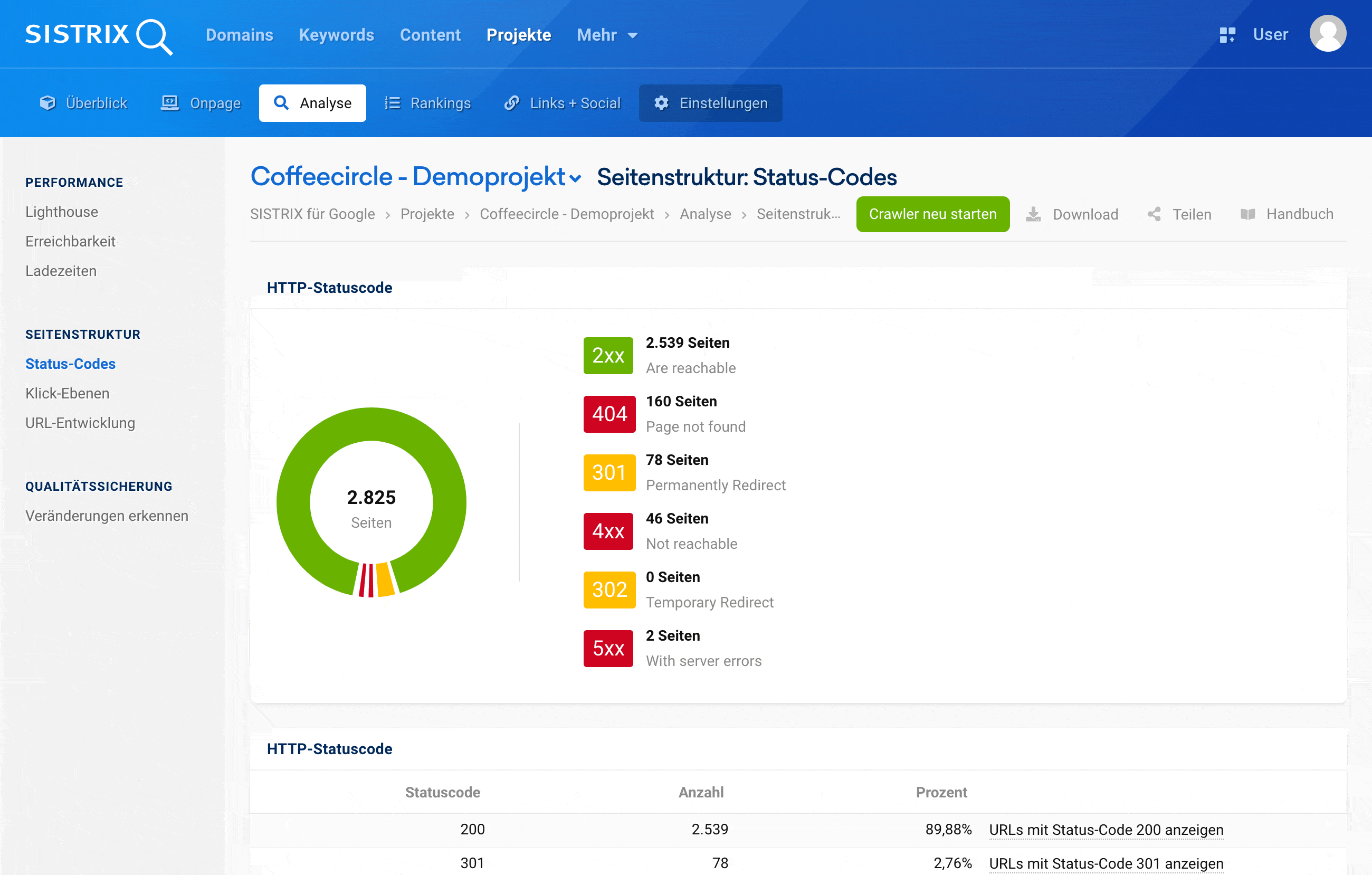
Entdecke Fehler auf deiner Webseite – bevor deine Besucher über sie stolpern
Der Webseitencrawler des SISTRIX Optimizer überprüft deine Seiten regelmäßig und automatisch auf vermeidbare Fehler. Verständlich erklärt zeigen wir dir, wie du diese Schwachpunkte beheben kannst.

Perfektes Teamwork: arbeite mit Kollegen und Kunden an einem Projekt
Zusammen schneller zum Ziel: in deine Projekte kannst du Kollegen aber auch Kunden einladen. So seid ihr alle immer auf dem gleichem Stand und könnt euer Ziel gemeinsam erreichen.
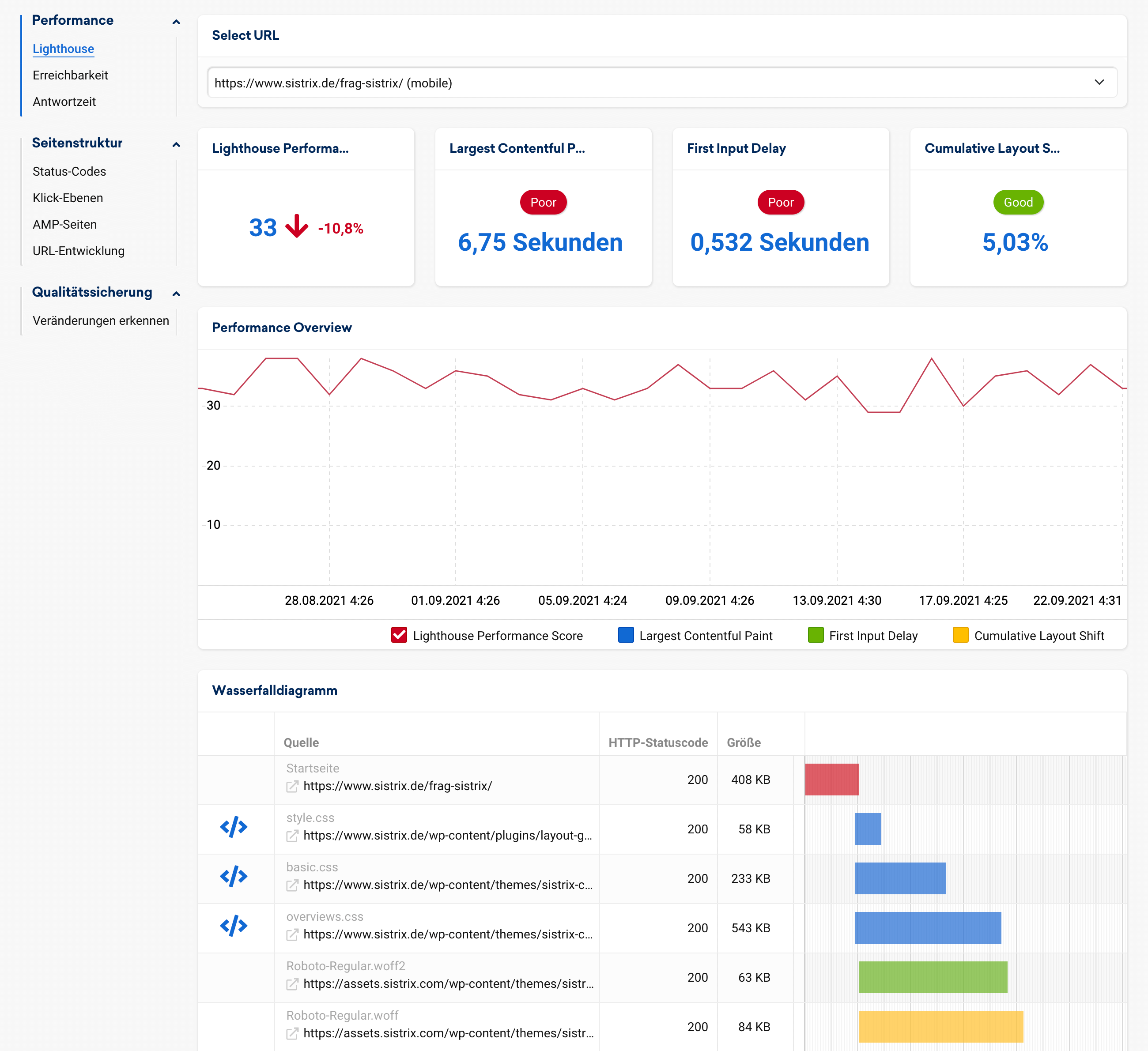
Rankingfaktor Webseiten-Performance – wissen, wie deine Seite abschneidet
Niemand wartet darauf, dass deine Webseite fertig geladen ist. Mit der gleichen Technologie, die auch Google nutzt, messen wir regelmäßig die Performance deiner Seite und zeigen dir Schwachstellen auf.
Wie der echte Googlebot: State of the Art JavaScript-Crawling
Das Internet ist dynamisch: die meisten modernen Webseiten setzen auf JavaScript. Der Crawler des SISTRIX Optimizer basiert daher auf der gleichen Technologie wie der offizielle Googlebot – für den besten Onpage-Audit.
Qualitätssicherung für große Webseiten: Änderungen einfach nachvollziehen
Hat der Praktikant etwa gerade alle mühsam optimierten Webseiten-Titel gelöscht? Die Qualitätssicherung im Optimizer zeigt dir relevante Änderungen an deiner Seite auf einen Blick.
Erreichbarkeits-Check: wir benachrichtigen dich, wenn deine Seite offline ist.
Nicht erreichbare Webseiten sind nicht nur für deine Besucher ein Problem – auch Google entfernt sie nach kurzer Wartezeit aus den Suchergebnissen. Der Optimizer überwacht die Erreichbarkeit jede Minute und warnt dich rechtzeitig.
SISTRIX kostenlos ausprobieren
Beginne noch heute, mit SISTRIX deine Rankings zu verbessern.
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten
Häufige Fragen & Antworten
Wie heißt der Crawler für die Onpage-Projekte? Der Crawler für die Erfassung deiner Homepage in den Onpage-Projekten von SISTRIX nutzt standardmäßig folgenden User-Agent:
Du kannst den User-Agent in den Einstellungen deines Projektes unter "Onpage-Crawler: Experteneinstellungen" (bei aktivem Expertenmodus) nach deinen Wünschen und Erfordernissen anpassen. Ab dem nächsten Crawl-Durchlauf nutzen wir fortan den von dir eingegeben User-Agent. 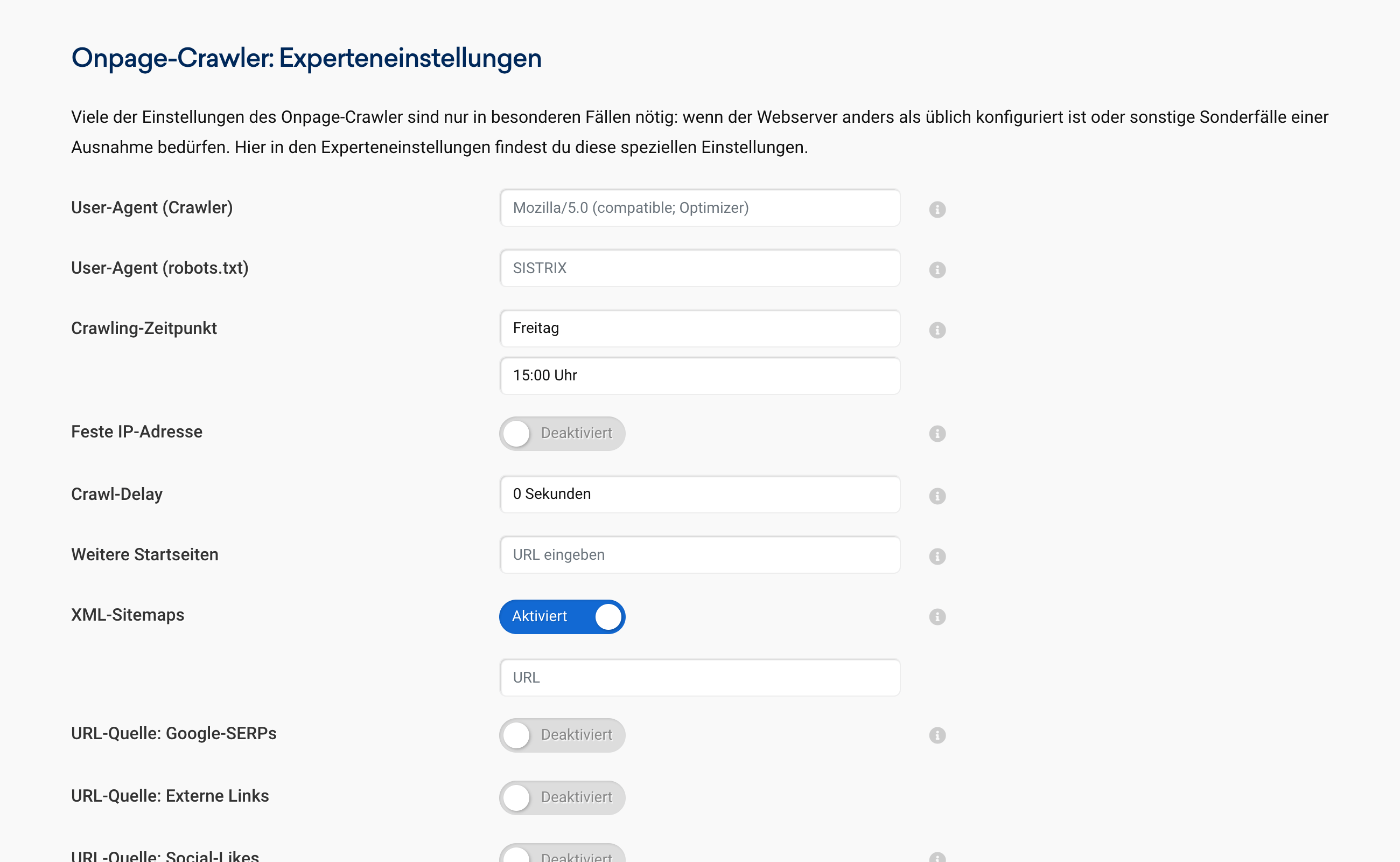 Die Zugriffe des Onpage-Crawlers finden immer über eine IP-Adresse statt, deren Reverse-DNS-Eintrag auf *.crawler.sistrix.net auflöst. So kannst du sicherstellen, dass diese Zugriffe auch wirklich von uns kommen und niemand unseren User-Agent missbraucht. |
Wo kann ich im Onpage-Projekt den Crawl manuell neu anstoßen? Du kannst im jeweiligen Projekt, oben in der blauen Navigationsleiste, auf den Reiter "Onpage" wechseln, um auf die Projekt-Onpage Information zu gelangen. Dort findet sich der Button "Crawler neu starten", über den man den Crawl auch manuell neu anstoßen kann. |
Kann man in Projekten auch Subdomains oder Verzeichnisse crawlen? Ja, im Onpage-Projekt kannst du nicht nur vollständige Domains mit allen Subdomains (Hostnamen) und Unterverzeichnissen crawlen, sondern auch einzelne Bestandteile. So kann bei der Projekterstellung angegeben werden, ob die Domain (*.sistrix.de/*), eine Subdomain (www.sistrix.de/*) oder ein Verzeichnis (www.sistrix.de/news/*) gecrawled und ausgewertet werden soll. Die Auswahl kann in den Projekt-Einstellungen (Einstellungen -> Projekt) geändert werden. Beachte dabei aber bitte, dass die zuvor erfassten Daten damit häufig nicht mehr für einen Vergleich mit dem aktuellen Crawl herangezogen werden sollten. |
Wie häufig wird ein Onpage-Projekt gecrawlt? Der Crawler des Onpage-Projekts wird in der Regel einmal pro Woche gestartet. Wenn seit dem letzten Durchlauf sieben Tage vergangen sind, startet das System den Crawler automatisch. Es gibt insgesamt vier Optionen für den regelmäßigen Crawl, die du in den Einstellungen deines Projekts findest:
Im Bereich Onpage deines Projekts ist es außerdem möglich, einen sofortigen Crawl durch einen Klick auf den Button "Crawler neu starten" auszulösen, so lange das dein Kontingent an zu crawlenden Seiten zulässt. Den laufenden Crawl kannst du über den Button "Crawler stoppen" anhalten. |
Kann ich einen täglichen Projekt-Sichtbarkeitsindex erstellen? Ja, im Projekt kannst du einen eigenen Sichtbarkeitsindex erstellen, der auf Basis der im Projekt hinterlegten Keywords berechnet und täglich aktualisiert wird. Dafür muss mindestens ein Keyword täglich gecrawled werden. In den Projekt-Einstellungen (Einstellungen -> Projekt) kann diese Option dann aktiviert werden. Wichtig: das tägliche Keywordmonitoring muss mindestens 7 Tage bestehen, bevor diese Option angezeigt wird. |
Wie frage ich tägliche und lokale Keywords im Projekt ab? Wenn du ein eigenes Keyword täglich aktualisieren oder für eine bestimmte Stadt abfragen möchtest, kannst du das im Rahmen eines von die angelegten Projektes machen.
Welche Optionen es dabei gibt, wird in dem Tutorial zum erstellen eines eigenen Sichtbarkeitsindex' besprochen. |
Wieso greift der Projekt-Crawler jede Minute auf meine Seite zu? Eine Funktion des Onpage-Projekts ist eine regelmäßige Überprüfung der Erreichbarkeit Deines Projektes. Dafür rufen wir die Startseite einmal pro Minute auf, um sicherzugehen, dass die Erreichbarkeit durchgehend korrekt gemessen wird. Diese Zugriffe finden mit diesem Useragent statt: 'Mozilla/5.0 (compatible; Optimizer)' In den Projekt-Einstellungen (Projekt-Management > Crawler) kannst Du diese minütliche Überprüfung für jedes Projekt getrennt abschalten. Entferne dafür den Haken bei „Minütliche Erreichbarkeitschecks“ am Ende der Seite. |
Wie funktionieren die Tags im Onpage-Projekt? Mit Hilfe der Tags kannst du Keywords sortieren und ordnen. Tags funktionieren dabei wie flexible Ordner: Du kannst einem Keyword mehrere Tags zuordnen und die Auswertungen im Projekt anschließend auf Basis dieser Tag-Sammlungen vornehmen. Für alle Tags werden zusätzlich Tag-Sichtbarkeitswerte erstellt. Die Anzahl der möglichen Tags je Projekt richtet sich nach der Anzahl der Keywords in diesem Projekt. Die Staffelung ist wie folgt: 1 bis 100 Keywords: 25 Tags
101 bis 500 Keywords: 50 Tags
501 bis 1.000 Keywords: 100 Tags
1.001 bis 2.500 Keywords: 250 Tags
Mehr als 2.500 Keywords: 500 Tags |
Welche IP-Adresse nutzt der Onpage-Crawler Im Normalfall nutzt der Onpage Crawler einen Pool an verfügbaren Servern und damit auch IP-Adressen um das Crawling aller Projekte möglichst schnell und effizient durchzuführen. So wird der jeweils nächste, verfügbare Crawling-Slot genutzt. Es ist jedoch möglich, in den Einstellungen des jeweiligen Projektes die Nutzung einer festen IP-Adresse zu aktivieren. Öffne dafür im jeweiligen Projekt die "Einstellungen", dort findest du unter "Onpage-Crawler: Experteneinstellungen" den Punkt "Feste IP-Adresse". Der Crawler wird künftig die IP-Adresse nutzen, die unterhalb der Option angegeben ist. |
Welche Länder und Sprachen unterstützt das Rank-Tracking im Projekt? Das individuelle Keyword-Tracking unterstützt derzeit folgende Länder/Sprach-Kombinationen:
|