
Eine Fehlerseite mit dem Hinweis 404 not found signalisiert, dass eine angeforderte Webseite unter der eingegebenen URL nicht (mehr) existiert. Das ist in vielen Fällen gar kein Problem, sofern eine Seite ganz bewusst gelöscht wurde. Doch es gibt auch Fallstricke.
- Warum entsteht ein 404-Fehler?
- Die Rolle von 404 HTTP-Statuscodes
- Wie setzt man eine 404-Fehlerseite korrekt auf?
- .htaccess- und Apache-Webserver-Fehlerseite konfigurieren
- Fehlerseite in Nginx einrichten
- WordPress CMS - Fehlerseite richtig konfigurieren
- Wann sind 301-Weiterleitungen statt 404 sinnvoll?
- Soft-404-Fehler: Warum sie vermieden werden sollten
- Automatische 404-Fehleranalyse und -Behebung mit SISTRIX
- Best Practices für eine benutzerfreundliche 404-Seite
- Warum 404-Fehler regelmäßig überwacht werden sollten
- Fazit: 404-Fehler gezielt vermeiden und effizient beheben
Wenn eine URL in den Browser eingegeben wird, sendet dieser eine Anfrage an den Server. Ist die Seite nicht mehr vorhanden oder wurde nie erstellt, gibt der Server als Antwort den HTTP-Statuscode 404 zurück. Dieser Statuscode dient der Kommunikation zwischen Client und Server.
404-Fehler sind für Suchmaschinen kein Problem, solange sie korrekt behandelt werden. Problematisch wird es, wenn wichtige Seiten plötzlich nicht mehr erreichbar sind oder fehlerhafte Statuscodes genutzt werden. Google interpretiert eine hohe Anzahl an 404-Fehlermeldungen als Zeichen mangelnder SEO Hygiene, was sich negativ auf das Ranking auswirken kann. Zudem sind Nutzer frustriert, wenn sie nicht das finden, wonach sie gesucht haben, und verlassen die Seite schneller als gewöhnlich. Das kann zu einer höheren Absprungrate führen, die wiederum ein schlechtes Signal für Suchmaschinen darstellt.
Warum entsteht ein 404-Fehler?
Die Ursachen für einen 404-Fehler sind vielfältig und nicht immer ein Problem. Die häufigsten Gründe sind:
- Die Seite wurde gelöscht oder umbenannt undr es wurde keine Weiterleitung eingerichtet.
- Ein externer Link verweist auf eine nicht mehr existierende Seite.
- Ein interner Link enthält einen Tippfehler oder verweist auf eine nicht mehr existierende Seite
- Der Nutzer gibt eine falsche URL ein.
- Die Domain existiert nicht mehr oder es gibt ein Problem mit der DNS-Auflösung.
Problematisch sind sogenannte Soft-404-Fehler. Dabei lädt eine Seite zwar technisch korrekt, gibt aber trotzdem einen Statuscode 200 („OK“) zurück, obwohl sie keinen relevanten Inhalt mehr hat. Dies kann für Suchmaschinen verwirrend sein, da die Seite weiterhin indexiert bleibt, obwohl sie keine sinnvollen Informationen bietet. Suchmaschinen könnten solche Seiten als minderwertig einstufen, was die gesamte SEO-Leistung einer Website negativ beeinflussen kann.
Die Rolle von 404 HTTP-Statuscodes
HTTP-Statuscodes sind essenziell für die Kommunikation zwischen Client und Server. Sie sind in fünf Kategorien unterteilt:
- 1XX – Information: Die Anfrage wird verarbeitet.
- 2XX – Erfolg: Die Anfrage war erfolgreich, z. B. 200 (OK).
- 3XX – Weiterleitung: Die Ressource wurde verschoben, z. B. 301 (Permanent Redirect).
- 4XX – Client-Fehler: Der Nutzer hat eine fehlerhafte Anfrage gestellt, z. B. 404 (Seite nicht gefunden).
- 5XX – Server-Fehler: Der Server kann die Anfrage nicht ausführen, z. B. 500 (Internal Server Error).
Fehlende oder fehlerhafte Statuscodes führen dazu, dass Suchmaschinen nicht korrekt erkennen können, ob eine Seite existiert oder nicht. Wird eine nicht mehr existierende Seite mit einem 200-Statuscode ausgeliefert, bleibt sie im Index bestehen, obwohl sie keine relevanten Inhalte mehr hat. Umgekehrt kann eine unpassende Weiterleitung auf die Startseite als Soft-404-Fehler gewertet werden.
Wie setzt man eine 404-Fehlerseite korrekt auf?
Eine korrekte 404-Seite sollte nicht nur optisch ansprechend sein, sondern auch technisch richtig eingerichtet werden. Entscheidend ist, dass sie den Statuscode 404 zurückgibt und nicht auf die Startseite weiterleitet. Dies kann serverseitig konfiguriert werden.
.htaccess- und Apache-Webserver-Fehlerseite konfigurieren
Egal ob eine Website auf .html- oder .php-Dateien setzt oder eine Verzeichnisstruktur nutzt. Eine 404-Fehlerseite wird ertsellt, indem in die .htaccess-Datei folgendes eingetragen wird:
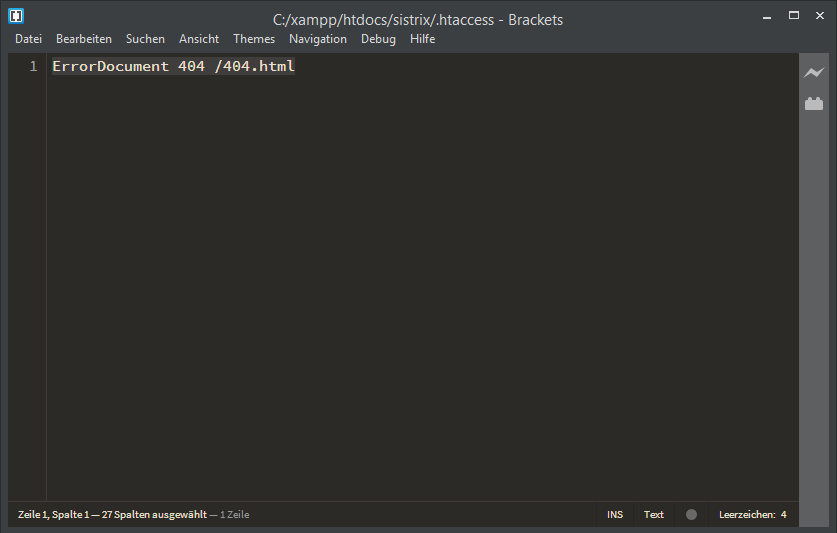
Die .htaccess-Datei muss geöffnet oder erstellt und der relative Pfad zur Fehlerseite eingetragen werden. Die Fehlerseite (z. B. 404.html) sollte zuvor als Datei angelegt werden.
ErrorDocument 404 /404.htmlDie durchzuführenden Schritte im einzelnen:
- eine Fehlerseite (404.html oder 404.php) auf erster Ebene (im Root-Verzeichnis) erstellen
- die .htaccess-Datei öffnen oder erstellen, wenn nicht vorhanden. (Ebenfalls im Root-Verzeichnis)
- „ErrorDocument 404“ muss gefolgt von dem relativen Pfad zur Fehlerseite eingetragen werden.
- Anschließend sollte die Datei gespeichert und eine nicht existierende Seite aufgerufen werden, z. B. http://www.deine-domain.de/beispiel.
- Der Inhalt der Fehlerseite 404.html sollte nun sichtbar sein.
- Zum Abschluss muss hier, geprüft werden, ob der korrekte HTTP-Statuscode 404 zurückgegeben wird.

Fehlerseite in Nginx einrichten
Wenn Nginx genutzt wird, kann eine 404-Fehlerseite eingerichtet werden, indem folgender Eintrag im entsprechenden Server-Block der Config-Datei hinterlegt wird:
error_page 404/404.htmlDie durchzuführenden Schritte unterscheiden sich lediglich durch den Eintrag in der Config-Datei und das Nichtvorhandensein der .htaccess-Datei. Der restliche Workflow bleibt unverändert.
WordPress CMS – Fehlerseite richtig konfigurieren
Wird das Content-Management-System (CMS) WordPress verwendet, ist das Setzen des korrekten HTTP-Statuscodes für die 404-Fehlerseite einfach – vorausgesetzt, das genutzte Theme unterstützt diese Funktion.
Viele WordPress-Themes, Designs oder Templates verfügen über eine entsprechende 404.php-Datei im jeweiligen Theme-Ordner. Ist diese Datei nicht vorhanden, sollte eine Fehlerseite über die .htaccess konfiguriert werden.
Die Datei 404.php im aktiven WordPress-Theme muss geöffnet und folgender Eintrag an erster Stelle eingefügt werden:
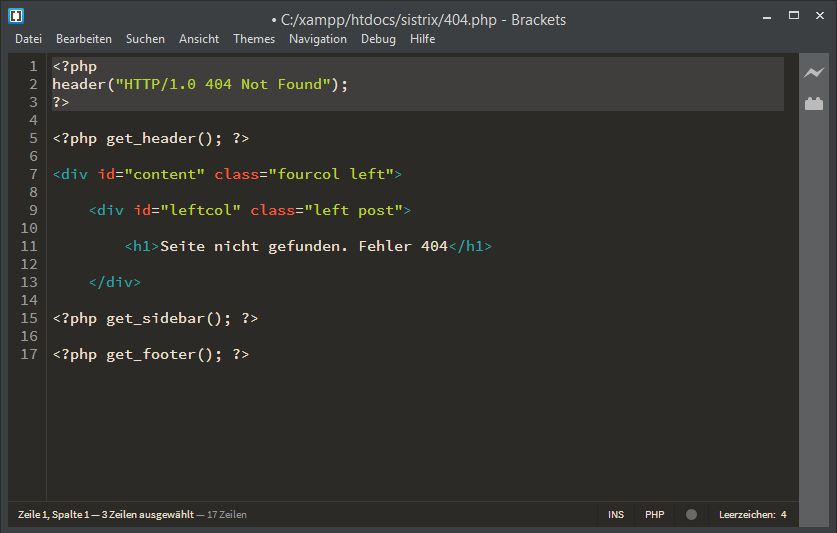
Die Fehlerseite 404.php ist meist im Theme-Verzeichnis unter /wp-content/themes/aktiver-themename/ zu finden.
<?php
header("HTTP/1.0 404 Not Found");
?>Die durchzuführenden Schritte im einzelnen:
- Die Fehlerseite im WordPress-Theme-Ordner muss gefunden und geöffnet werden (meist „404.php“).
- An erster Stelle sollte der oben stehende PHP-Quellcode eingetragen und die Datei gespeichert werden.
- Anschließend sollte eine nicht existierende Seite aufgerufen werden, z. B. http://www.deine-domain.de/beispiel.
- Der Inhalt der Fehlerseite 404.html sollte nun angezeigt werden.
- Zum Abschluss muss hier überprüft werden, ob der korrekte HTTP-Statuscode 404 zurückgegeben wird.
Wann sind 301-Weiterleitungen statt 404 sinnvoll?
Eine 301-Weiterleitung (Permanent Redirect) sollte genutzt werden, wenn der Inhalt einer Seite dauerhaft auf eine andere URL verschoben wurde. Durch eine Weiterleitung kann das Ranking einer URL erhalten werden. Ein Redirect entspricht einem Nachsendeauftrag, mit dem Suchmaschinen die neue Adresse eines Inhalts mitgeteilt wird. . Beispiele für sinnvolle Weiterleitungen:
- Ein Produkt in einem Onlineshop ist nicht mehr verfügbar, aber es gibt ein Nachfolgemodell.
- Ein Blog-Artikel wurde aktualisiert und unter einer neuen URL veröffentlicht.
- Die Seitenstruktur wurde verändert, z. B. von /blog/artikel-xyz zu /artikel/artikel-xyz.
301 Weiterleitungen sorgen dafür, dass in Suchmaschinen das Ranking der alten URL erhalten und von Nutzen gefunden werden kann. . Wird eine Weiterleitung jedoch missbräuchlich eingesetzt – etwa wenn alle nicht gefundenen Seiten auf die Startseite umgeleitet werden – kann Google dies als Soft-404-Fehler bewerten. Eine Weiterleitung auf eine Seite, die nichts mit dem ursprünglichen Inhalt zu tun hat, bringt keine Vorteile.
Soft-404-Fehler: Warum sie vermieden werden sollten
Soft-404-Fehler entstehen, wenn eine Seite eigentlich nicht existiert, aber trotzdem einen „200 OK“-Status zurückgibt oder auf eine irrelevante Seite weitergeleitet wird. Das kann dazu führen, dass Google die Seite weiterhin indexiert, obwohl sie keine sinnvollen Inhalte mehr bietet.
Wie erkennt man Soft-404-Fehler?
- Google Search Console meldet Soft-404-Fehler unter „Indexierung > Seiten“.
- Die URL liefert einen 200-Statuscode, obwohl sie keinen Inhalt hat.
- Eine nicht existierende URL wird auf eine irrelevante Seite weitergeleitet.
Lösung: Die fehlerhafte Seite sollte einen echten 404- oder 410-Statuscode zurückgeben.
Ein 410 („Gone“) ist eine Alternative zu 404, wenn klar ist, dass eine Seite endgültig gelöscht wurde. Während 404 Google signalisiert, dass die Seite möglicherweise zurückkehren könnte, zeigt 410 an, dass sie dauerhaft entfernt wurde.
Automatische 404-Fehleranalyse und -Behebung mit SISTRIX
404-Fehler gehören zum Internet dazu, doch wenn sie nicht regelmäßig überprüft werden, können sie sich negativ auf SEO und die Nutzererfahrung auswirken. Mit den OnPage-Projekten von SISTRIX lassen sich 404-Fehler systematisch erkennen und priorisieren, sodass sie gezielt im eigenen CMS oder mit Weiterleitungen korrigiert werden können.
🔍 Was kann die SISTRIX OnPage-Analyse?
✅ Technische Fehler erkennen – Von 404-Fehlern bis zu Server-Problemen: Die Analyse deckt kritische Fehler auf, die sich direkt auf die Erreichbarkeit und Indexierung der Website auswirken.
✅ SEO-relevante Warnungen aufzeigen – Fehlende Meta-Descriptions, doppelte H1-Überschriften oder zu lange Title-Tags: Die Analyse hilft, Optimierungspotenziale zu identifizieren und Content-strategisch zu verbessern.
✅ Zusätzliche Hinweise geben – Von tief verschachtelten Seiten bis zu JavaScript-Ressourcen: Auch weniger kritische, aber dennoch wertvolle Hinweise zur Verbesserung der Nutzererfahrung werden erfasst.
✅ Behobene Probleme nachverfolgen – Alle zwischen zwei Crawls gelösten Probleme werden transparent in der Übersicht dargestellt.
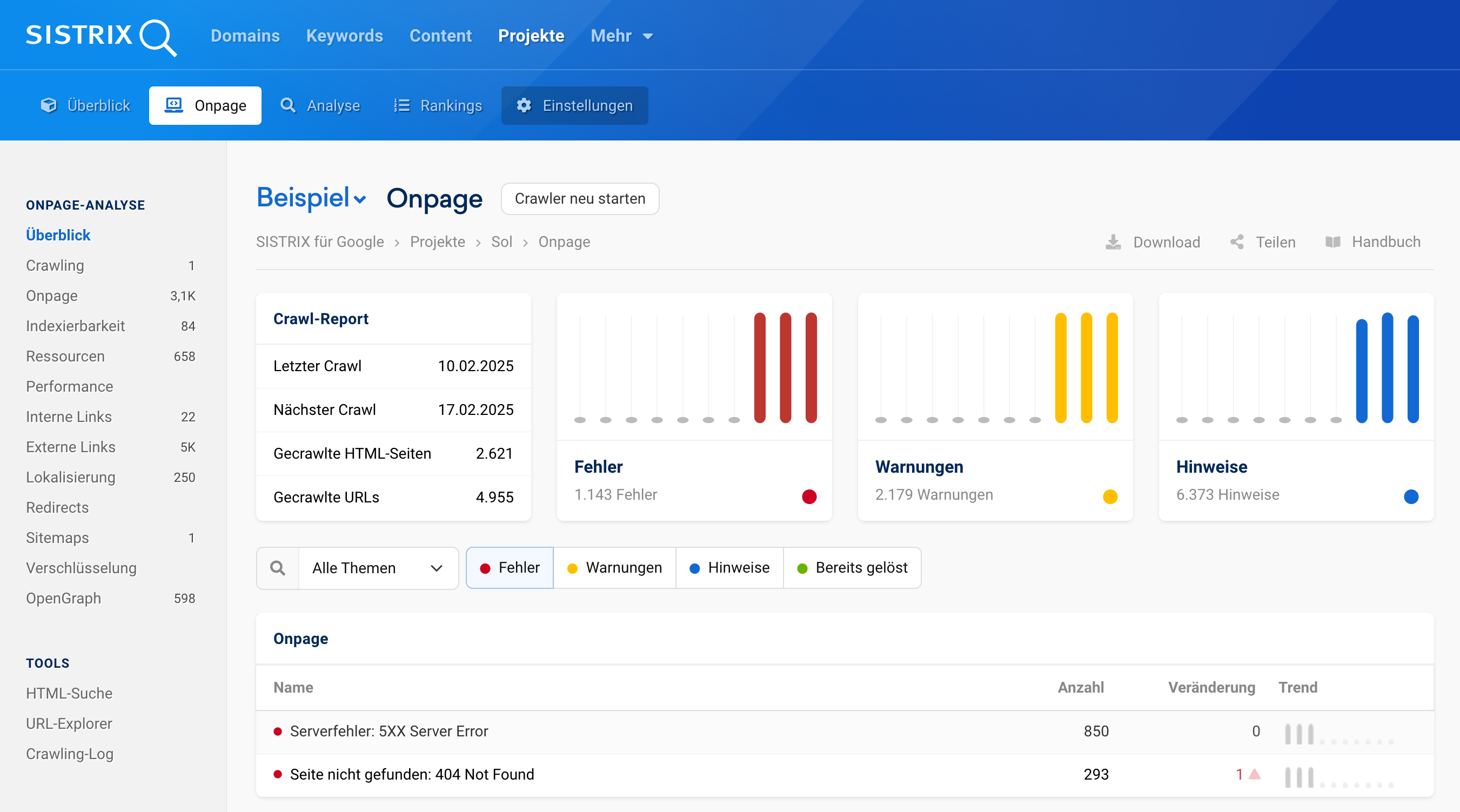
Durch eine kontinuierliche Überwachung lassen sich 404-Fehler schnell erkennen, anstatt erst auf Nutzerbeschwerden oder Rankingverluste zu reagieren. Besonders hilfreich ist die detaillierte Analyse defekter interner Links: Website-Betreiber können basierend auf den Daten gezielt in ihrem CMS oder über die Server-Konfiguration Korrekturen vornehmen.
Auch externe Links, die ins Leere führen, lassen sich in der Analyse leicht identifizieren. So können Betreiber entscheiden, ob die Verlinkungen aktualisiert oder entfernt werden sollten.
Teste es selbst: Jetzt einen kostenlosen 14-Tage-SISTRIX-Account erstellen und alle Funktionen ausprobieren!
Best Practices für eine benutzerfreundliche 404-Seite
Eine gut gestaltete 404-Seite hilft Nutzern, sich trotzdem auf der Website zurechtzufinden. Sie sollte enthalten:
✅ Eine klare Fehlernachricht, die erklärt, dass die Seite nicht gefunden wurde.
✅ Eine Suchfunktion, um alternative Inhalte zu finden.
✅ Verlinkungen zu wichtigen Kategorien oder beliebten Seiten.
✅ Ein freundliches Design, das den Nutzer nicht frustriert.
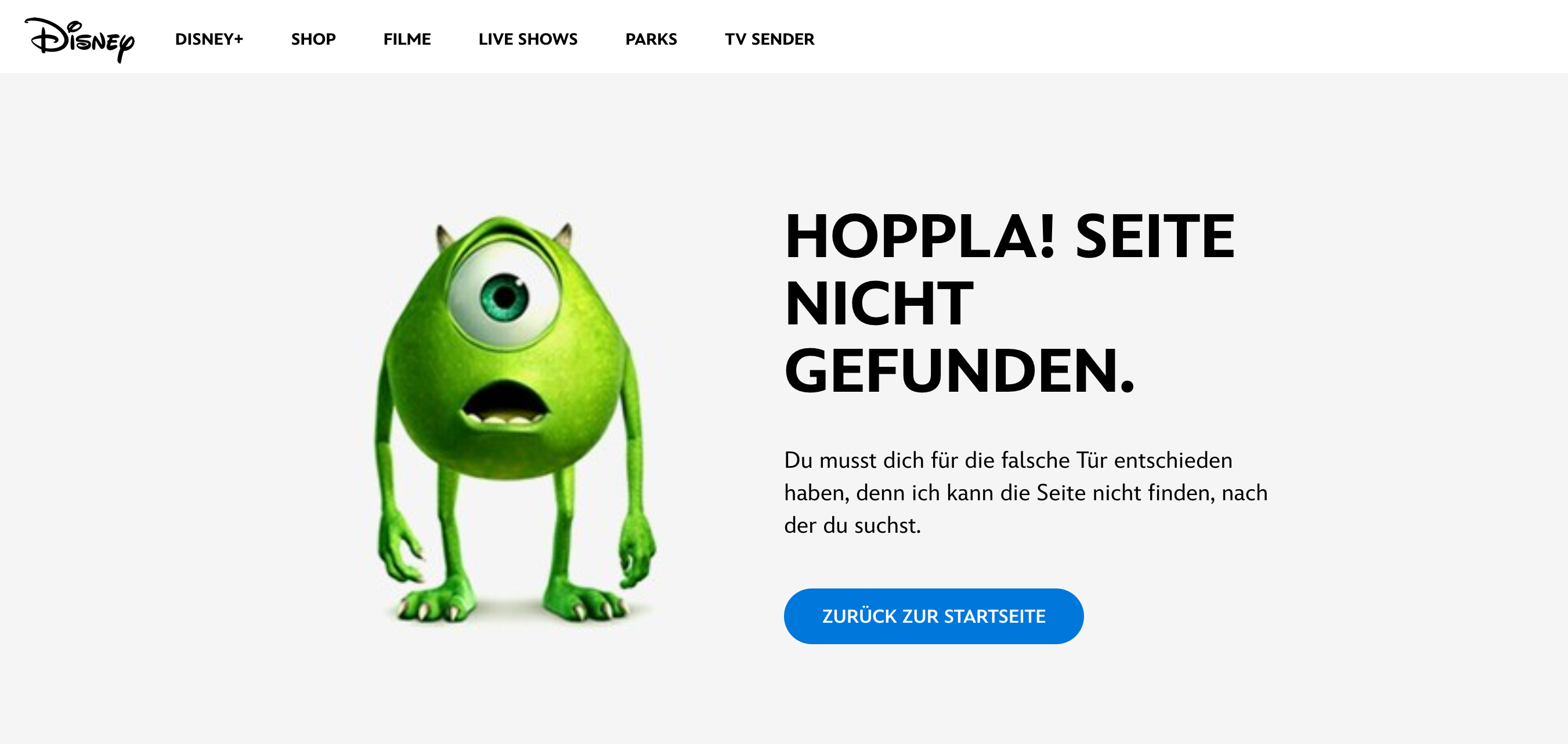
Viele Unternehmen setzen auf kreative 404-Seiten mit witzigen Illustrationen oder interaktiven Elementen, um die Enttäuschung abzumildern. Dies verbessert das Nutzererlebnis und verringert die Absprungrate.
Warum 404-Fehler regelmäßig überwacht werden sollten
Viele Website-Betreiber merken erst durch Nutzerbeschwerden oder sinkende Rankings, dass ihre Seite viele 404-Fehler hat. Eine regelmäßige Kontrolle spart nicht nur Zeit, sondern hilft, SEO-Probleme zu verhindern.
📌 Empfohlene Maßnahmen:
- Automatische Crawls durchführen, um fehlerhafte Links zu erkennen.
- 404-Berichte in der Google Search Console regelmäßig prüfen.
- Interne Verlinkungen manuell oder mit Tools überwachen.
- Nicht mehr relevante Seiten gezielt mit 410 kennzeichnen.
Ein strukturiertes Monitoring sorgt dafür, dass fehlerhafte Links rechtzeitig erkannt und korrigiert werden.
Fazit: 404-Fehler gezielt vermeiden und effizient beheben
404-Fehler gehören zum Internet dazu, aber sie sollten nicht ignoriert werden. Eine hohe Anzahl nicht gefundener Seiten kann sowohl Nutzer als auch Suchmaschinen negativ beeinflussen. Eine gut konfigurierte 404-Seite, kombiniert mit einem konsequenten Monitoring, sorgt dafür, dass der Schaden begrenzt bleibt.
Die wichtigsten Maßnahmen:
✅ Defekte Links vermeiden und regelmäßig prüfen
✅ Sinnvolle 301-Weiterleitungen setzen, aber nicht übertreiben
✅ Soft-404-Fehler durch korrekte Statuscodes verhindern
✅ Benutzerfreundliche 404-Seiten gestalten
Was sagt Google?
Unabhängig davon, wie schön und nützlich Ihre benutzerdefinierte 404-Seite auch sein mag – Sie möchten wahrscheinlich nicht, dass sie in den Google-Suchergebnissen angezeigt wird. Um die Indexierung von 404-Seiten durch Google und andere Suchmaschinen zu unterbinden, stellen Sie sicher, dass Ihr Webserver tatsächlich einen 404-HTTP-Statuscode ausgibt, wenn eine nicht existierende Seite aufgerufen wird.
Quelle: Search-Console-Hilfe
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten