
Die robots.txt-Datei ist ein wichtiges Werkzeug in der Suchmaschinenoptimierung, das häufig unterschätzt wird. Richtig eingesetzt, hilft sie dabei, Suchmaschinen gezielt durch eine Website zu führen – falsch konfiguriert, kann sie dagegen wertvollen Traffic kosten.
Kurzüberblick: robots.txt Crawler effektiv steuern
Die robots.txt-Datei steuert, welche Teile einer Website von Suchmaschinen gecrawlt werden dürfen. Sie liegt im Stammverzeichnis (z. B. www.deine-domain.de/robots.txt) und hilft, das Crawling-Budget sinnvoll zu nutzen.
Typischer Aufbau:
Eine robots.txt besteht aus Anweisungen für bestimmte Crawler:
User-agent: * Disallow: /admin/ Allow: /admin/login/ Sitemap: https://www.deine-domain.de/sitemap.xml
User-agent: Für welchen Crawler gilt die Regel („*“ = alle)
Disallow: Bereiche, die nicht gecrawlt werden sollen
Allow: Ausnahmen innerhalb gesperrter Bereiche
Sitemap: Hinweis für Suchmaschinen zur schnelleren Indexierung
Aufgaben: Technische Bereiche ausschließen, unnötiges Crawling vermeiden, Sitemap einfügen.
Typische Fehler vermeiden: Keine wichtigen Inhalte blockieren
Was ist die robots.txt?
Die robots.txt ist eine einfache Textdatei, die im Stammverzeichnis einer Website liegt (z.B. www.deine-domain.de/robots.txt). Sie gibt Suchmaschinen sogenannte Crawling-Anweisungen: Also Hinweise, welche Bereiche einer Website durchsucht und indexiert werden dürfen – und welche nicht.
Suchmaschinen wie Google respektieren die Anweisungen in dieser Datei in der Regel, sie sind jedoch nicht verpflichtend. Besonders bei sensiblen Inhalten ist es deshalb wichtig, zusätzlich technische Schutzmechanismen wie Passwörter oder IP-Sperren einzusetzen.
Aufbau und Syntax der robots.txt
Die Datei folgt einem einfachen Aufbau aus User-agent (für welchen Crawler gilt die Anweisung?) und Disallow (was soll nicht gecrawlt werden?). Hier ein Beispiel:
User-agent: *
Disallow: /admin/
Disallow: /login/
- User-agent: * bedeutet, dass die Regel für alle Crawler gilt.
- Disallow: /admin/ verbietet das Crawlen des Verzeichnisses /admin/.
Wird eine Zeile mit Allow: ergänzt, kann gezielt eine Ausnahme innerhalb eines blockierten Bereichs erlaubt werden:
User-agent: Googlebot
Disallow: /shop/
Allow: /shop/produkte/
Was gehört in die robots.txt – und was nicht?
Sinnvolle Inhalte:
- Ausschluss technischer Bereiche: z.B. /wp-admin/, /cgi-bin/
- Schutz vor unnötigem Crawling: Filter-URLs oder Duplicate Content vermeiden
- Hinweis auf Sitemap: Sitemap: https://www.deine-domain.de/sitemap.xml
Gefährlich oder unnötig:
- Ausschluss wichtiger Inhalte: Produktseiten oder Blogartikel sollten nicht ausgeschlossen werden.
- Verstecken sensibler Daten: Diese sollten gar nicht öffentlich erreichbar sein, da robots.txt kein Sicherheitswerkzeug ist.
- Einsatz als Indexierungssteuerung: Crawling verbieten bedeutet nicht automatisch, dass Inhalte nicht indexiert werden – dafür ist das Meta-Robots-Tag zuständig.
SEO: Worauf Du achten solltest
Häufige Fehler:
- Komplettsperrung der Website mit Disallow: / (oft bei Staging-Seiten vergessen)
- Blockieren von Ressourcen (z.B. CSS oder JS), die Google für das Rendern benötigt
- Fehlende Sitemap-Angabe: Erschwert die Indexierung
Best Practices:
- robots.txt regelmäßig prüfen und anpassen
- Mit der Google Search Console testen: Dort zeigt Google an, ob Inhalte fälschlich blockiert werden
- Crawling-Budget effizient nutzen: Unwichtige Seiten ausschließen, wichtige frei zugänglich halten
Weitere Informationen zur Erstellung der robots.txt
robots.txt mit SISTRIX testen
Beim Crawlen wird die robots.txt-Datei einer Website ausgelesen, und die darin enthaltenen Regeln werden beachtet – genau wie es auch beim Googlebot der Fall ist.
Änderungen an der robots.txt können getestet werden, ohne dass sie sofort online gestellt werden müssen. Dafür kann in den Projekteinstellungen eine virtuelle robots.txt hinterlegt werden. Diese wird ausschließlich für den internen Crawler verwendet und ersetzt beim nächsten Crawl die öffentlich zugängliche Version. Neue Regeln können auf diese Weise risikofrei überprüft werden – ganz ohne Auswirkungen auf echte Suchmaschinen.
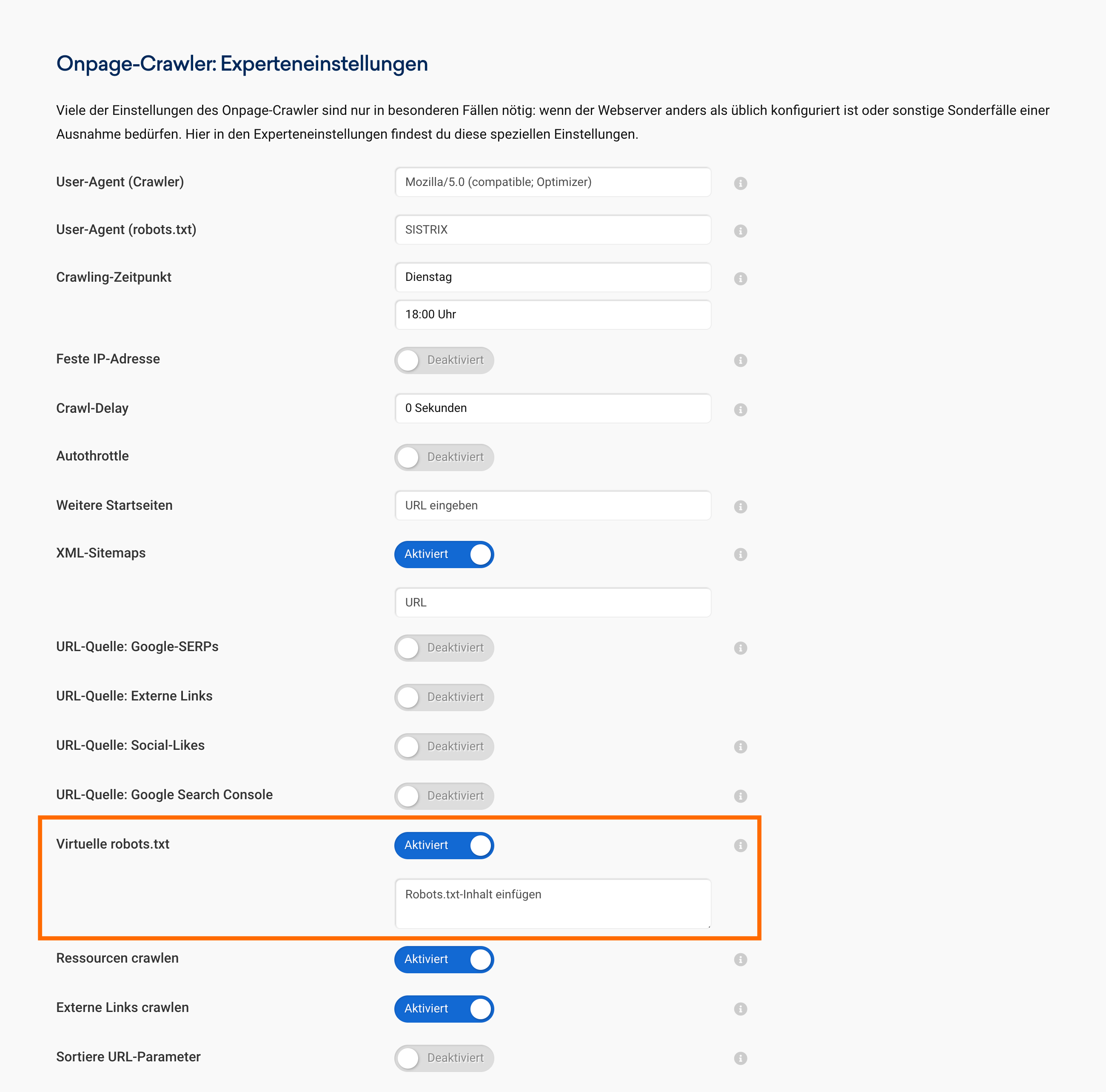
Teste SISTRIX 14 Tage kostenlos und überprüfe, ob deine robots.txt richtig greift – öffentlich oder im geschützten Test. Mit der virtuellen robots.txt lassen sich Änderungen risikofrei simulieren, bevor sie live gestellt werden.
Vorlage für eine suchmaschinenfreundliche robots.txt
Das folgende Beispiel zeigt eine robots.txt, die für die meisten Websites funktioniert. Die Pfade müssen individuell angepasst werden.
# Zugriff für alle Crawler erlaubt
User-agent: *
# Verzeichnisse ausschließen, die für Nutzer und Google irrelevant sind
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /cgi-bin/
Disallow: /cart/
Disallow: /checkout/
Disallow: /account/
# Blockiere keine Ressourcen wie CSS oder JS (Google benötigt diese zum Rendern)
# Ausnahme: Wenn Du weißt, dass ein Verzeichnis nur technische Daten enthält, kannst Du es ausschließen
# Crawling von Filter- und Sortier-URLs vermeiden (Beispiel für einen Shop)
Disallow: /*?orderby=
Disallow: /*?filter=
Disallow: /*?add-to-cart=
# Suchergebnisse auf der Seite ausschließen (oft Duplicate Content)
Disallow: /?s=
Disallow: /search/
# Sitemap angeben – hilft Google bei der Indexierung
Sitemap: https://www.deine-domain.de/sitemap.xml
Robots.txt überprüfen
1. Google Search Console: „robots.txt-Tester“
So funktioniert’s:
- Melde Dich in der Google Search Console an.
- Wähle die entsprechende Property (Deine Website) aus.
- Gehe zu Alte Tools und Berichte > robots.txt-Tester (Hinweis: Google stellt dieses Tool nach und nach ein, je nach Property noch verfügbar).
- Lade Deine aktuelle oder geplante robots.txt hoch bzw. füge sie ein.
- Teste einzelne URLs: Google zeigt an, ob sie blockiert werden oder zugänglich sind.
2. Lokaler Test im Browser
- Rufe www.deine-domain.de/robots.txt auf.
- Kontrolliere, ob die Datei korrekt geladen wird.
- Achte auf fehlerfreie Syntax und keine ungewollten „Disallow“-Einträge.
Tipp: Vorschau statt Risiko
Wenn Du Dir unsicher bist, lade Deine geänderte robots.txt-Datei noch nicht live hoch. Nutze stattdessen die Testmöglichkeiten – besonders bei Seiten mit viel Traffic oder sensiblen Inhalten.
Robots.txt und KI-Crawler
Kann man Inhalte per robots.txt vor Scraping durch KI-Tools schützen?
Viele KI-Tools, insbesondere große Sprachmodelle wie ChatGPT, Google Gemini oder Claude, nutzen Webcrawler, um öffentlich zugängliche Inhalte zu sammeln. Diese Crawler – z.B. GPTBot (OpenAI), CCBot (Common Crawl) oder Google-Extended – respektieren laut eigenen Angaben die Anweisungen in der robots.txt.
Beispielhafte Anweisung zum Blockieren dieser Crawler:
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Google-Extended
Disallow: /Wichtig zu wissen:
- Nur Crawler, die sich an die robots.txt halten, werden Deine Inhalte nicht abrufen.
- Illegitime Scraper oder Bots, die sich nicht an Standards halten, ignorieren die Datei einfach.
- Die robots.txt ist daher kein absoluter Schutz gegen Scraping, sondern eher ein „opt-out“-Signal als rechtliche Absicherung.
Gängige Empfehlung:
- Wenn Du nicht möchtest, dass Deine Inhalte für das Training von KI-Modellen verwendet werden, solltest Du relevante Crawler aktiv blockieren.
- Zusätzlich kann es sinnvoll sein, Server-Schutzmaßnahmen zu implementieren (z.B. Bot-Management oder IP-Sperren).
- Rechtlich bleibt das Thema umstritten. Einige Unternehmen ergänzen ihre Nutzungsbedingungen, um die Verwendung ihrer Inhalte durch KI-Modelle zu untersagen.
Was sagt OpenAI zur robots.txt?
OpenAI gibt Website-Betreibern die Möglichkeit, gezielt zu steuern, wie ihre Inhalte durch verschiedene OpenAI-Crawler genutzt werden dürfen. Die Steuerung erfolgt über die robots.txt – jedoch unterscheidet OpenAI dabei zwischen unterschiedlichen Crawlern, je nach Zweck.
Hier ein Überblick:
| User Agent | Verwendung durch OpenAI |
|---|---|
| GPTBot | Wird eingesetzt, um Inhalte für das Training von generativen KI-Modellen (z.B. ChatGPT) zu crawlen. Disallow in der robots.txt signalisiert, dass Inhalte nicht für Trainingszwecke genutzt werden dürfen. |
| OAI-SearchBot | Dient dazu, Websites in den Suchfunktionen von ChatGPT anzuzeigen (z.B. via Bing Search Integration). Wird nicht für KI-Training verwendet. OpenAI empfiehlt, diesen Crawler zuzulassen, wenn man in ChatGPT-Suchergebnissen erscheinen möchte. |
| ChatGPT-User | Wird eingesetzt, wenn ein Nutzer in ChatGPT eine Webseite besucht (z.B. über Plugins, Custom GPTs oder GPT Actions). Kein automatischer Crawler, keine Datennutzung für KI-Training. Diese Zugriffe beruhen auf konkreten Nutzeraktionen. |
Beispielhafte robots.txt zur Steuerung von OpenAI-Crawlern:
# Verhindere, dass Inhalte für KI-Training verwendet werden
User-agent: GPTBot
Disallow: /
# Erlaube, in ChatGPT-Suchergebnissen aufzutauchen
User-agent: OAI-SearchBot
Allow: /
# Nutzeraktionen über ChatGPT-User nicht blockieren (optional)
User-agent: ChatGPT-User
Allow: /Quelle: https://platform.openai.com/docs/bots
FAQ zur robots.txt
Wie kann ich die robots.txt-Datei aufrufen?
Einfach in den Browser www.deine-domain.de/robots.txt eingeben.
Ist robots.txt gut für SEO?
Ja, wenn sie hilft, Crawling-Ressourcen effizient zu nutzen und irrelevante Inhalte auszuschließen.
Wie finde ich die robots.txt in WordPress?
Viele Hoster generieren sie automatisch. Mit Plugins wie Yoast SEO oder Rank Math kannst Du sie anpassen.
Wie behebe ich „Blocked by robots.txt“ in WordPress?
In der Search Console prüfen, welche URLs betroffen sind. Danach robots.txt bearbeiten und den Disallow-Eintrag entfernen.
Sollte ich robots.txt oder Meta-Tag verwenden?
Für Crawling-Kontrolle: robots.txt. Für Indexierung: Meta Robots Tag (z.B. noindex).
Was ist ein robots.txt Generator?
Ein Tool zur Erstellung von robots.txt-Dateien ohne manuelles Schreiben – ideal für Einsteiger.
Ignoriert Google die robots.txt?
Nein, Google hält sich in der Regel daran – es sei denn, es handelt sich um besonders schützenswerte Inhalte (z.B. rechtlich relevante Daten).
Wie füge ich sitemap.xml in robots.txt ein?
Einfach am Ende der Datei einfügen: Sitemap: https://www.deine-domain.de/sitemap.xml
Wie füge ich sitemap.xml und robots.txt in WordPress hinzu?
Mit Plugins wie Yoast SEO oder Rank Math kannst Du beides bequem konfigurieren – inkl. automatischer Sitemap-Erstellung.
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten