
Gerade haben wir uns daran gewöhnt, dass SEO neben der obligatorischen Auflistung aller Meta-Keywords auch noch aus Linkbuilding besteht, dreht sich die Welt weiter und Signale wie das Benutzerverhalten und Social-Media-Daten erobern einen Spitzenplatz in der öffentlichen Wahrnehmung. Als wäre das noch nicht genug, hat Google in Form monatlicher Blogpostings eine unvergleichbare Nebelmaschine geschaffen und schränkt die Sicht auf das Wesentliche damit regelmäßig erneut ein. Daran entspannen sich interessante Diskussionen in zahlreichen Blogs und Netzwerken. Mit diesem Posting möchte ich der Diskussion ein paar Punkte hinzufügen.
Auch, wenn das bei der Flut von neuen Features und Verticals manchmal etwas aus dem Fokus gerät, so ist Google doch weiterhin eine Volltext-Websuchmaschine. Ich möchte jetzt nicht so sehr auf den Grundlagen rumreiten, doch glaube ich, dass sie beim Verstehen von Zusammenhängen sehr helfen können. Der Google-Webcrawler durchsucht weite Teile des öffentlichen Interwebs und baut sich mit den dort gefundenen Worten einen eigenen Index auf. Kommt jetzt ein Ratsuchender vorbei, schlägt Google im ersten Schritt in diesem Index nach, auf welchen Seiten das gesuchte Wort überhaupt vorkommt. Je nach Suchanfrage kann das schon mal eine Liste von einigen Millionen URLs sein. Und erst jetzt, in einem zweiten Schritt, kommt der ominöse Algorithmus, mit dem wir uns tagtäglich beschäftigen, ins Spiel. Anhand einer vermutlich sehr langen Liste von Regeln und Abläufen sortiert Google diese Liste mit den gefundenen URLs und zeigt uns die ersten 10 Treffer an.
Um also überhaupt erst in die Auswahl für den Algorithmus zu kommen, müssen zwei Vorbedingungen erfüllt sein: zum einen muss die Seite von Google erfasst werden und auch im Index landen, zum anderen muss Google sie als relevant für die jeweilige Suche einstufen. Den ersten Punkt erreicht man in der Regel mit einer soliden Seitengestaltung: eine ordentliche Informationsstruktur und eine sinnvolle interne Verlinkung weisen dem Googlecrawler den Weg. Für den zweiten Punkt verlässt Google sich in über 99% aller Fälle auf einen ganz einfachen Indikator: das Wort (oder ein Synonym) ist auf der Seite oder im Titel der Seite zu finden. Und erst danach geht es an das Sortieren und Ranken der URLs. Wie passt jetzt also das Nutzerverhalten sowie Signale aus sozialen Netzwerken in dieses System?
Ich bin mir ziemlich sicher, dass Google diese beiden Signale derzeit nur im letzten Schritt, also beim Sortieren der Ergebnisse einsetzt. Und auch dabei ergeben sich offensichtliche Schwierigkeiten, die derzeit vermutlich verhindern, dass die beiden Punkt einen gewichtigen Stellenwert im Algorithmus einnehmen. Bei dem Nutzerverhalten ist es so, dass die Werte erst dann richtig Spaß machen, wenn sie in Relation zu dem jeweiligen Suchbegriff stehen. Also keine globale Absprungrate für eine Domain, sondern die Absprungrate der einen URL für das eine Keyword. Schaut man sich jetzt die Klickraten in den Google Ergebnissen an, wird schnell deutlich, dass die Nutzung hinter der ersten Seite massiv abnimmt. Google wird dort also nur sehr wenig brauchbare Nutzerdaten sammeln können und je weiter es in den Longtail geht, desto unzureichender wird die Abdeckung. Im Umkehrschluss bedeutet das allerdings, dass dieses Signal zwar dazu genutzt werden kann, ob eine Seite auf Position 3 oder 4 rankt (ReRanking), die grundlegende Entscheidung, ob sie überhaupt in die Top10 oder Top1000 gehört, kann so jedoch nicht getroffen werden.
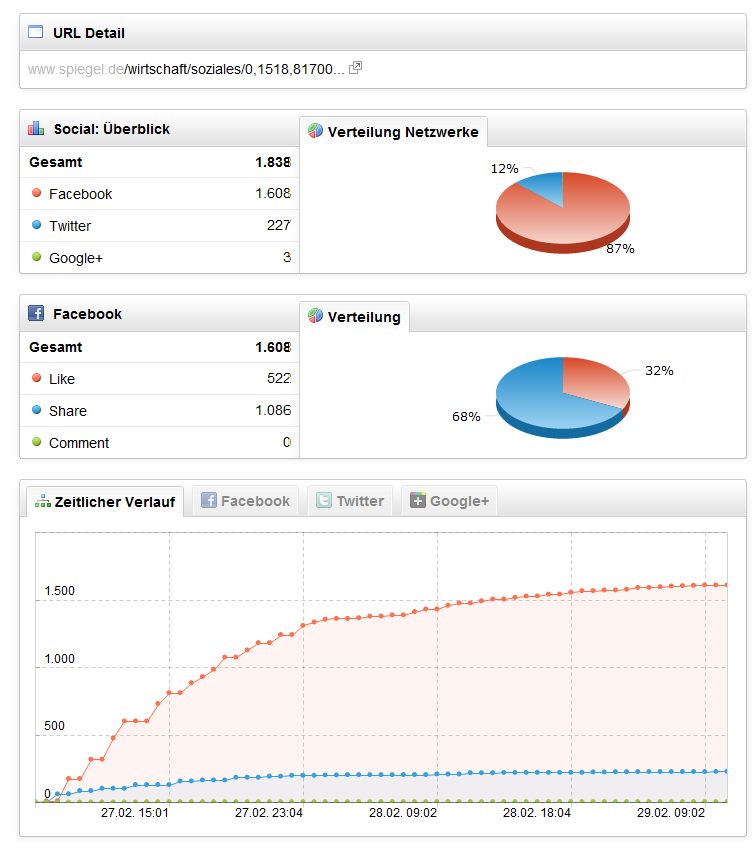
Bei den sozialen Signalen ist die Situation noch etwas verfahrener: Google hat aktuell keine zuverlässige Quelle für diese Daten. Nachdem man den Vertrag mit Twitter über den Komplettbezug aller Tweets gekündigt hat, ist Twitter dazu übergegangen, alle URLs auf den öffentlich erreichbaren Webseiten durch einen eigenen URL-Shortener zu ersetzen und auf Nofollow gesetzt. Und auch das Verhältnis zwischen Facebook und Google ist nicht unbedingt als so gut zu beschreiben, dass Facebook dem Wettbewerber die nötigen Daten frei Haus liefert. Bleibt also Google+ als mögliche Datenquelle. Wir erheben die Signale für URLs ja bereits seit einiger Zeit und können dort aktuell keinen Trend erkennen, dass die Nutzung von Google+ zunimmt. Ein neuer Artikel von Spiegel Online hat beispielsweise 1.608 Erwähnungen bei Facebook, 227 Tweets und ganze 3 Google+-Votes. Nicht gerade das, was man als eine solide Basis für einen grundlegenden Teil des Algorithmus, der hinter der 95%-Einnahmequelle einer börsennotierten Firma steht, nennen kann. Wie kann man jetzt also den Einfluss dieser Rankingsignale auf den Google-Algorithmus bestimmen? Sobald Google öffentlich davor warnt, diese Signale nicht zu manipulieren, ist es an der Zeit, sich weitere Gedanken zu machen …
{kind=link}