
Fast keine Woche vergeht derzeit, ohne dass Googles Umgang mit der eigenen Marktmacht beklagt wird. Dirk Lewandowski, Professor an der Haw Hamburg, hat nun einen öffentlichen Web-Index als Alternative zu Google vorgeschlagen. Kann das funktionieren?
Google selbst ist aktuell häufiger Gegenstand der Berichterstattung in Google News als es der Suchmaschine recht sein dürfte. Alleine in den letzten Tagen ging es zum Beispiel darum, dass die VG Media auf Basis des neuen Leistungsschutzrechtes schon mal 1,24 Milliarden Euro von Google fordert, Google auf Druck der EU-Kommission in Android bald Alternativen zur Google Suche und zu Chrome vorschlagen muss und auch die Klage über 500 Millionen Euro von Idealo ist noch recht frisch.
Vor diesem Hintergrund, hat Dirk Lewandowski, Professor für Information Research & Information Retrieval an der Haw Hamburg und einer der “Suchmaschinen Professoren” Europas den Vorschlag (PDF-Version) gemacht, die einzelnen Teile einer Suchmaschine getrennt zu betreiben:
A proposal for building an index of the Web that separates the infrastructure part of the search engine – the index – from the services part that will form the basis for myriad search engines and other services utilizing Web data on top of a public infrastructure open to everyone.
https://arxiv.org/abs/1903.03846
Als Kernproblem sieht er, dass bei der Gestaltung eines Ranking-Algorithmus auch immer das Weltbild der Ersteller zum Tragen kommt – und damit wirklich neutrale und unvoreingenommene Ergebnisse nicht gegeben sind. Dies werde durch über 90 Prozent Marktanteil von Google in Europa zu einem Problem.
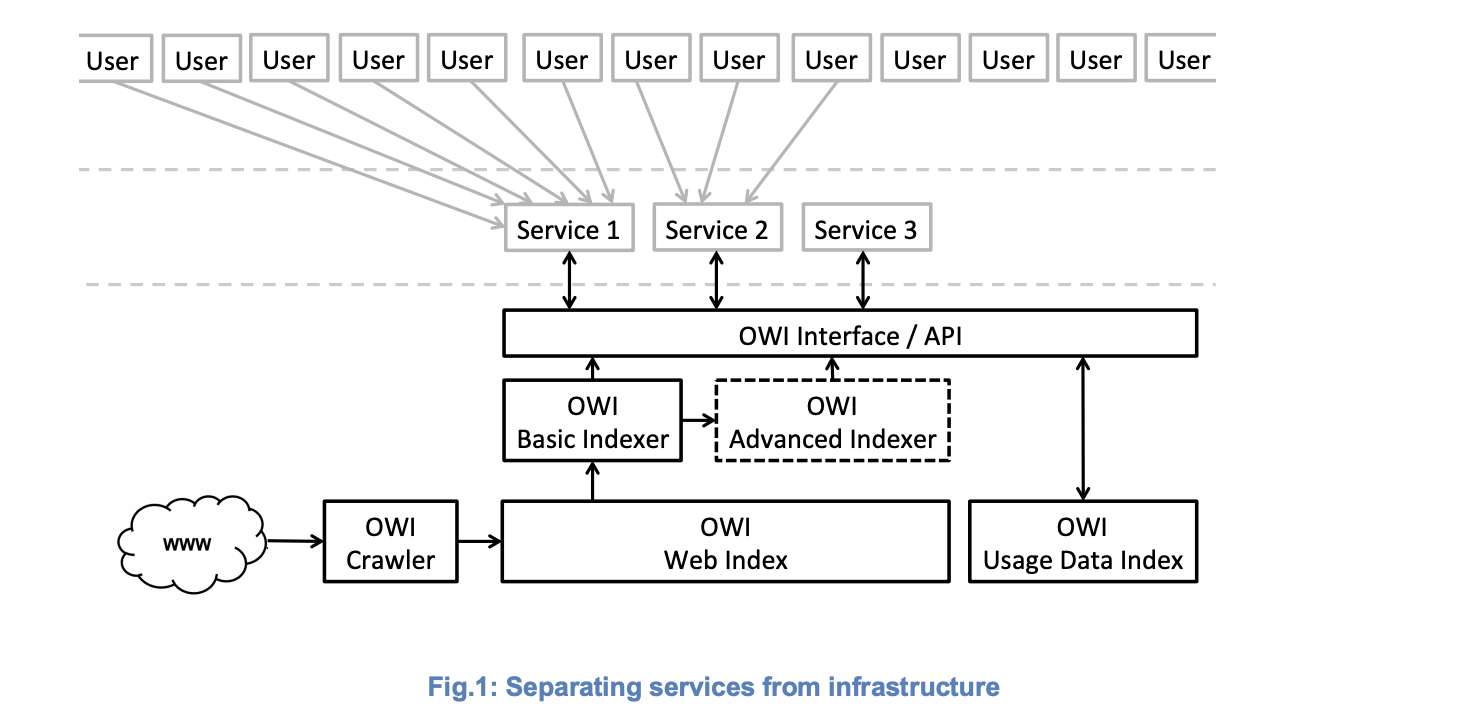
Die Lösung: Trennung von Crawling/Index sowie dem Frontend/Algorithmus von Suchmaschinen. Auf Basis einer öffentlichen Infrastruktur sollen eine ganze Reihe von unterschiedlichen Suchanbietern entstehen und dringend notwendige Vielfalt ermöglichen.
Kann das klappen? Ich bin eher skeptisch und zwar aus diesen Gründen:
Google gehört der ganze “Stack”
Google besitzt (im wahrsten Sinne des Wortes) mittlerweile einen großen Teil des Internets. Es geht ganz unten los: Googles öffentlicher und kostenloser DNS-Server ist der meistgenutzte DNS-Server, mit Android gehört Google das mit Abstand erfolgreichste Smartphone-OS, die Marktanteile von Chrome auf dem Desktop erreichen regelmäßig neue Höchststände, neben Google Analytics gibt es keine Wettbewerber mit ernstzunehmendem Marktanteil. Ich könnte diese Liste fast endlos fortführen. Und wenn Google das notwendige Puzzlestück noch nicht gehört, dann wird es – wie bei den Search Deals mit Apple und Firefox – dazu gekauft.
Suche im ML-Zeitalter: die Menge machts
Ob Daten nun das neue Öl oder Gold sind, ist noch nicht abschließend geklärt (nur, dass ich beides nicht mehr hören kann). Klar ist aber: im Kern ist die Aussage richtig. Im Zeitalter von Machine Learning sind Hardware und Software weitgehend öffentlich. Den Unterschied zwischen einem guten und einem schlechten Ergebnis machen die Trainingsdaten, die man für die Erstellung des Algorithmus nutzt. Und hier hat Google einen riesigen Vorsprung: zum einen hat Google, wie oben beschrieben, Zugriff auf weit mehr als nur reine Suchdaten, zum anderen ist das Suchvolumen auch in Longtail-Bereichen bei Google groß genug, um zu sinnvollen Ergebnissen zu kommen. Lewandowski schlägt zwar eine Rückspielung von Nutzerdaten der einzelnen Suchmaschinen in das Gesamtsystem vor. Ob das die strukturellen Nachteile aber ausgleichen kann, wage ich zu bezweifeln.
Wechsel ist schwer
Es gibt Alternativen zu Google. Sogar sehr viele und, objektiv gemessen, auch sehr gute Alternativen. Und trotzdem wollen fast alle die Google Suchergebnisse. Das über die Jahre gewachsene Vertrauen in die Marke Google ist im Suchmarkt so groß, dass es schwer ist, Nutzer von einem Wechsel zu überzeugen. Nutzer wollen lieber Bing-Ergebnisse im Google-Layout als Google-Treffer im Bing-Design. Eine erfolgreiche Alternative muss deutlich besser als Google sein, um einen Wechsel auf eine neue Suchmaschine anzustoßen.
Fazit
Jeder Impuls für mehr Vielfalt in der europäischen Suchmaschinenlandschaft ist hilfreich und willkommen. Die Idee, Crawler und Index als eine Art öffentliche Grundversorgung in Europa bereitzustellen und auf diese Weise für mehr Wettbewerb zu sorgen, ist aus akademischer Sicht nachvollziehbar. Ich bin allerdings skeptisch, dass es im realen Internet funktionieren wird. Aber die EU hat schon viel Kram finanziert, wer weiss und einen Versuch ist es wert.
