
In den USA bestimmt seit Tagen ein ebenso altes wie polarisierendes Thema die SEO-Branche: SERPs in SERPs, also die Indexierung von Suchergebnissen und zusammengescrapten Inhalten durch Google. Das auf der einen Seite Jason Calacanis, der als Betreiber von Mahalo.com im Kreuzfeuer steht, beständig gegen SEO anwettert, gibt der Diskussion erst so richtig Feuer.
Eigentlich ist das Thema durch Google seit Ewigkeiten in den Quality Guidelines abgehandelt, so steht dort:
Verhindern Sie mithilfe der Datei „robots.txt“ das Crawlen von Suchergebnisseiten oder anderen automatisch erstellten Seiten, die keinen großen Wert für Besucher haben, die über eine Suchmaschine auf Ihre Website geleitet wurden.
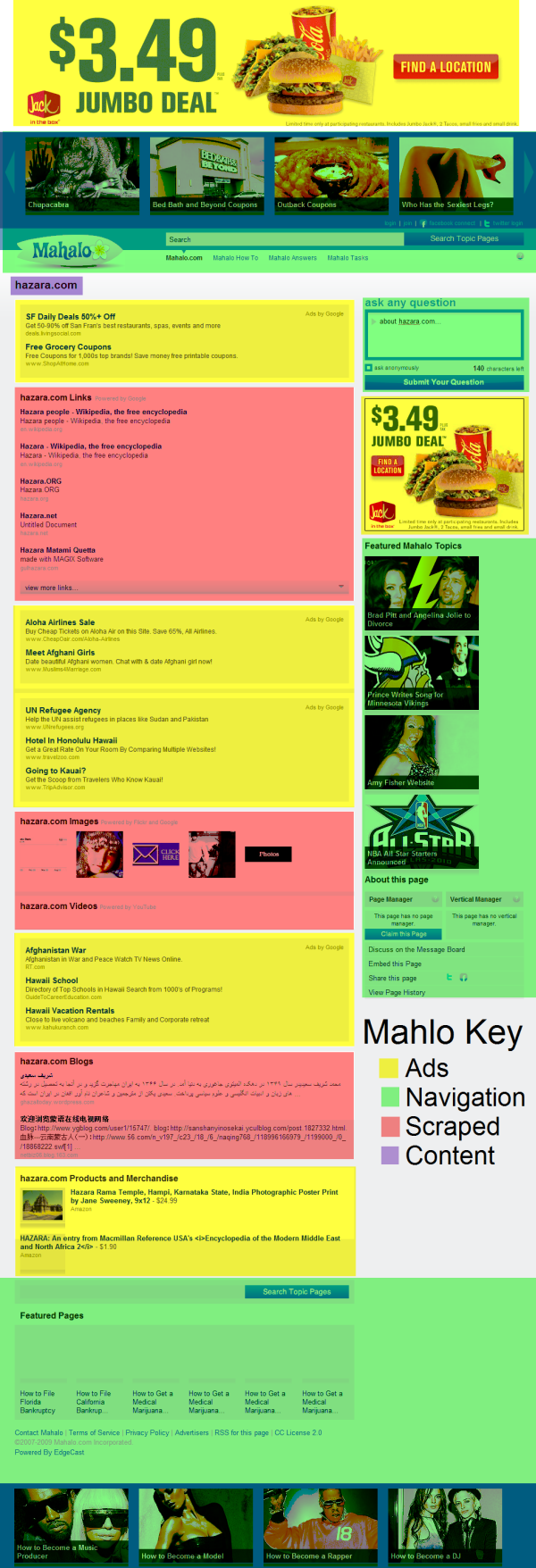 Aber wie so häufig, sind es Details und verschiedene Blickwinkel, die so etwas interessant machen. Mahalo.com bezeichnet sich selber als „Human Search Engine“ und trägt zu einer Reihe von Themen Informationen aus dem Web zusammen und bereitet diese auf. Das Problem ist nun, dass dies – entgegen der Ankündigung – wohl nicht nur manuell geschieht, sondern zahlreiche Seiten auch automatisiert mit zusammen-gespidertem Content erstellt werden. Eigentlich kein klarer Fall für die oben zitierte Richtlinie – leider hält Mahalo sich nicht dran und Google sieht derzeit wohl keinen ausreichenden Grund, einzuschreiten.
Aber wie so häufig, sind es Details und verschiedene Blickwinkel, die so etwas interessant machen. Mahalo.com bezeichnet sich selber als „Human Search Engine“ und trägt zu einer Reihe von Themen Informationen aus dem Web zusammen und bereitet diese auf. Das Problem ist nun, dass dies – entgegen der Ankündigung – wohl nicht nur manuell geschieht, sondern zahlreiche Seiten auch automatisiert mit zusammen-gespidertem Content erstellt werden. Eigentlich kein klarer Fall für die oben zitierte Richtlinie – leider hält Mahalo sich nicht dran und Google sieht derzeit wohl keinen ausreichenden Grund, einzuschreiten.
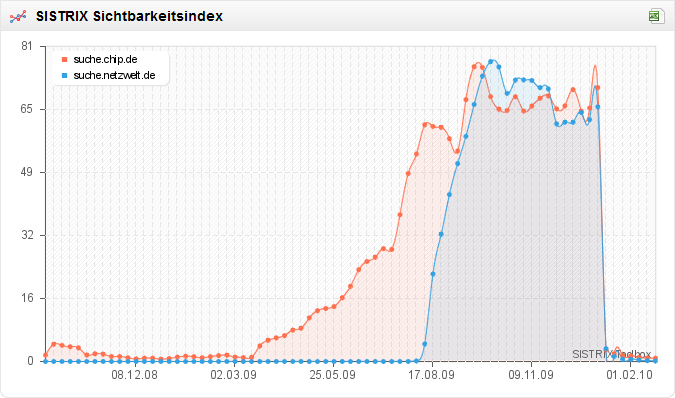 In Deutschland stellt sich die Situation so dar, dass Google in der Regel schneller eingreift und entsprechenden Modellen schnell die „SERP-Liebe“ entzieht: erst vor einige Wochen gab es da mit chip.de und netzwelt.de zwei promintente Beispiele. Die Subdomains mit den Suchergebnissen werden nicht mehr gefunden, die restlichen Seiten der Domain ranken weiterhin gut.
In Deutschland stellt sich die Situation so dar, dass Google in der Regel schneller eingreift und entsprechenden Modellen schnell die „SERP-Liebe“ entzieht: erst vor einige Wochen gab es da mit chip.de und netzwelt.de zwei promintente Beispiele. Die Subdomains mit den Suchergebnissen werden nicht mehr gefunden, die restlichen Seiten der Domain ranken weiterhin gut.
Die Bewertung fällt also nicht ganz einfach: wenn es funktioniert und man mit seinem Konzept auf dem schmalen Grat, den Google so gerade noch toleriert wandert, so kann die teil- oder vollautomatische Erzeugung von Seiten ein interessanter Weg sein, eine Menge Traffic mitzunehmen. Übertreibt man es allerdings oder passt sein Konzept nicht den sich ändernden Gegebenheiten an, so ist es damit schnell vorbei – und eine Garantie, dass die Hauptdomain dabei keinen Schaden nimmt, gibt es nicht.