
Auch wenn mein Jetta fast täglich ein Quell neuer Freude ist und die 1.6 Liter Maschine schnurrt, als sei sie gerade erst gebaut worden, so schaue ich doch ab und an auf die praktischen Autos der VW-Tochtermarke aus Tschechien. Jetzt hat man sich offensichtlich dazu durchgerungen, den reichlich antiquierten Webauftritt zu relaunchen. Mag die neue Seite optisch noch recht gefällig wirken, hat man bei der SEO-Umsetzung eine Reihe von Fehlern gemacht, die ich in diesem Posting gerne beleuchten möchte, auf dass sie nicht von anderen wiederholt werden. Zuerst ein Blick auf den Verlauf des Sichtbarkeitsindexes für die Domain:
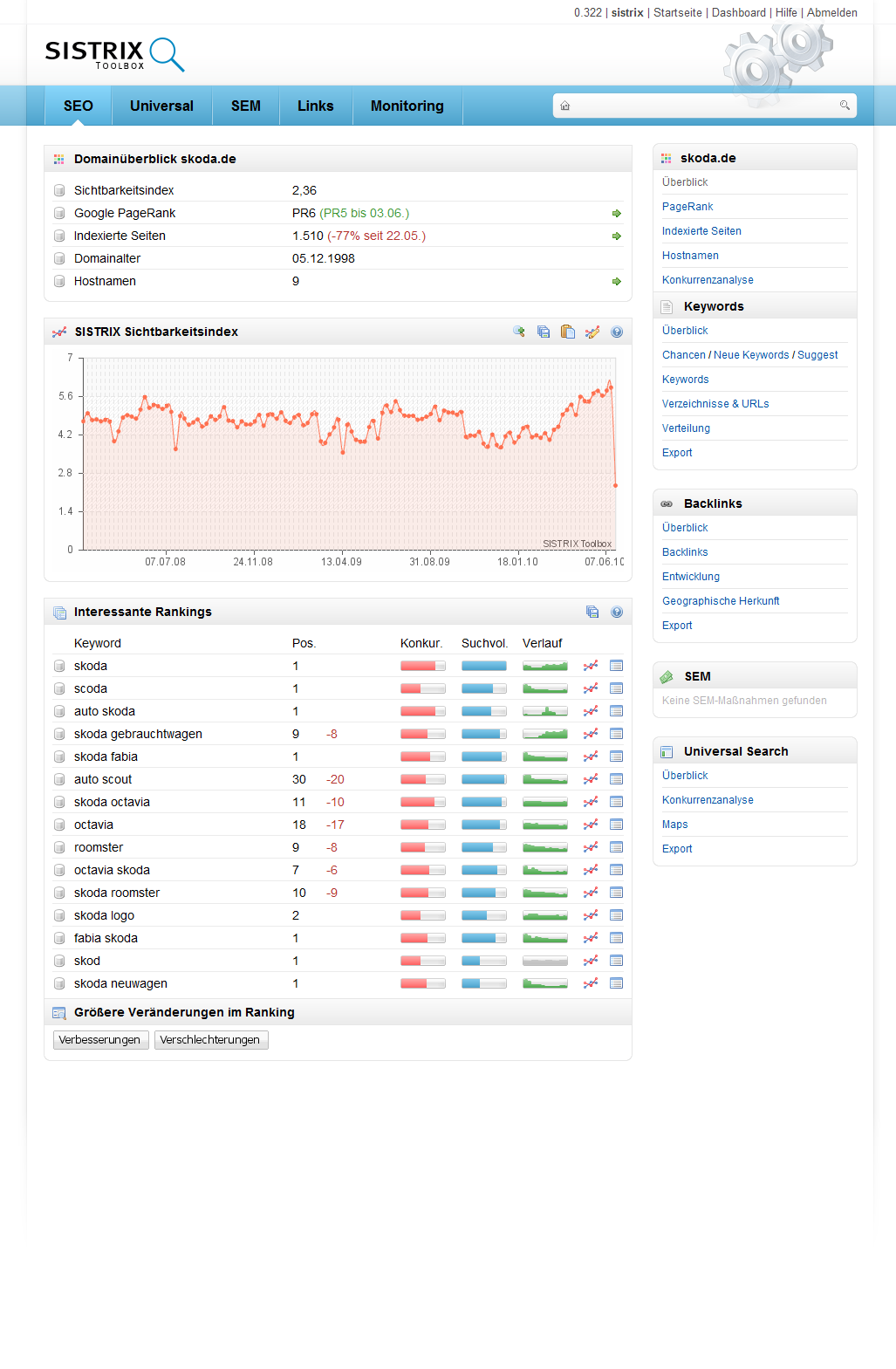
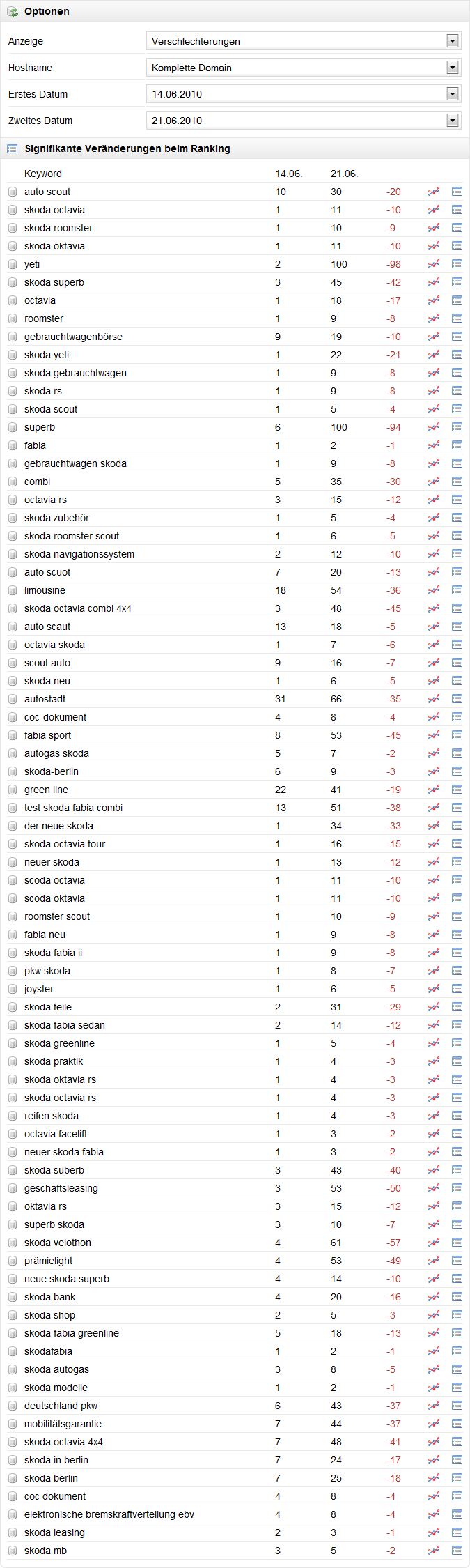
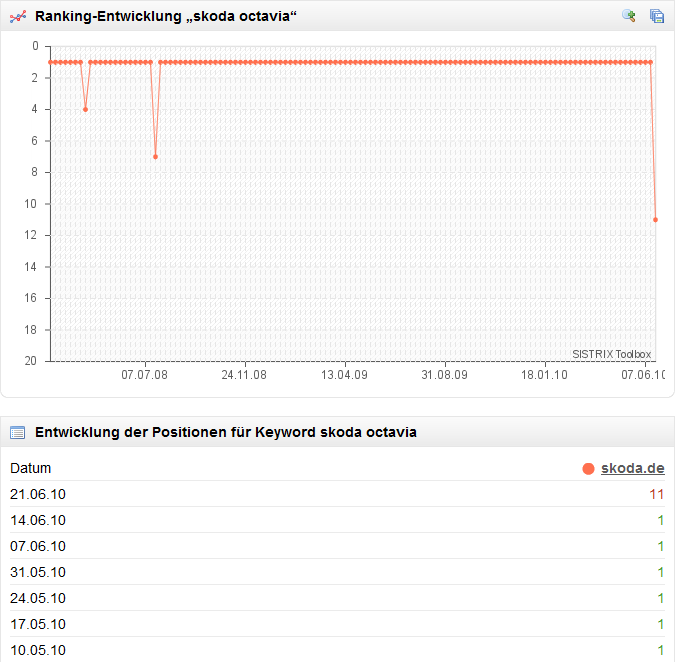
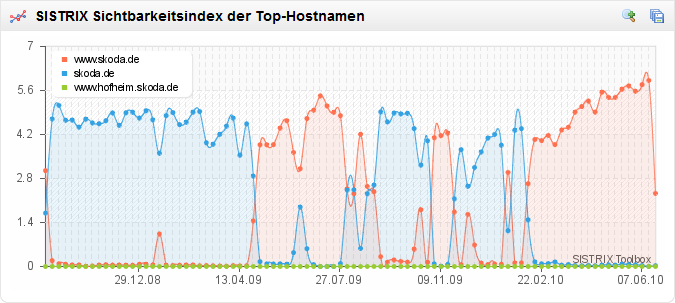
Seit Anfang 2008 gab es keine großen Veränderungen, mal ging es etwas nach oben, dann wieder nach unten. Bis letzte Woche: da hat Skoda.de 60% verloren – von knapp 6 auf 2,3 Punkte. Sieht man sich die Ursachen für den Absturz an, so wird schnell klar, dass der Relaunch die komplette Webseite getroffen hat. Neben den wenigen generischen Suchanfragen, für die skoda.de vormals in den Top-10 rankte („gebrauchtwagenbörse“ von 9 auf 19) sind hauptsächlich die trafficstarken Brand-Begriffe betroffen. Mit „skoda octavia“ fiel die Domain von Position 1 auf 11. Wenn man sich die tagesaktuellen Ergebnisse für das Keyword ansieht, so geht es noch weiter runter: Platz 90. Der Sichtbarkeitsindex wird also alles Voraussicht nach beim kommenden Update abermals stark abfallen. Dass die Betreiber der Seite sich auch bislang nicht um die Anforderungen von Suchmaschinen gekümmert haben, sieht man recht gut an dem Wechsel zwischen „skoda.de“ und „www.skoda.de“. Allerdings hat man mit dem Relaunch ein paar Hürden eingebaut, die es auch wohlwollenden Crawlern schwer machen, die Inhalte zu erfassen.
{kind=link}
{kind=link}
{kind=link}
Session-IDs
Ich habe es zuerst auch nicht geglaubt, aber bei Skoda ist man offenbar der Meinung, für die Präsentation von Autos nicht auf Session-IDs verzichten zu können. Auch für Suchmaschinencrawler wird keine Ausnahme gemacht und so hat Google zahlreiche Seiten mit dem Parameter indexiert:
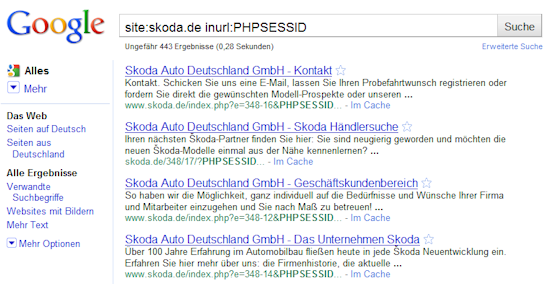
Für Suchmaschinen ergeben sich daraus verschiedene Probleme: da mit jeder neuen Session-ID, die der Crawler vorgesetzt bekommt alle Seiten auf der Domain neue URLs haben, kommt es zu Duplicate Content-Problemen. Auch die Berechnung der internen Verlinkung ist davon betroffen, da ständig neue Links auftauchen, die alten aber nicht mehr bestehen.
Seitentitel, Wortwahl
Wenn man ein Produkt hat, das landläufig als „Skoda Octavia“ bekannt ist, wie würdet ihr den Title der Seite, auf der dieses Produkt vorgestellt ist gestalten? Tja, bei Skoda geht man etwas unkonventionelle Wege: der Titel jeder Seite auf der Domain fängt erst mal mit „Skoda Auto Deutschland GmbH“ an, erst danach wird es variabel. Auf der Autoebene angekommen führt das dann zu einem Titel, in dem „Skoda Octavia“ leider nicht in dieser Schreibweise vorkommt – auf der kompletten Domain nicht:
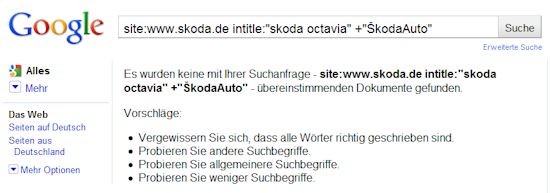
Als wäre das nicht genug, hat man auch im eigentlichen Text der Seite Probleme damit, den Produktnamen einmal korrekt auszuschreiben. Vermutlich aus Rücksichtnahme auf irgendwelche Corporate-Design-Richtlinien steht dort: „ŠkodaOctavia Limousine“ – Ja, genau, ohne Leerzeichen. Folglich kann auch Google das nicht richtig zuordnen wie man im Cache der Seite gut erkennen kann.
JavaScript, Flash, 404-Status-Code
Während die beiden ersten Punkte sicherlich ursächlich für den Absturz im Sichtbarkeitsindex waren, gibt es noch eine Reihe weiterer Probleme auf der Seite, die es Suchmaschinen schwer machen, die Inhalte zu erfassen. So ist die Sitemap, die für Crawler häufig ein sehr guter Ansatzpunkt zur Erkundung der kompletten Seite ist in JavaScript gehalten, für die Suchmaschinen also unsichtbar. Weite Teil der Webseite werden durch eine Flash-Fläche beherrscht – den dort liegenden Text können Suchmaschinen in der Regel nicht lesen und somit auch nicht in die Wertung einfließen lassen. Ein weiteres Problem für Suchmaschinen ist, dass jede URL auf der Domain den Statuscode „200“, also „alles in Ordnung“ zurückgibt. Das fällt besonders bei der (nicht vorhandenen) robots.txt auf, verleitet aber natürlich auch dazu, nicht existente Seiten in den Googleindex zu drücken 😉
Interessant ist nun, wie Google mit der Seite in den kommenden Wochen umgeht. Da Google nicht erst seit gestern crawled und dabei gelernt hat, dass jeder nur denkbare Fehler auch gemacht wird, kommt der Googlecrawler mit den häufigsten Fehlern ganz gut zurecht und denkt sich schon, was der Seitenbetreiber eigentlichen machen wollte. Ich könnte mir auch gut vorstellen, dass es bei Skoda dazu kommt – die Domain ist einfach zu gut verlinkt, als dass Google sie dauerhaft ignorieren kann.