
Nachdem der Test aus dem letzten Posting ja zu keinem definitiven Ergebnis geführt hat, habe ich einen neuen Test gemacht und glaube, die Antwort jetzt gefunden zu haben. Wie vor ein paar Tagen, habe ich auch dieses mal ein paar Seiten und Links erstellt und wollte damit rausfinden, wie lang ein Linktext denn nun sein darf. Da der letzte Test gezeigt hat, dass die reine Länge des Linktextes kein begrenzender Faktor ist, habe ich dieses Mal die Anzahl der Worte im Linktext getestet, hier online zu sehen. Bei 8 Worten beziehungsweise 7 Leerzeichen wird die Zielseite noch mit dem letzten Linktext gefunden:
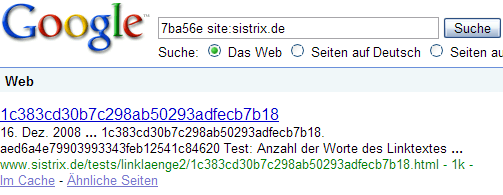
Bei 9 Worten beziehungsweise 8 Leerzeichen nicht mehr:
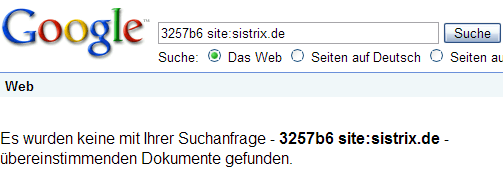
Mit dem vorletzten Verlinkten (dem 8. Wort) allerdings schon, Google schneidet also einfach nach den 8 Worten ab. Das ist übrigens genau der Wert, den Shaun in seinem ursprünglichen Blogpost erwähnt hat – er hat daraus allerdings den falschen Schluss gezogen, dass Google den Linktext nach Anzahl von Buchstaben begrenzt. Dass dies nicht so ist und Google die Anzahl der Trennzeichen nimmt, glaube ich mit den 2 Tests gezeigt zu haben.
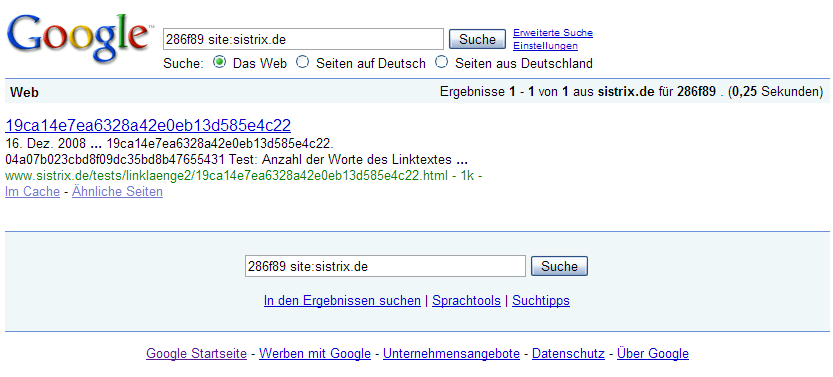{kind=link}
Die Konsequenzen aus dieser Erkenntnis zeigen nun schön, dass überraschend vieles im SEO-Bereich irgendwie zusammenhängt – in diesem Fall Linktextlänge und URL-Design. Sehr viele Nutzer verlinken URLs, wenn es schnell gehen muss oder wenn das CMS das so vorsieht mit der URL selber als Linktext. Wenn man jetzt davon ausgeht, dass Google nicht nur Leerzeichen, sondern auch die sonst üblichen Trennzeichen nutzt, hat das zur Folge haben, dass bei sprechenden URLs die eigentlich interessanten Bereiche unter Umständen gar nicht im Linktext gewertet werden. Beispiel:
www.sistrix.de/artikel/verschiedenes/1337–dies–ist–das–keyword.html
Die Trennzeichen habe ich mal rot markiert und wie man sieht, wird in diesem Fall das eigentlich wichtige „keyword“ gar nicht als Linktext gewertet, da zu viele Trennzeichen davor stehen. Also: URL kurz halten, IDs – wenn unbedingt nötig – an das Ende der URL, Anzahl der Unterverzeichnisse auf die unbedingt Notwendigen begrenzen und wichtige Keywords möglichst weit vorne in der URL unterbringen.