
Es gibt kein Duplicate-Content-Problem – das jedenfalls war noch im September letzten Jahres der Tenor eines Postings im Google Webmasterblog. Heute hat man in der Auslegung dieser Sache dann die Flexibilität der Nasenspitze eines Aardvarks eingenommen und stellt zusammen mit Yahoo und Microsoft eine Lösung für das (nicht-existente) Duplicate-Content-Problem vor. Mit einem neuen Hinweis im Quelltext einer jeden Webseite soll der Webseitenbetreiber – so die Vorstellung des Trios – in Zukunft die „richtige“ URL angeben und Duplicate-Content, der dadurch entsteht, dass die gleiche Webseite unter mehr als einer URL erreichbar ist, vermeiden helfen.
Probleme damit, dass Seiten unter mehr als einer URL erreichbar sind, entstehen in der Regel nur dann, wenn Seiten dynamisch generiert werden. Google hat in dem Blogposting ein schönes Beispiel gegeben: sowohl unter example.com/shop.php?item=seo als auch unter example.com/shop.php?item=seo&category=spam wird jeweils der gleiche Artikel mit dem gleichen Content angezeigt. Neben unsauber programmierten Seiten, ist häufig auch ein Grund für sowas, dass URLs in Laufe verschiedener Softwareversionen verändert werden, aber weiterhin abwärtskompatibel bleiben sollen.
In der SEO-Branche hat die Ankündigung für einige Euphorie gesorgt, Seomoz sah‘ sich gar hingerissen, von der größten Weiterentwicklung seit Einführung der XML-Sitemaps zu sprechen. Wie man am Tonfall der letzten Zeilen und der Überschrift eventuell schon erahnen kann, sehe ich die Sache etwas differenzierter und möchte das im Folgenden erklären:
Es gibt bereits eine Lösung
Die Möglichkeit, falsche URLs auf die richtige Version weiterzuleiten existiert mit der 301-Weiterleitung seit Ewigkeiten. Suchmaschinen folgen diesen Anweisungen und nehmen die Zielseite in den Index auf. Das eigentliche Problem liegt an einer ganz anderen Stelle: die meisten Webanwendungen kennen ihre richtige URL gar nicht, können also gar keinen Vergleich zwischen der abgerufenen und der korrekten URL machen und im Fall eines Unterschieds per 301-Redirect weiterleiten. Da auch für den jetzt eingeführten, neuen Tag die Webseite „ihre richtige“ URL kennen muss, sehe ich da keinen Fortschritt.
Neue Links werden verstreut
Seiten werden mit der URL verlinkt, mit der sie im Browser aufgerufen werden. Dürfte wenig überraschend sein, hat, wenn man dem Vorschlag folgt, allerdings negative Auswirkungen. Zuerst hier ein Beispiel, wie es bei der Lösung mit einem 301-Redirect aussieht:
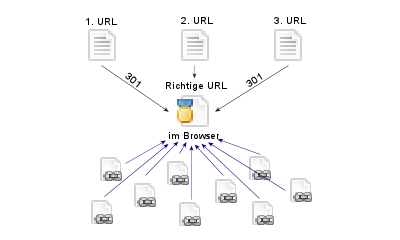
Der Surfer wird auf die richtige URL weitergeleitet, sieht diese in der Adresszeile seines Browser und wird diese URL verlinken oder zitieren. Diese Weiterleitung fehlt allerdings, wenn man „Canonical“-Tag setzt:
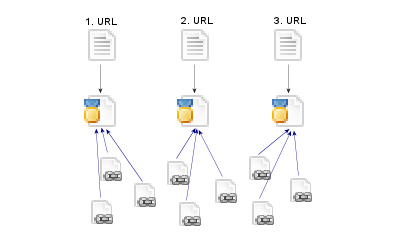
Neue Links auf die eine Seite werden nicht mehr auf dieser konzentriert sondern auf die verschiedenen Versionen, die so ja alle unter verschiedenen URLs online sind, verteilt. Man muss jetzt darauf vertrauen, dass die Suchmaschinen den Linkjuice möglichst vollständig auf die Hauptseite überträgt.
Der Vorschlag von Google, Yahoo und Microsoft mildert Auswirkungen anstatt Ursachen zu beseitigen. Neue und proprietären HTML-Tags werden eingeführt, obwohl es für die Lösung des Problems etablierte Wege gibt.