
Der User Agent wird vom Browser bei jeder Anfrage an einen Webserver mitgesendet und soll Informationen über das genutzte System anzeigen. Es ist damit sozusagen das Namensschild des Browsers.
Was ist der User Agent?
Bei dem User-Agent handelt es sich um ein Feld im HTTP Protokoll, über welches eine mehr oder minder ausführliche Information über das Abfragende Gerät, bei einer Netzwerkanfrage, mit übermittelt werden kann.
Dies geschiht über den HTTP-Header und diese Information kann dann, zum Beispiel, dazu genutzt werden, um bestimmte Elemente nur an solche Browser auszuliefern, die bekanntermaßen damit umgehen können.
Wie setzt sich der User Agent zusammen?
Die Syntax für den User Agent Eintrag ist erst einmal recht simple:
User-Agent: <Produkt> / <Produkt-Version> <Kommentar>Schauen wir uns jedoch zum Beispiel einen Standard User Agent des Smartphone Googlebots an, sieht es schon anders aus:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)Diesen User Agent können wir wie folgt aufschlüsseln:
- Mozilla– ist das Produkt
- 5.0– ist die Produkt-Version.
- (Linux;– das Betriebssystem des Geräts.
- Android 6.0.1;– die Version des Betriebssystems.
- Nexus 5X Build/MMB29P)– die Build Bezeichnung des Betriebssystems.
- AppleWebKit/537.36– die Rendering Engine des Browsers.
- (KHTML, like Gecko)– die Rendering Engine verhält sich wie (beruht auf) KHTML, welches sich wie Gecko verhält.
- Chrome/41.0.2272.96– der Browser und dessen Versionsnummer.
- Mobile Safari/537.36– der Browser verhält sich wie Safari in der Versionsnummer 537.36.
- (compatible;– Hier beginnt der eigentliche Kommentar, mit der Erklärung, dass das abfragende Gerät zum Mozilla Browser kompatible ist.
- Googlebot/2.1;– Name und Versionsnummer des abfragenden Crawlers.
- +http://www.google.com/bot.html)– wo bekomme ich weitere Informationen über diesen Agenten her?
Falls Du dich jetzt wunderst, warum sich der Googlebot, bei dem es sich um einen Google Chrome Browser handelt, als Mozilla ausgibt, bist Du nicht allein. Es gibt eine amüsante „history of the browser user-agent string“ (auf Englisch) in der alles Wichtige zusammengetragen ist.
Die Quintessenz ist die, dass sich fast alle Browser, aus „Gründen“, als Mozilla ausgeben. Der <Produkt>-Wert ist damit irrelevant und die Kommentare wurden um ein vieles Länger.
Wie nutzt der Server User-Agent Informationen?
Die Informationen über das anfragende System kann der Server nutzen, um Nutzern eine passende Version der Webseite zu liefern. Gibt der User Agent dem Server zum Beispiel an, dass eine Anfrage von einem Android-Handy mit dem Browser Chrome ausgeht, kann der Server die mobile Version der angefragten Webseite ausspielen, falls eine mobile Version der Seite vorliegt..
Mithilfe des User Agents kann der Server auch ermitteln, ob die genutzte Browser-Version noch aktuell ist. Wird beispielsweise ein “alter” Browser benutzt wie Internet Explorer 6, kann der Server darauf reagieren und eine Bitte zum Upgrade senden, statt der angefragten Webadresse.
Zuletzt können die Informationen der User Agents von den Web Servern zum Beispiel für statistische Zwecke gesammelt werden.
User Agents und Crawler
Auch Crawler besitzen einen User Agent. Dadurch, dass der User Agent einen Bot als solchen kennzeichnet, geben Webserver diesen besondere “Privilegien”. So kann der Googlebot vom Webserver zum Beispiel durch Registrations-Seitens gewunken werden. Wobei es hierbei sehr wichtig ist, nicht Gefahr zu laufen, den Nutzern andere Inhalte zu zeigen wie dem Googlebot, wobei es sich um Cloaking handelt.
Über die robots.txt-Datei (in der auch der User Agent enthalten ist) kann der Webserver zudem Bots bitten, das Crawlen von bestimmten Bereichen einer Webseite zu unterlassen.
Wie kann ich den User Agent für SEO nutzen?
Mit dem Wissen, mit welcher Information sich die verschiedenen Google Crawler ausgeben, kann man seinen Browser so einstellen, per Browser-Addon oder über die Developer Console, dass man die gleiche Kennung übermittelt.
So lässt sich zum Beispiel häufig prüfen, ob eine Webseite dem Googlebot andere Inhalte ausliefert als regulären Besuchern.
Um zur benötigten Ansicht zu gelangen, nutze bitte zuerst folgeden Tastatur-Shortcut um die Chrome Entwicklertools aufzurufen:
Mac: Befehl + Alt + C
Windows: Strg + Umschalt + C
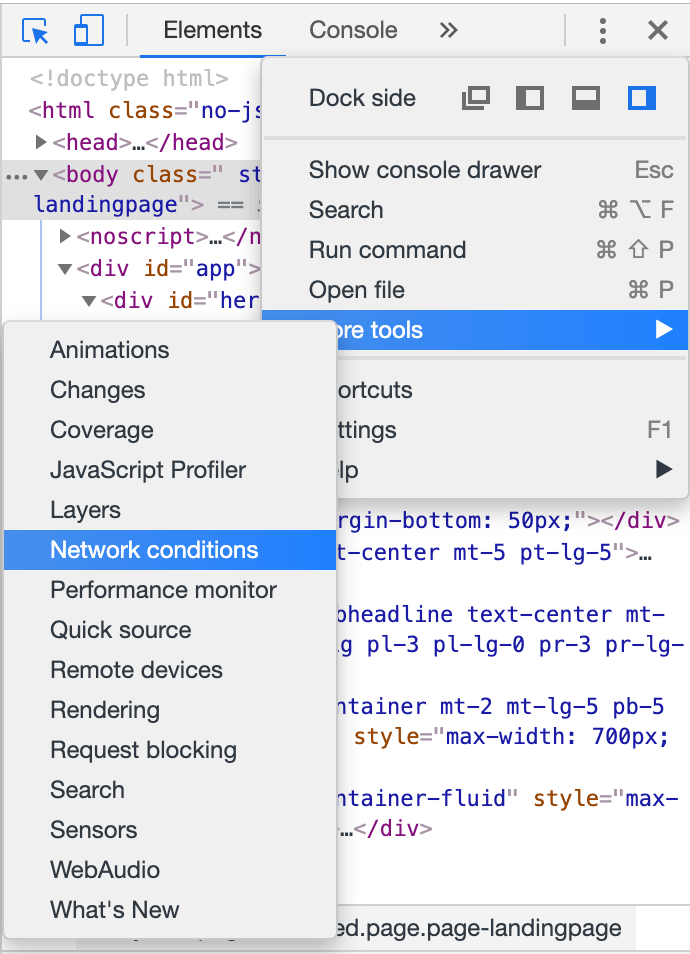
Klicke hier auf die , in der rechten oberen Ecke der Entwicklerkonsole 1, und wähle dort „More tools“ 2 und dann „Network conditions“ 3:
Unten in der Entwicklerkonsole öffnet sichein neuer Tab auf den geklickt werden kann.
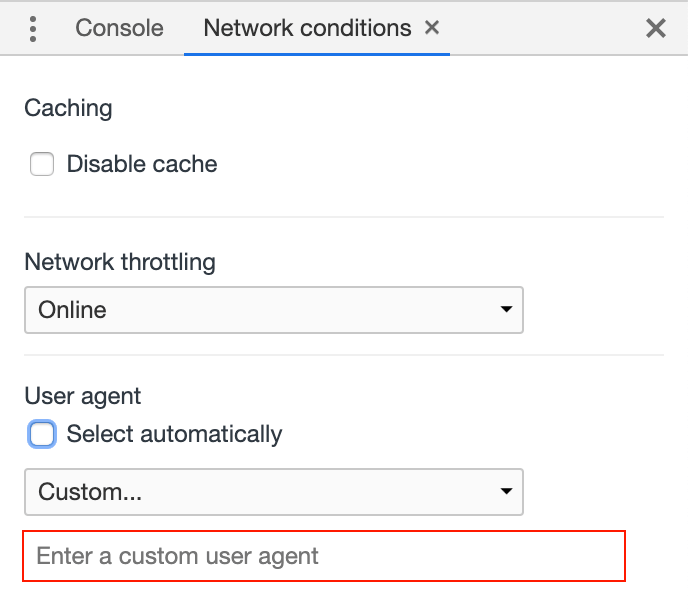
In dem rot markierten Feld lässt sich jetzt der gewünschte User-Agent String einfügen.
Dies funktioniert jedoch nur, solange der Server nicht eine interne Prüfung durchführt, ob ein User-Agent der sich als Googlebot ausgibt, auch tatsächlich von einer Google IP stammt.
Welche User-Agents sind für SEO nützlich?
In der folgenden Tabelle haben wir die User-Agents zusammen gestellt, die für SEO am häufigsten Verwendung finden.
Google User-Agents
| Crawler | User-Agent-Token | User-Agent-String |
|---|---|---|
| Googlebot Image | - Googlebot-Image - Googlebot | Googlebot-Image/1.0 |
| Googlebot News | - Googlebot-News - Googlebot | Googlebot-News |
| Googlebot Video | - Googlebot-Video - Googlebot | Googlebot-Video/1.0 |
| Googlebot (Desktop) | Googlebot | - Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/W.X.Y.Z Safari/537.36 selten auch: - Googlebot/2.1 (+http://www.google.com/bot.html) |
| Googlebot (Smartphone) | Googlebot | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Favicon | Google Favicon | Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 Google Favicon |
Die Chrome-Versionsangaben W.X.Y.Z, beim Googlebot für Desktop und Smartphone, sind als Platzhalter gedacht. Google update diese immer zur neusten Chrome Version. Mehr dazu findet ihr auf im Google Webmaster Blogpost.
Andere hilfreiche User-Agents
Die folgende Tabelle beinhaltet verschiedene andere User-Agent-Strings, welche in SEO-Projekten relevant werden können, zB im Hinblick auf die Einsparung von Bandbreite.
| Crawler | User-Agent-Token | User-Agent-String |
|---|---|---|
| Pinterestbot | - Pinterest/0.2 (+https://www.pinterest.com/bot.html) - Mozilla/5.0 (compatible; Pinterestbot/1.0; +https://www.pinterest.com/bot.html) - Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Pinterestbot/1.0; +https://www.pinterest.com/bot.html) | |
| LinkedInBot | LinkedInBot/1.0 (compatible; Mozilla/5.0; Jakarta Commons-HttpClient/3.1 +http://www.linkedin.com) | |
| Bing | bingbot | - Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Mozilla/5.0 (iPhone; CPU iPhone OS 7_0 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A465 Safari/9537.53 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Mozilla/5.0 (Windows Phone 8.1; ARM; Trident/7.0; Touch; rv:11.0; IEMobile/11.0; NOKIA; Lumia 530) like Gecko (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Yandex* | YandexBot | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
| Wayback Machine | archive.org_bot | Mozilla/5.0 (compatible; archive.org_bot +http://www.archive.org/details/archive.org_bot) |
* Zu Yandex: es gibt noch eine Reihe an anderen User-Agents die sich als YandexBot identifizieren und möglicherweise noch gültig sind.