
Indexierung ist ein zentraler Begriff im Bereich Suchmaschinenoptimierung (SEO). Sie bezeichnet den Prozess, bei dem Suchmaschinen wie Google die Inhalte einer Webseite analysieren, verarbeiten und in ihrem eigenen Datenbestand – dem sogenannten Index – speichern. Nur Webseiten oder einzelne Seiten, die erfolgreich indexiert wurden, können in den organischen Suchergebnissen erscheinen.
- Indexierung: Wie Google Seiten bewertet
- Analyse der Inhalte und Strukturen
- Clustering und Auswahl der kanonischen Version
- Speicherung im Index
- So prüfst du die Google-Indexierung deiner Seiten
- Site-Abfrage in der Google-Suche
- URL-Prüfung in der Google Search Console
- Häufige Indexierungsprobleme und wie du sie beheben kannst
- Technische Barrieren
- Inhaltliche Schwächen
- Strukturelle Mängel
- Performance- und Serverprobleme
- Wie lange dauert die Google-Indexierung?
- Einflussfaktoren auf die Dauer
- Wichtige Hinweise zur Indexierung
- Indexierung als Grundlage für den SEO-Erfolg
Dabei ist die Indexierung ein eigenständiger Schritt innerhalb des Gesamtprozesses, den eine Seite durchläuft, bevor sie in den Suchergebnissen sichtbar wird. Der Ablauf lässt sich in drei Hauptphasen unterteilen:
- Crawling: Googlebot, der Crawler der Suchmaschine, entdeckt neue oder aktualisierte Seiten, indem er das Internet kontinuierlich durchsucht. Dabei folgt er Hyperlinks und nutzt Sitemaps als Orientierungshilfe.
- Indexierung: Nach der Entdeckung wird die Seite verarbeitet. Google analysiert Textinhalte, Meta-Tags wie das <title>-Element, ALT-Attribute von Bildern sowie eingebundene Videos. Dabei wird geprüft, welche Informationen die Seite bietet, wie sie strukturiert ist und ob sie mit anderen Inhalten im Internet übereinstimmt.
- Ranking: Erst nach der erfolgreichen Indexierung kann eine Seite bei passenden Suchanfragen in den Suchergebnissen erscheinen. Die Reihenfolge, in der Seiten angezeigt werden, basiert auf zahlreichen Faktoren wie Relevanz, Nutzerfreundlichkeit und Autorität.
Die Google-Indexierung funktioniert ähnlich wie der Katalog einer Bibliothek. Nur Bücher, die im Katalog erfasst sind, können von Besuchern gefunden und ausgeliehen werden. Genauso verhält es sich bei Webseiten: Nur Inhalte, die im Google-Index registriert sind, haben eine Chance, bei Suchanfragen der Nutzer sichtbar zu werden.
Indexierung: Wie Google Seiten bewertet
Nachdem der Googlebot eine Seite entdeckt und gecrawlt hat, beginnt der Prozess der Indexierung. In dieser Phase versucht Google zu verstehen, worum es auf der Seite geht und ob der Inhalt im Index gespeichert werden soll. Der Ablauf ist dabei deutlich komplexer als eine reine Datenspeicherung.
Analyse der Inhalte und Strukturen
Zunächst verarbeitet Google alle sichtbaren und unsichtbaren Bestandteile einer Seite. Dazu gehören:
- Textinhalte: Der Fließtext wird analysiert, um die thematische Relevanz der Seite zu bestimmen.
- Wichtige HTML-Elemente: Tags wie das <title>-Element und Überschriften (<h1>, <h2> usw.) liefern Google Hinweise auf die Hauptthemen.
- Multimedia-Inhalte: Bilder und Videos werden über Attribute wie ALT-Tags oder Dateinamen semantisch eingeordnet.
- Meta-Tags: Angaben wie Meta-Descriptions oder Meta-Robots-Tags beeinflussen, ob und wie die Seite indexiert werden kann.
Google legt dabei großen Wert auf eine saubere Strukturierung der Inhalte, um diese besser interpretieren zu können.
Clustering und Auswahl der kanonischen Version
Ein weiterer wichtiger Bestandteil des Indexierungsprozesses ist das sogenannte Clustering. Hierbei gruppiert Google Seiten, die inhaltlich sehr ähnlich sind. Innerhalb eines Clusters wählt Google eine kanonische Seite aus. Diese wird bevorzugt in den Suchergebnissen angezeigt.
Die Entscheidung, welche Seite kanonisch wird, basiert auf mehreren Kriterien:
- Nutzerfreundlichkeit und Ladezeit
- Sprache und Lokalisierung (z. B. Zielregion)
- Strukturierte Daten und technische Signale
- Qualität und Originalität der Inhalte
Andere Seiten im Cluster können ebenfalls erhalten bleiben, werden aber meist nur in speziellen Fällen ausgespielt, etwa bei mobilen Suchanfragen oder bei gezielter Suche nach einer alternativen Version.
Speicherung im Index
Nach der Verarbeitung speichert Google die relevanten Informationen im Google-Index. Diese gigantische Datenbank wird über Tausende Server weltweit verteilt und ermöglicht die schnelle Auslieferung von Suchergebnissen. Die Indexierung hängt unter anderem ab von:
- Der Qualität der Inhalte
- Technischen Einstellungen wie Robots-Meta-Tags oder Canonical-Angaben
- Der allgemeinen Vertrauenswürdigkeit und Relevanz der Website
Nur Seiten, die diese Anforderungen erfüllen, erhalten dauerhaft einen Platz im Index.
So prüfst du die Google-Indexierung deiner Seiten
Die regelmäßige Überwachung des Indexierungsstatus gehört zu den Grundlagen erfolgreicher Suchmaschinenoptimierung. Nur wenn Inhalte im Google-Index vorhanden sind, können sie potenziell bei Suchanfragen erscheinen. Es gibt verschiedene Methoden, um schnell und präzise zu prüfen, ob eine Seite indexiert ist.
Site-Abfrage in der Google-Suche
Eine einfache und schnelle Möglichkeit bietet die Site-Abfrage. Gib in der Google-Suche folgendes ein:
site:deinewebseite.com/unterseite
Wenn die Seite im Index ist, wird sie als Suchergebnis angezeigt. Bleibt die Ergebnisseite leer, ist die URL entweder nicht indexiert oder bewusst aus dem Index ausgeschlossen worden. Diese Methode eignet sich besonders für Einzelprüfungen, ersetzt aber keine umfassende Analyse größerer Websites.
URL-Prüfung in der Google Search Console
Für eine detailliertere Überprüfung eignet sich die Google Search Console. Mit der Funktion „URL-Prüfung“ lässt sich der genaue Indexierungsstatus einer spezifischen Seite abrufen:
- Gib die vollständige URL in das Eingabefeld oben ein.
- Die Search Console zeigt, ob die Seite auf Google vorhanden ist.
- Zusätzlich erhältst du Hinweise auf Crawling- oder Indexierungsprobleme sowie auf die gewählte kanonische URL.
Besonders wertvoll: Die Search Console informiert auch darüber, wann Google die Seite zuletzt gecrawlt hat und ob strukturierte Daten erkannt wurden.
Häufige Indexierungsprobleme und wie du sie beheben kannst
Nicht jede Seite wird automatisch in den Google-Index aufgenommen. Die Gründe dafür sind vielfältig. Für eine stabile und vollständige Indexierung ist es entscheidend, typische Fehlerquellen zu kennen und gezielt zu beseitigen.
Technische Barrieren
Problem:
Fehlerhafte technische Einstellungen können verhindern, dass Seiten überhaupt gecrawlt oder indexiert werden. Häufige Ursachen sind:
- Sperrung durch die robots.txt-Datei
- Falsch gesetzte Meta-Robots-Tags mit noindex
- Canonical-Fehler, die auf eine andere URL verweisen
- Serverfehler (z. B. 404 oder 500-Statuscodes)
Lösung:
Überprüfe die robots.txt, Meta-Tags und Canonical-Tags auf allen wichtigen Seiten. Achte darauf, dass relevante Seiten für den Googlebot erreichbar sind und korrekt mit einem HTTP-Status 200 antworten.
Im SISTRIX Projekt kannst du genau sehen, welche Seiten indexierbar sind – und warum andere es nicht sind. Unter dem Punkt „Indexierbarkeit“ wird automatisch geprüft, ob Seiten durch noindex, robots.txt oder Canonicals ausgeschlossen sind.
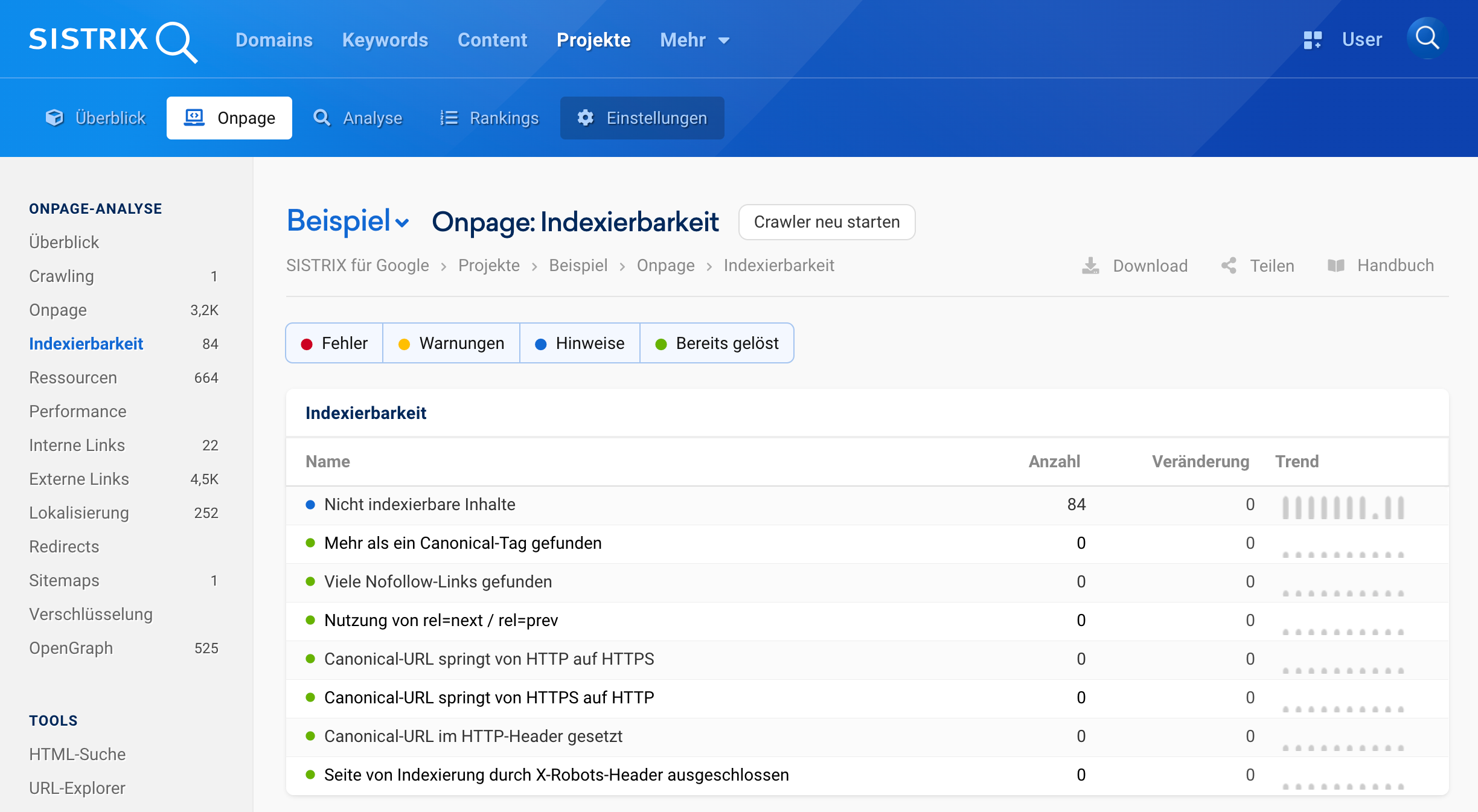
Auch Statuscodes wie 404, 500 oder 301 werden ausgewertet. Du erkennst sofort, wo genau der Fehler entsteht – zum Beispiel bei einer Weiterleitung oder der Zielseite. Das spart Zeit bei der Analyse und hilft, technische Fehler gezielt zu beheben.
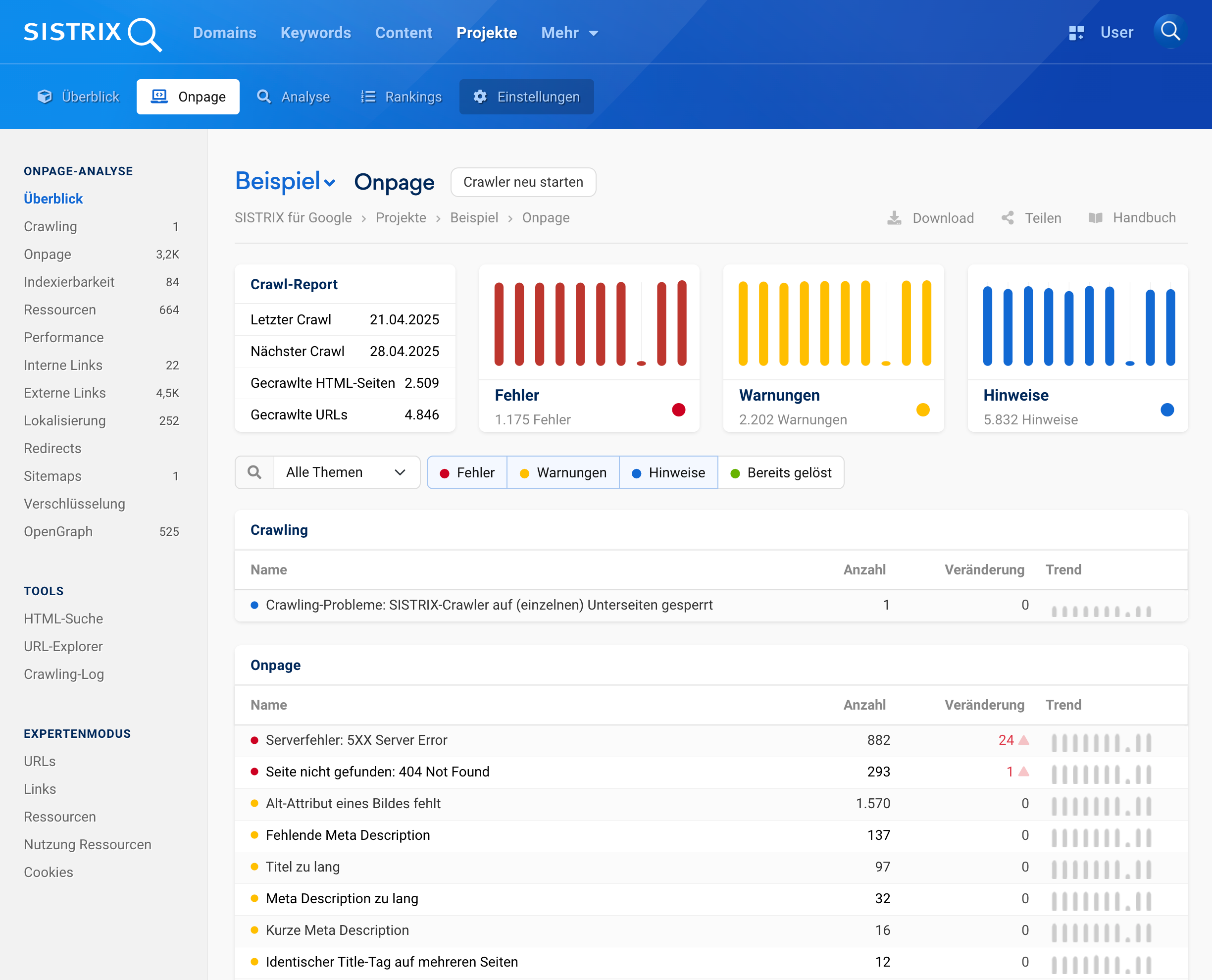
TIPP: Mit SISTRIX lassen sich Indexierungsprobleme frühzeitig erkennen und beheben, bevor sie Sichtbarkeit und Reichweite kosten. Mit einem kostenlosen 14-tägigen Testaccount kannst du deine Webseite direkt umfangreich checken.
Inhaltliche Schwächen
Problem:
Seiten mit schwachem oder doppeltem Inhalt werden von Google oft nicht indexiert. Typische Probleme sind:
- Duplicate Content
- Sehr dünne Inhalte („Thin Content“)
- Fehlende Relevanz für Nutzeranfragen
Lösung:
Erstelle hochwertige, einzigartige Inhalte, die klar auf eine Suchintention ausgerichtet sind und die Google E-E-A-T-Richtlinien erfüllen. Seiten sollten umfassend ein Thema behandeln und dem Nutzer einen echten Mehrwert auf Basis eigener Erfahrungswerte bieten. Alte, dünne oder minderwertige Inhalte sollten aktualisiert oder gezielt deindexiert werden, um die Gesamtqualität der Website zu stärken.
Strukturelle Mängel
Problem:
Eine schlechte interne Verlinkung und unübersichtliche Seitenstrukturen erschweren dem Googlebot die Entdeckung neuer Inhalte. Häufige Fehler sind:
- Isolierte Seiten ohne interne Links
- Zu komplexe oder dynamische URL-Strukturen
Lösung:
Stelle sicher, dass jede wichtige Seite sinnvoll intern verlinkt ist. Nutze flache Seitenhierarchien, klare Navigationspfade und eine durchdachte URL-Struktur. Neue Inhalte sollten möglichst frühzeitig prominent eingebunden werden, etwa durch Verlinkung von der Startseite oder aus thematisch passenden Artikeln.
Performance- und Serverprobleme
Problem:
Langsame Ladezeiten oder instabile Server können dazu führen, dass Google den Crawl abbricht oder Seiten gar nicht erst verarbeitet.
Lösung:
Optimiere die technische Basis deiner Website. Reduziere die Ladezeiten durch komprimierte Bilder, saubere Codestrukturen und effizientes Hosting. Achte auf eine stabile Serververfügbarkeit und vermeide unnötige Weiterleitungen oder Fehlermeldungen.
Wie lange dauert die Google-Indexierung?
Neue oder aktualisierte Seiten erscheinen nicht sofort im Google-Index. Laut John Müller von Google dauert es in der Regel maximal eine Woche, bis gute Inhalte indexiert sind. Unter optimalen Bedingungen kann die Aufnahme jedoch bereits innerhalb weniger Stunden erfolgen.
Einflussfaktoren auf die Dauer
Die Dauer der Indexierung hängt von mehreren Faktoren ab:
- Leistung des Webservers: Ein schneller und stabiler Server ermöglicht es dem Googlebot, Seiten effizienter abzurufen und zu verarbeiten. Server, die langsam reagieren oder Anfragen nicht zuverlässig beantworten, können die Indexierung verzögern.
- Prominente interne Verlinkung: Neue Seiten sollten möglichst direkt von zentralen Seiten wie der Startseite verlinkt werden. So entdeckt der Googlebot neue Inhalte schneller.
- Fokus auf relevante URLs: Unnötige URLs, etwa aus unendlichen Kalendern oder zahlreichen Filterkombinationen, sollten vermieden werden. Solche Seiten können das Crawling-Budget belasten und verhindern, dass wichtige Seiten priorisiert werden.
- XML-Sitemap: Eine aktuelle Sitemap hilft Google, neue oder geänderte Seiten effizient zu finden und zu bewerten.
- Manuelle Einreichung einzelner URLs: Über das URL Inspection Tool in der Google Search Console können wichtige Seiten gezielt zur Indexierung vorgeschlagen werden.
- Qualität der Website: Je klarer Google erkennt, dass eine Website hochwertige und für Nutzer relevante Inhalte bietet, desto schneller und zuverlässiger erfolgt die Indexierung.
Wichtige Hinweise zur Indexierung
Trotz aller Maßnahmen gibt es keine festen Garantien für die Dauer der Indexierung. Sie kann sich jederzeit ändern, etwa aufgrund technischer Probleme auf der Website oder weil Google aktuell andere Prioritäten setzt.
Auch eine erfolgreiche Indexierung bleibt nicht zwingend dauerhaft bestehen. Seiten können aus dem Index entfernt werden, wenn sich ihre Qualität verschlechtert oder sie für Nutzer nicht mehr relevant sind.
Eine regelmäßige Überprüfung des Indexierungsstatus sowie eine konsequente Pflege der technischen und inhaltlichen Qualität sind daher unverzichtbar, um die Sichtbarkeit langfristig zu sichern.
Indexierung als Grundlage für den SEO-Erfolg
Die Indexierung ist die Basis dafür, dass Webseiten in Suchmaschinen erscheinen können. Ohne eine erfolgreiche Aufnahme in den Index bleibt eine Seite unsichtbar, unabhängig davon, wie hochwertig die Inhalte sind oder wie gut sie technisch optimiert wurden.
Probleme bei der Indexierung entstehen meist durch technische Fehler, qualitative Schwächen der Inhalte, strukturelle Defizite innerhalb der Website oder Performance-Probleme.
Durch gezielte Maßnahmen wie die Beseitigung technischer Fehler, die Optimierung von Inhalten und Strukturen sowie die konsequente Verbesserung der Nutzerfreundlichkeit kann die Wahrscheinlichkeit einer erfolgreichen und stabilen Indexierung erheblich gesteigert werden.
Wer langfristig in den Suchergebnissen sichtbar sein möchte, muss die Qualität und Relevanz seiner Inhalte ständig hinterfragen und weiterentwickeln. Auch der Kontext der Nutzer, etwa ihr Standort, ihr Endgerät oder ihre Sprache, beeinflusst maßgeblich, ob und wie eine indexierte Seite tatsächlich ausgespielt wird.
Tools wie die Google Search Console oder professionelle Werkzeuge wie SISTRIX bieten wertvolle Unterstützung, um Indexierungsprobleme frühzeitig zu erkennen und effizient zu beheben. Letztlich entscheidet die Kombination aus technischer Sauberkeit, inhaltlicher Exzellenz und Nutzerzentrierung darüber, ob eine Seite nicht nur indexiert wird, sondern auch im entscheidenden Moment für den Nutzer sichtbar ist.
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten