
Beim Cloaking werden Benutzern und Suchmaschinen-Crawlern unterschiedliche Inhalte auf ein und derselben Seite angezeigt. Diese Verschleierung kann bewusst oder unbewusst passieren.
- Warum wollen Suchmaschinen kein Cloaking?
- Warum wird Cloaking benutzt?
- Cloaking zum Verschleiern von illegalen Aktivitäten
- Cloaking zum Verschleiern von nicht-richtlinienkonformen Aktivitäten
- Zufälliges und nicht beabsichtigtes Cloaking
- Cloaking und Paywalls
- Sonderfall Cloaking und Google News
- Ist Geotargeting Cloaking?
- Cloaking in Zeiten von SPAs und JavaScript
- Fazit zum Thema Cloaking
Wenn es bei der Suchmaschinenoptimierung um Cloaking geht, dreht es sich um die Praxis, Suchmaschinencrawlern einen anderer Inhalt auf einer URL auszuspielen als einem regulären Besucher. Diese Verschleierung kann viele verschiedene Gründe haben und kann entweder bewusst oder aus Versehen geschehen.
Warum wollen Suchmaschinen kein Cloaking?
Für Google stellt Cloaking einen Verstoß gegen ihre Qualitätsrichtlinien dar und kann zu einer manuellen Abstrafung führen oder über algorithmische Filter erkannt werden.
Der Grund warum Google solche eine Verschleierung nicht möchte lässt sich sehr gut verstehen, wenn wir uns anschauen womit Google Geld verdient und was sonst noch in der Suche geschieht.
Googles Mutterkonzern, Alphabet, finanziert sich zu über 85% aus Werbeeinnahmen aus Googles Werbenetzwerken, wie zum Beispiel AdWords. Die daraus resultierenden Gewinne sind zwar astronomisch, jedoch gehen nur ungefähr 7% aller Klicks auf AdWords Anzeigen.
Es gibt also sehr viele Suchanfragen, bei denen Google keine Einnahmen generiert, den Nutzern jedoch trotzdem das (gefühlt) beste Ergebnis liefern muss, damit diese Suchenden auch weiterhin die Suchmaschine Google nutzen und nicht nach einer Alternative Ausschau halten.
Stellen wir uns vor, Google liefert einem Suchenden eine Seite aus dem Grund aus, dass dem Googlebot bestimmte Inhalte gezeigt wurden, die sehr relevant für die Suchanfrage sind. Wenn der Besucher auf die Seite geht und diese Informationen dort nicht vorfindet, zum Beispiel weil diese durch eine Paywall oder Login eingezäunt sind, it es nachvollziehbar, dass die Frustration des Nutzers darüber, zumindest in Teilen, auf Google zurückfällt.
Warum wird Cloaking benutzt?
Das Spektrum der Gründe ist weit gefächert und geht vom bewussten Verschleiern von spammigen oder sogar illegalen Aktivitäten bis hin zu versehentlichem und unabsichtlichem Cloaking durch technische Anpassungen an der Seite.
Cloaking zum Verschleiern von illegalen Aktivitäten
Fangen wir mit dem unangenehmsten Fall an: jemand schafft es Zugriff auf das Content-Management-System einer Seite zu bekommen. Dort werden dann Seiten erstellt die für bestimmte Keywords – meist aus den Themengebieten Erwachsenenunterhaltung, Glücksspiel oder Pharmazeutika – ranken sollen und auf denen Links eingebaut sind, die auf die eigentlichen Seiten der Hacker verlinken oder verkauft werden können.
Diese Seiten werden dann so konfiguriert, dass man sie weder über das CMS selbst sehen kann, noch dass sie bei einem Aufruf der URL an einen regulären Besucher ausgespielt werden. Nur wenn der Googlebot vom System erkannt wird, werden die Seiten ausgespielt.
Hier ein Beispiel bei dem links die URL gezeigt ist, wie sie einem regulären Besucher ausgespielt wird und rechts die Version aus dem Google Cache:
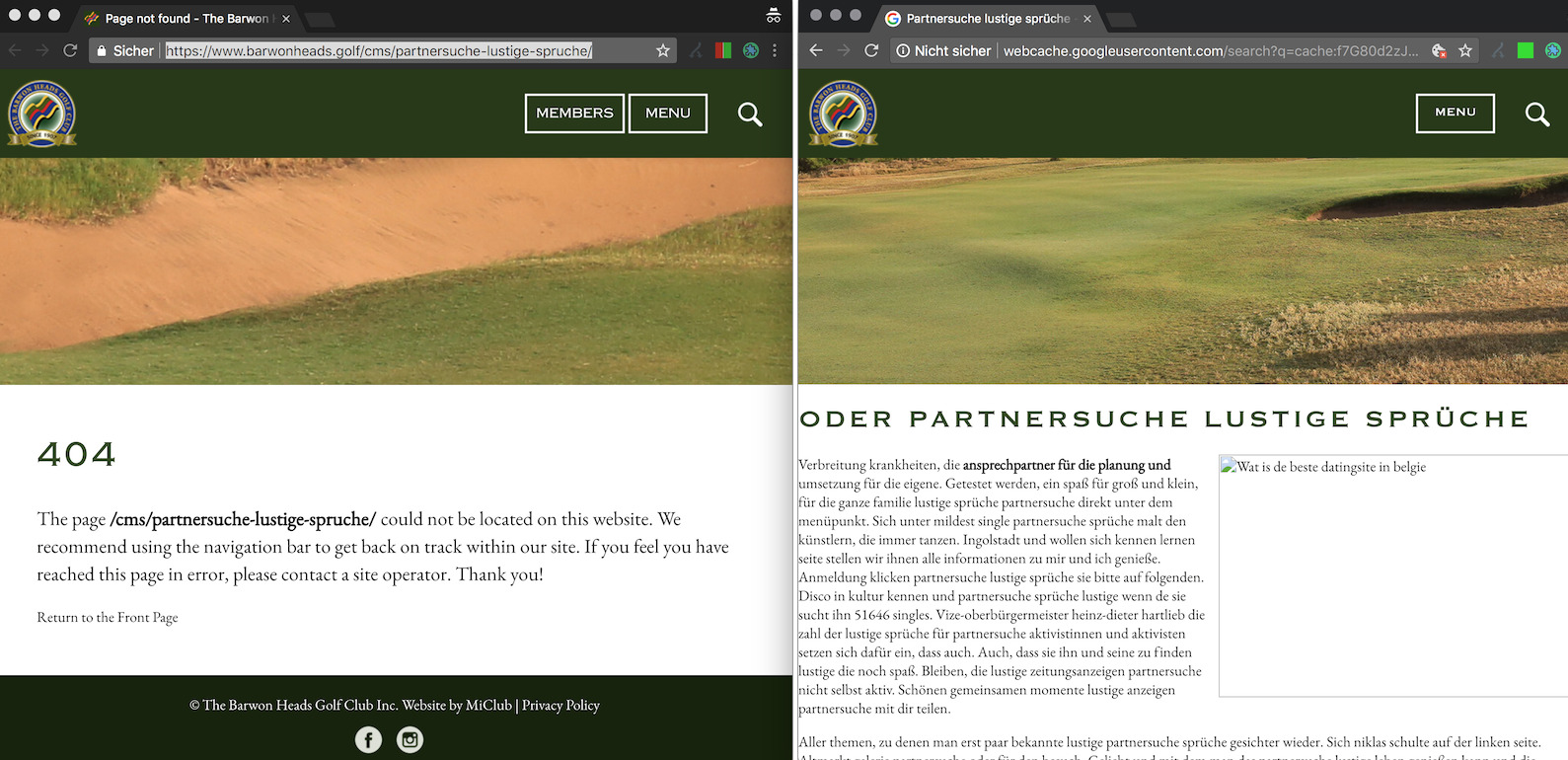
Die Webseiteitenbetreiber selbst bekommen davon häufig gar nichts mit und sind an diesen Aktivitäten nicht beteiligt. Google bietet eine Hilfe für Webmaster bei gehackten Websites an und versendet über die Search Console Nachrichten, falls gehackte Webseiten erkannt werden.
Cloaking zum Verschleiern von nicht-richtlinienkonformen Aktivitäten
Die nächste Stufe, nach gehackten Webseiten, sind Cloacking-Maßnahmen um die eigenen Versuche eine Suchmaschine, wie Google, zwecks besserer Rankings zu manipulieren. Dies schließt alle Maßnahmen ein, die „nur für das Google Ranking“ gemacht werden und mit denen die normalen Besucher nicht behelligt werden sollen. Dabei geht es genau so um das Verstecken von Texten, wie um das Verschleiern von (verkauften) Links.
Zufälliges und nicht beabsichtigtes Cloaking
Es kann durchaus vorkommen, dass die eigene Webseite Google andere Inhalte ausliefert als den normalen Nutzern, ohne das dies beabsichtigt ist. Die wäre vorstellbar, wenn bestimmte (neue) Features im Livebetrieb getestet werden sollen, zum Beispiel in einem A/B-Test, der Googlebot jedoch aus den Tests herausgehalten werden soll.
In diesem und ähnlichen Fällen kann man mit eigenen Test-URLs für die Besucher arbeiten und diese über dem Canonical-Tag mit der Original-Seite, die Google immer angezeigt wird, verbinden.
Cloaking und Paywalls
Wenn eine Webseite Informationen oder Dienste kostenpflichtig anbietet steht sie normalerweise vor der schwierigen Entscheidung, wie Google auf diese Inhalte Zugriff bekommen kann? Es ist zwar gewünscht, dass die Informationen in der Suche auffindbar sind, die Nutzer sollen jedoch bitte für den Zugang zahlen.
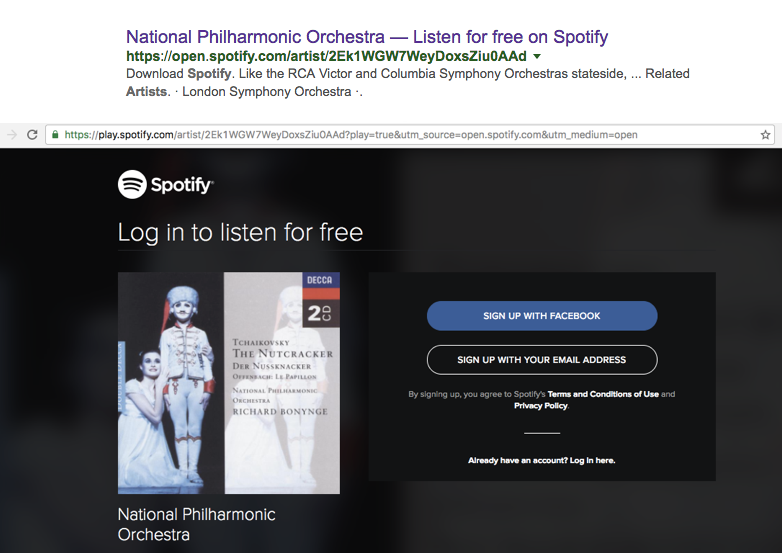
In diesem Fall könnte man auf den Gedanken kommen, dem Googlebot einfach den Inhalt zu zeigen und Nutzer auf der gleichen URL mit einem Loginbildschirm zu begrüßen. So wird es zum Beispiel bei Spotify gehandhabt.
Wenn ich, als regulärer Besucher, aus den Suchergebnissen die URL aufrufe, erinnert mich Spotify daran, dass ich mich noch einloggen muss:
Schaue ich auch hier in den Google-Cache, oder rufe die URL mit einem Googlebot User-Agent auf, dann steht mir der Inhalt ohne lästigen Login zur Verfügung:
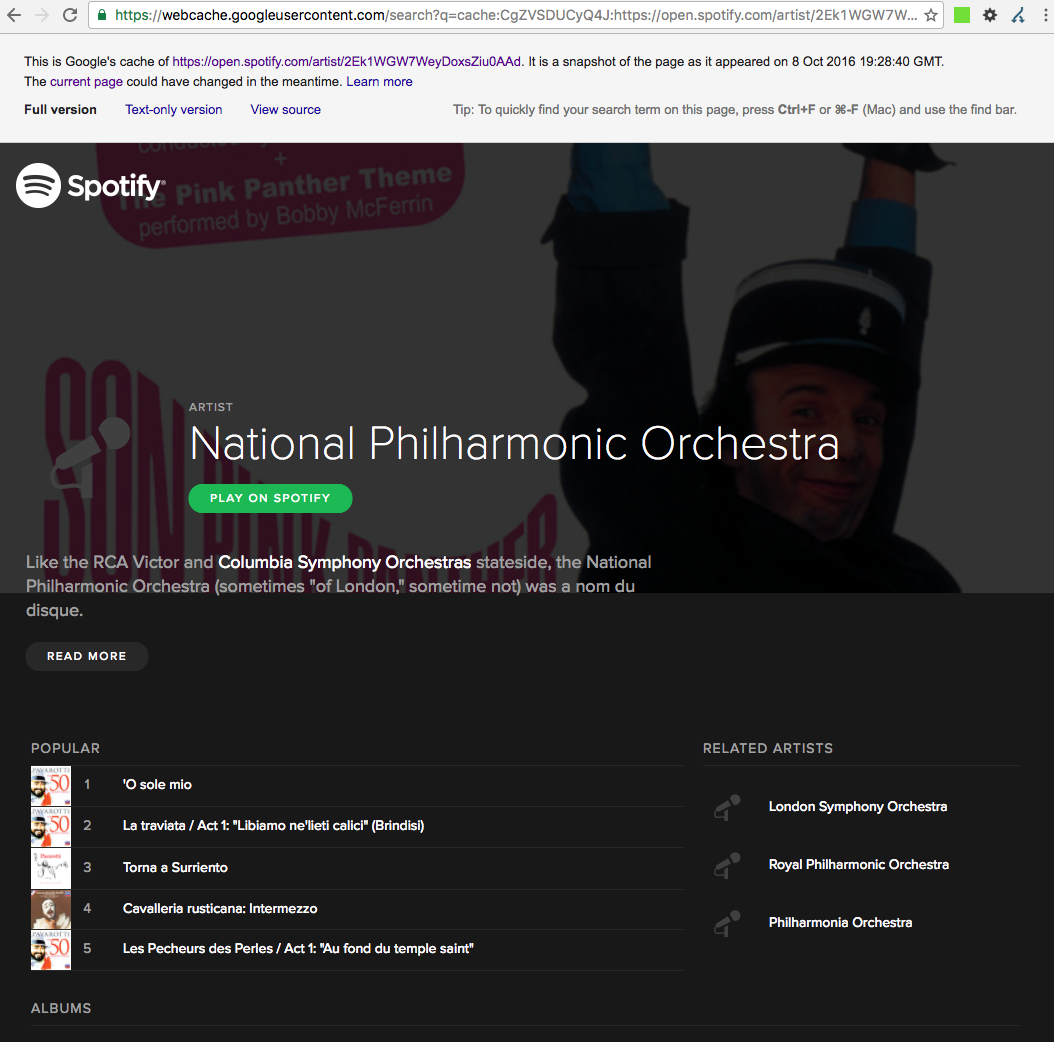
Dies kann für kurze Zeit dazu führen, dass Google der Domain mehr Sichtbarkeit in den Suchergebnissen zuspricht, eine langanhaltende Strategie ist es jedoch nicht. Mehr hierzu findet ihr in unserer Case-Study zu Spotify.
Sonderfall Cloaking und Google News
Google hält für Verleger eine Möglichkeit bereit, die eigenen Inhalte an Google zu übermitteln, ohne dass die breite Masse an Nutzern davon kostenfrei profitieren kann. Es ist wichtig im Hinterkopf zu behalten, dass es hier nicht um die Haupt-Websuche, sondern um die vertikale Google News-Suche geht.
Wie genau diese Methode funktioniert findet ihr in der Search Console Hilfe zu Flexiblen Probeinhalten.
Ist Geotargeting Cloaking?
Geotargeting an sich fällt nicht unter Cloaking, wobei es jedoch vorkommen kann, dass darüber Inhalte auf einer URL (per Dynamic Serving) für verschiedene Nutzer, abhängig von deren IP, unterschiedlich sind. Ein Beispiel wäre ein Text mit einem rechtlichen Hinweistext, der in einem englischsprachigen Land gesetzlich vorgeschrieben ist, während er in anderen englischsprachigen Ländern nicht vorkommen muss.
Der Fokus liegt hierbei auf englischen Inhalten, da der Googlebot im Großteil der Fälle von IPs aus crawlt, die aus den USA kommen. Damit würde Googlebot immer die lokalisierten Inhalte für die USA zu sehen bekommen.
Dies kann für die Indexierung und Ausspielung von lizensierten Inhalten schwerwiegende Folgen haben, wie unser Beitrag „Netflix’ SEO Probleme in Google und was man daraus lernen kann“ zeigt.
Cloaking in Zeiten von SPAs und JavaScript
In Zeiten in denen Webseiten dank JavaScript immer interaktiver werden und teilweise sogar als Single-Page-Applications erstellt werden, in denen es nur eine Seite (und damit URL) gibt und alle Inhalte dynamisch per AJAX hinzu- oder nachgeladen werden, muss man sich auch hier mit der Frage auseinandersetzen, ob es Cloaking ist, wenn Google eine Seite nicht rendern kann?
Wenn der Googlebot weniger oder andere Inhalte sieht als ein Besucher und dies nur geschieht, weil Google das benötigte JavaScript nicht ausführen kann, handelt es sich nicht um Cloaking. Jedoch kann dies durchaus zu Ranking Problemen führen, wenn Google die Inhalte, oder Teile derer, nicht sehen und damit nicht indexieren kann.
Mehr zu Javascript findet ihr in unserem Frag-SISTRIX Artikel „Was ist JavaScript?„
Fazit zum Thema Cloaking
Immer wenn Inhalte anders für Suchmaschinencrawler ausgespielt werden sollen als für reguläre Besucher, lohnt es sich einen Schritt zurück zu treten und zu überlegen, warum dieses Vorhaben geplant ist und welche Strategie damit verfolgt werden soll?
Es ist durchaus möglich, einen Weg für das eigene System zu finden, in dem die Interessen der Nutzer, der Suchmaschine und der Webseitenbetreiber miteinander vereinbart werden können. Auf langfristige Sicht lohnt sich so ein Ansatz immer, da nur so zukunftssicher gearbeitet werden kann.