
Ein Large Language Model, kurz LLM, ist ein auf maschinellem Lernen basierendes Sprachmodell, das durch Training auf umfangreichen Textsammlungen in der Lage ist, Eingaben in natürlicher Sprache zu analysieren, darauf zu reagieren und eigenständig kohärente, kontextbezogene Texte zu generieren.
Large Language Models sind computergestützte Systeme, die Sprache in großem Maßstab verarbeiten: Sie analysieren sprachliche Muster in Texten und erzeugen anhand statischer Wahrscheinlichkeiten Inhalte, die für menschliche Leser oft überzeugend wirken auch wenn das Modell den Inhalt selbst nicht “versteht”.
Kennzeichnend ist, dass sie mit enormen Datenmengen trainiert werden, Texte aus Büchern, Webseiten, Artikeln, Kommentaren usw. und dabei lernen, wie Sprache funktioniert: Grammatik, Stil, Kontext, Bedeutung und Zusammenhänge. Das heißt aber nicht, dass Sprachmodelle alles wissen, sie wurden nur mit sehr großen Mengen menschlichen Wissens gefüttert und können auch nur aus diesen Informationen schöpfen.
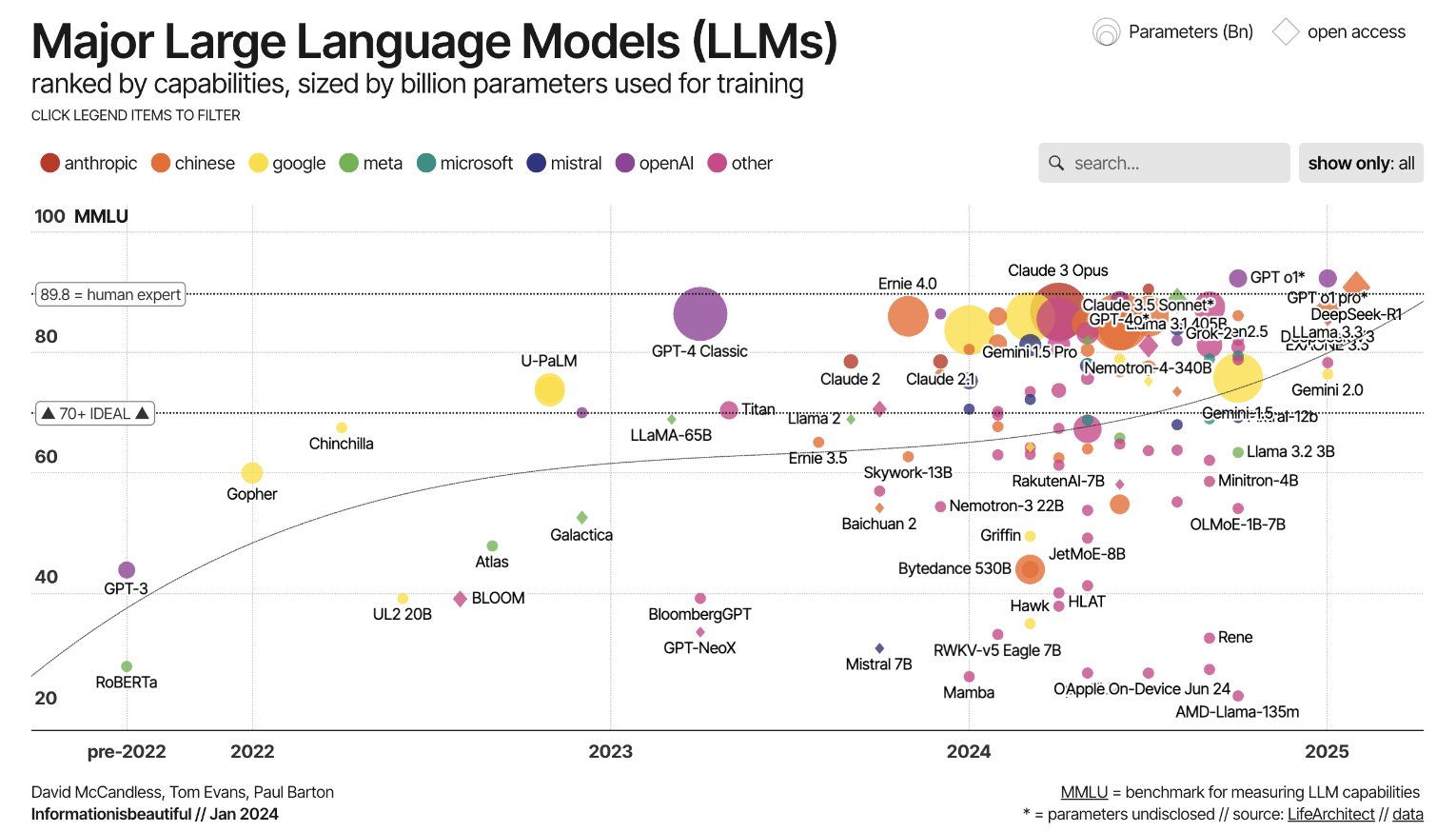
Die Entwicklung von Sprachmodellen begann mit einfachen, regelbasierten Systemen, die nur begrenzte Zusammenhänge erkennen konnten. Später kamen Modelle hinzu, die mit Hilfe künstlicher Intelligenz lernten, Sprache besser zu verarbeiten. Diese frühen neuronalen Netzwerke brachten erste Fortschritte, waren aber noch nicht besonders leistungsfähig, wenn es um längere Texte oder komplexe Zusammenhänge ging.
Der eigentliche Durchbruch kam mit der sogenannten Transformer-Architektur im Jahr 2017. Sie machte es möglich, sehr große Datenmengen effizient zu verarbeiten und dabei auch längere Textzusammenhänge zu erfassen. Auf dieser Basis entstanden die heutigen Large Language Models, die deutlich leistungsfähiger, flexibler und umfangreicher sind als ihre Vorgänger.
Die Transformer‑Architektur spielt daher eine zentrale Rolle: Sie erlaubt, dass das Modell nicht nur lokal an einer Stelle schaut, sondern alle Teile eines Textes in Beziehung zueinander setzen kann (Selbst-Attention). Damit lassen sich Sprachkontexte wesentlich umfassender erfassen, Mehrdeutigkeiten besser auflösen, Stil und Kontext korrekter anwenden. Die Modernisierung hin zu LLMs beinhaltet also nicht nur mehr Daten und Rechenleistung, sondern auch fundamentale Verbesserungen in der Modellarchitektur.
Funktionsweise und Technologie

Training und Daten
Das Training eines LLM beginnt typischerweise mit einer Pre‑Training-Phase, vergleichbar mit der Grundschule. Dabei werden große, breit gestreute Textkorpora verwendet ‒ aus Büchern, wissenschaftlichen Veröffentlichungen, Nachrichten, Foren etc. Ziel in dieser Phase ist nicht, eine spezielle Aufgabe zu lösen, sondern Sprachmuster zu lernen: Wie konstruieren Menschen Sätze? Wie verbinden sie Gedanken? Wie wird Bedeutung erzeugt über Wörter hinweg? Diese Phase ist selbstüberwacht: Das Modell versucht, etwa vorherzusagen, welches Wort als Nächstes kommt, oder Teile eines Satzes zu rekonstruieren.
Nach dem Pre‑Training folgt häufig eine Phase des Fine‑Tuning, bei der das Modell auf bestimmte Aufgaben oder Domänen angepasst wird. Beispielsweise kann ein LLM so trainiert werden, dass es besonders gut juristische Texte versteht, medizinische Konversationen unterstützt oder als Chatbot mit Kunden interagiert. Außerdem kommen Techniken wie Instruction Tuning zum Einsatz, bei denen das Modell lernt, auf bestimmte Anweisungen oder Stilvorgaben zu reagieren, und Reinforcement Learning from Human Feedback (RLHF), bei dem menschliches Feedback genutzt wird, um die Qualität, Verständlichkeit und Sicherheit der Ausgaben zu verbessern.
Architektur
Die meisten modernen Sprachmodelle basieren auf der sogenannten Transformer-Architektur. Sie ermöglicht es dem Modell, alle Wörter eines Textes gleichzeitig zu betrachten und ihre Beziehungen zueinander zu erkennen. Ein zentraler Bestandteil dabei ist das sogenannte „Attention“-Verfahren: Es hilft dem Modell zu entscheiden, welche Wörter in einem Satz besonders wichtig sind, um den Zusammenhang zu verstehen. Dadurch kann das Modell nicht nur einzelne Begriffe, sondern auch Bedeutung und Struktur eines Textes erfassen.
Wie leistungsfähig ein Modell ist, hängt unter anderem von der Anzahl seiner Parameter ab. Dabei handelt es sich um die einstellbaren Werte, mit denen das Modell Sprache lernt. Je mehr Parameter ein Modell hat, desto komplexere Zusammenhänge kann es abbilden – aber auch desto größer ist der technische Aufwand beim Training und Einsatz.
Eine weitere wichtige Eigenschaft ist die sogenannte Kontextlänge: Sie bestimmt, wie viel Text das Modell auf einmal berücksichtigen kann. Bei kurzen Kontexten verliert das Modell schnell den Überblick über längere Passagen. Moderne Modelle hingegen verarbeiten problemlos ganze Artikel oder lange Gesprächsverläufe, ohne den roten Faden zu verlieren.
Zusätzlich gibt es LLMs, die nicht nur mit Text arbeiten, sondern auch Bilder oder andere Datentypen verarbeiten können – sogenannte multimodale Modelle. Sie können etwa ein Bild beschreiben, eine Grafik interpretieren oder auf eine Frage antworten, die sich auf eine Kombination aus Text und Bild bezieht. Das erweitert die Einsatzmöglichkeiten deutlich, etwa in der Produktbeschreibung, im Kundenservice oder bei der Analyse visueller Inhalte.
Prompts als Schnittstelle
Die Nutzung von LLMs basiert auf sogenannten Prompts. Ein Prompt ist die Eingabe, die ein Nutzer an das Modell richtet, etwa eine Frage, eine Anweisung oder ein Textausschnitt. Das Modell verarbeitet diesen Prompt und erzeugt daraufhin eine passende Antwort. Schon kleine Unterschiede in der Formulierung können die Ausgabe stark verändern. Über Prompts können auch große Datenmengen eingegeben werden, etwa Texte, die überarbeitet oder übersetzt werden sollen.
Sichtbarkeit in LLMs mit SISTRIX messen
LLMs wie ChatGPT, Gemini und DeepSeek verändern, wie Menschen Informationen finden und wie Marken sichtbar werden. Immer mehr Suchanfragen, die früher zu Website Klicks geführt haben, werden inzwischen von Chatbots, KI Suchmaschinen oder auch den Google AI Overviews direkt beantwortet. Das bedeutet weniger Klicks und verändert die entscheidenden KPIs. Was früher Seitenaufrufe und Klicks waren, sind in den neuen Systemen Zitationen und Verlinkungen in den Antworten der KI.
Um diese Kennzahlen zu messen, gibt es bei SISTRIX die AI/Chatbot Beta. Damit lässt sich leicht überprüfen, in welchen Chatbots eine Marke genannt wird, bei welchen Prompts die eigene Entität erscheint und wo stattdessen nur Wettbewerber sichtbar sind.
Trotzdem laufen die meisten Suchanfragen weiterhin über Google und daran wird sich so schnell nichts ändern. Viele Strategien, die für klassische SEO gelten, sind auch im Umfeld der neuen LLMs der richtige Weg.

Tracke die Sichtbarkeit deiner Marke auch in den neuen Suchsystemen, überprüfe, wie sichtbar du schon bist und wo es noch ungenutzte Potenziale gibt. Teste SISTRIX 14 Tage kostenlos und optimiere deine Inhalte schon jetzt für eine neue Ära der Websuche.
Typische Anwendungsbereiche von LLMs
LLMs finden in vielen Feldern Anwendung, teils in alltäglichen, teils in spezialisierten Szenarios.
Die automatische Generierung von Texten ist einer der offensichtlichsten Einsatzbereiche. Sei es für Blogbeiträge, Marketingtexte, E-Mails oder kreativer Content wie Geschichten und Gedichte: LLMs können Inhalte erstellen oder zumindest Entwürfe liefern, die menschliche Bearbeitung erleichtern und beschleunigen.
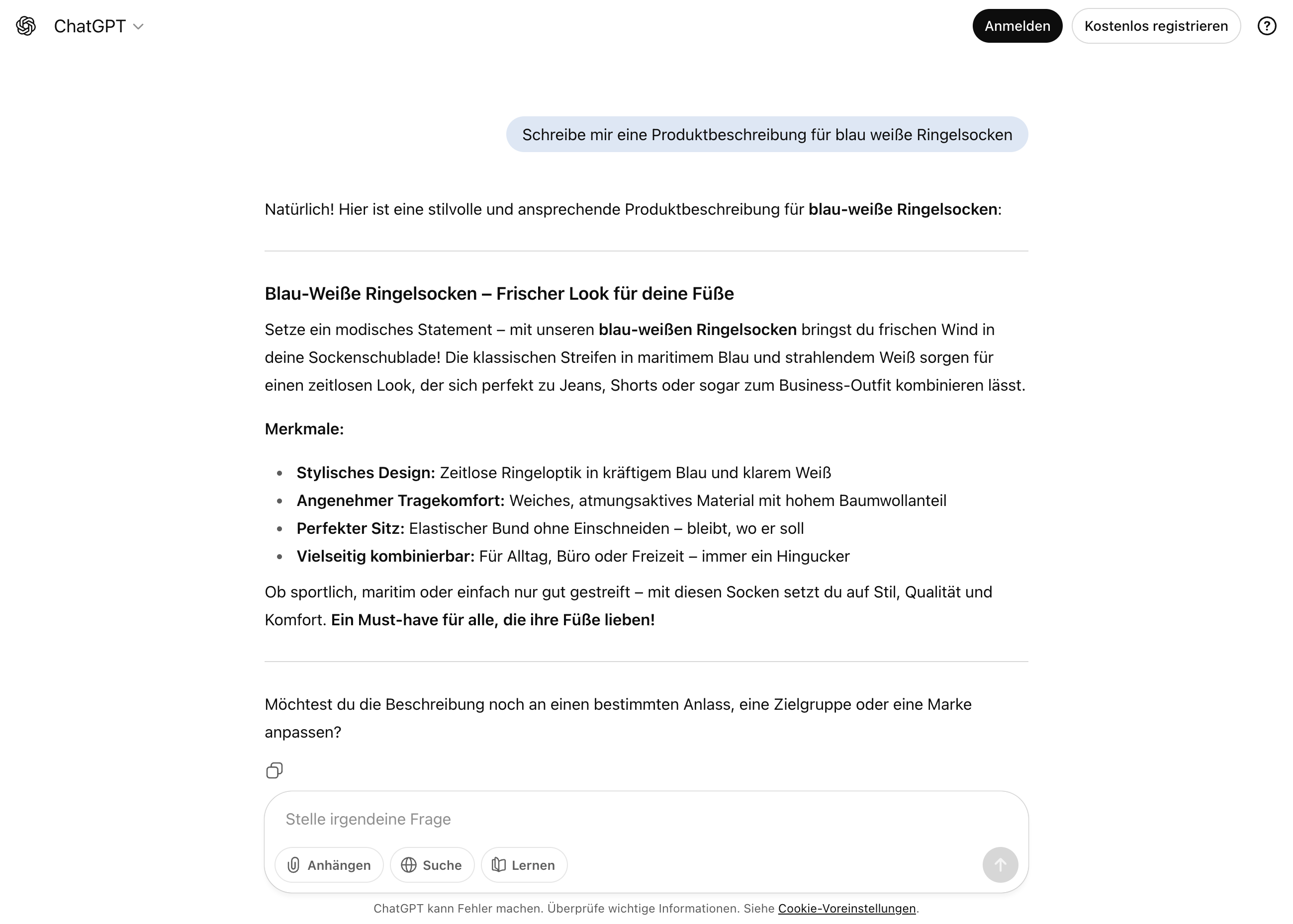
In der Kommunikation mit Nutzern werden LLMs als Chatbots oder virtuelle Assistenten eingesetzt. Sie beantworten Fragen, geben Empfehlungen, führen Dialoge und können Support leisten. Damit verbessern sie die Nutzererfahrung und ermöglichen Skalierung, etwa im Kundenservice.
Auch bei der Verarbeitung großer Informationsmengen spielen LLMs eine wichtige Rolle. Sie können Texte zusammenfassen, Kernaussagen aus langen Dokumenten extrahieren, komplexe Fragen beantworten oder Informationen strukturieren. In Wissenschaft, Forschung, Unternehmensdokumentation oder bei Rechtsgutachten etwa sind solche Fähigkeiten wertvoll.
Zusätzlich werden LLMs eingesetzt zur Datenanalyse und Klassifikation: Emotionserkennung (Sentiment Analysis), Themencluster, Einordnung von Texten nach Themen oder Richtungen, auch Identifizierung von Meinungen, Trends oder Risiken in Social Media oder Nutzerfeedback.
Manche LLMs sind spezialisiert für bestimmte Domänen wie Medizin, Recht oder Finanzen. Dort gelten oft strengere Anforderungen an Genauigkeit, Nachvollziehbarkeit und Zuverlässigkeit.
Ein wachsender Anwendungsbereich ist zudem die Integration von LLMs in Suchmaschinen. Anstatt nur Listen von Links zu liefern, generieren sie direkte, sprachbasierte Antworten auf Suchanfragen. Aus Suchmaschinen werden Antwortmaschinen. Damit entsteht eine neue Form der Informationssuche, bei der nicht mehr die Navigation zu Inhalten, sondern die sofortige Verständlichkeit und die einfache Usablity im Vordergrund steht. Die Modelle agieren hier als Schnittstelle zwischen Nutzer und Wissen und verändern grundlegend, wie Suchergebnisse wahrgenommen und verarbeitet werden.

Herausforderungen und Risiken
So leistungsfähig LLMs sind, sie bringen auch einige Risiken mit sich.
Ein Grundproblem ist das fehlende Grounding: Sprachmodelle berechnen Wahrscheinlichkeiten, haben aber kein Verständnis für die reale Welt. Auch wenn Systeme mit Webanbindung wie ChatGPT oder Gemini aktuelle Informationen aus Webseiten einbeziehen, prüfen sie keine Fakten, sondern erzeugen weiterhin Antworten auf rein sprachlicher Basis.
Daraus resultieren Bias und Halluzinationen. Verzerrungen in den Trainingsdaten führen zu diskriminierenden oder stereotypen Ausgaben, während Halluzinationen scheinbar plausible, aber falsche Informationen erzeugen können, mit potenziell gravierenden Folgen in sensiblen Bereichen wie Medizin oder Recht. LLM können Fakten nicht korrekt einordnen und beantworten jeden Prompt, selbst wenn dieser bereits fehlerhaft oder mit Bias formuliert ist.
Ein weiteres Risiko sind Prompt Injections. Hierbei versuchen Angreifer, Modelle über präparierte Eingaben oder manipulierte Webseiten dazu zu bringen, Sicherheitsvorgaben zu umgehen oder vertrauliche Daten preiszugeben. Diese Angriffe sind besonders schwer abzusichern, da sie nicht den Code, sondern die Sprachebene selbst betreffen.
Auch der ökologische Fußabdruck ist erheblich: Training und Betrieb großer Modelle verbrauchen enorme Mengen an Energie und Rechenressourcen.
Hinzu kommen rechtliche Unsicherheiten, etwa Fragen nach Urheberrecht, Datenschutz und Eigentum an generierten Texten. Schließlich besteht auch das Risiko des Missbrauchs: LLMs können zur Verbreitung von Desinformation, Spam oder manipulativen Inhalten eingesetzt werden.
Die Chancen dieser Technologie sind in einigen Bereichen groß, doch nur mit klaren Regeln, Transparenz und Forschung lassen sich diese Risiken beherrschen.
Beispiele bekannter Large Language Models
Zu den bekanntesten LLMs gehören folgende:
- GPT‑Modelle (OpenAI) zählen zu den meistgenutzten. Sie bieten starke Leistung in generativer Sprachproduktion und haben eine breite Unterstützung durch Tools, Integrationen und Community‑Ressourcen.
- LLaMA‑Modelle (Meta) sind häufig offen (zumindest in Teilen), werden in der Forschung und in spezialisierten Einsatzszenarien genutzt und ermöglichen Anpassungen an bestimmte Anforderungen.
- Gemini (Google DeepMind) ist eine Modellfamilie, die seit Dezember 2023 existiert und als Nachfolger von LaMDA und PaLM gilt. Gemini umfasst Varianten wie Gemini Ultra, Gemini Pro, Gemini Flash und Gemini Nano. Es handelt sich um multimodale Modelle, also solche, die neben Text auch andere Modalitäten wie Bilder verarbeiten können. Eine besonders bemerkenswerte Eigenschaft von Gemini ist das sehr große Kontextfenster.
- Claude (Anthropic) – ein Sprachmodell, das seit 2023 entwickelt wird. Es basiert auf dem Ansatz der „Constitutional AI“, bei dem das Verhalten des Modells über ein festgelegtes Regelwerk gesteuert wird. Claude ist in mehreren Generationen erschienen (Claude 1, 2 und 3) und wird fortlaufend weiterentwickelt.
LLM und Suchmaschinen
Mit der zunehmenden Leistungsfähigkeit von LLMs stellt sich eine zentrale Frage, die derzeit intensiv diskutiert wird: Ersetzen Large Language Models klassische Suchmaschinen?
Traditionelle Suchmaschinen wie Google oder Bing basieren im Kern auf dem Crawlen, Indizieren und Bewerten von Webseiten. Nutzer geben Suchbegriffe ein, erhalten eine Ergebnisliste und klicken sich zu relevanten Inhalten durch. Diese Interaktion ist informationsorientiert, aber fragmentiert: Der Nutzer bleibt dafür verantwortlich, Informationen zu filtern, Quellen zu prüfen und Inhalte selbst zusammenzuführen.
LLMs hingegen bieten eine direkte, sprachbasierte Schnittstelle, was die Usability einfacher macht. Sie liefern keine Linklisten, sondern (vermeintlich) fertige Antworten ‒ oft mit Zusammenfassungen, Argumenten oder Kontext. Die Nutzererfahrung verändert sich: Statt „Finde Informationen über X“ steht nun „Erkläre mir X“ im Vordergrund. Damit verschiebt sich die Aufgabe vom „Suchen“ hin zum „Verstehen“. In vielen “eindeutigen” Szenarien, also bei Fragen für die es nur eine richtige Antwort gibt ‒ etwa bei einfachen Wissensfragen, Begriffserklärungen oder Handlungsanleitungen ‒ ersetzen LLMs die klassische Websuche bereits heute nahezu vollständig.
Das verändert auch das Verhalten der Anbieter. Google integriert mit seinen AI Overviews (deutsch: Übersicht mit KI) seit März 2025 LLM-Komponenten direkt in die Suchergebnisse, zeigt KI-generierte Antworten über den klassischen Treffern an und experimentiert mit dialogbasierten Interfaces. Bing hat mit der Integration von GPT‑Technologie in „Bing Chat“ früh einen ähnlichen Schritt gemacht und damit Google unter Zugzwang gesetzt. Auch Startups wie Perplexity.ai setzen vollständig auf eine LLM‑gestützte Sucherfahrung, die Quellen einbezieht, aber primär über Sprache vermittelt.
Gleichzeitig bleiben klassische Suchmaschinen relevant, insbesondere in Bereichen, in denen Quellenkontrolle, Aktualität und Transparenz entscheidend sind. LLMs generieren zwar flüssige Antworten, liefern aber nicht immer überprüfbare Belege oder aktuelle Inhalte. Gerade bei tagesaktuellen Themen, komplexen Recherchen oder rechtsverbindlichen Informationen ist die Suche über verlinkte Quellen nach wie vor unverzichtbar.
Langfristig zeichnet sich eine Hybridisierung ab: Suchmaschinen und LLMs wachsen zusammen. Der Nutzer erhält KI-generierte Antworten mit Quellenangaben, kann aber gleichzeitig tiefer recherchieren, kontextualisieren oder überprüfen. Diese Entwicklung ist keine Verdrängung, sondern eine Neuausrichtung des Suchprozesses, vom Klickmodell zur Dialogstruktur, von der URL-Liste zur Antwort auf Augenhöhe.
Für SEO bedeutet das: Inhalte müssen nicht nur maschinenlesbar, sondern auch „modellverständlich“ werden. Struktur, Klarheit, Autorität und Kontext gewinnen zusätzlich an Bedeutung. Gleichzeitig müssen SEOs sich darauf einstellen, künftig deutlich weniger Reichweite zu erzeugen, da bei vielen KI-Antworten zu Fragen mit nur einer richtigen Antwort keine Klicks mehr notwendig sind. Das heißt aber nicht, dass es keine Klicks mehr über SEO gibt.
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten