
Das Stadtportal stuttgart.de gehört mit einem Rückgang von 65 Prozent zu den fünf Verlierern der Woche im SISTRIX Sichtbarkeitsindex. Schon in der Vorwoche war die Sichtbarkeit stark eingebrochen und seit dem 15.04.2013 ist der Sichtbarkeitsindex von 14,95 Punkte auf 2,79 Punkte (-81 Prozent) gefallen. Was ist los im Ländle?
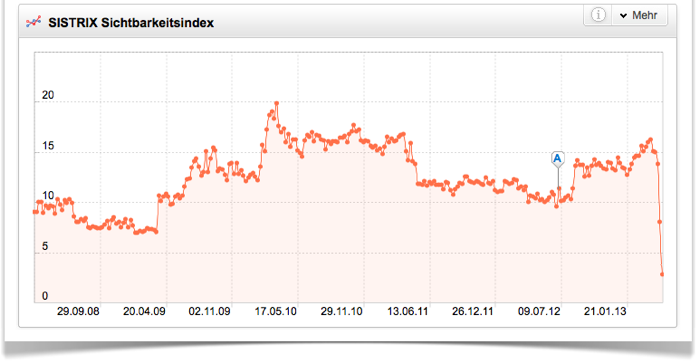
Entwicklung SISTRIX Sichtbarkeitsindex stuttgart.de
Für ein offizielles und gut verlinktes Stadtportal mit exklusivem Content ist ein solcher Einbruch ungewöhnlich. Eine Google Penalty würde man daher nicht zu allererst als Ursache vermuten. Ein Blick auf die weggefallenen Keywords der letzten Woche zeigt, dass ein größeres Problem vorliegen muss, wenn stuttgart.de für Keywords wie z.B. „museum stuttgart“, „theater stuttgart“ und „schule stuttgart“ von Platz 1 komplett aus den Top-100 fällt.

Auszug aus der Liste der Keywords, bei denen stuttgart.de in der vergangenen Woche aus den Top-100 gefallen ist
Um die Website zu überprüfen, haben wir stuttgart.de daher mit dem SISTRIX Optimizer überprüft und 10.000 Seiten crawlen lassen. Bei der Optimizer-Auswertung fällt sofort die hohe Anzahl von 519 Serverfehler auf.
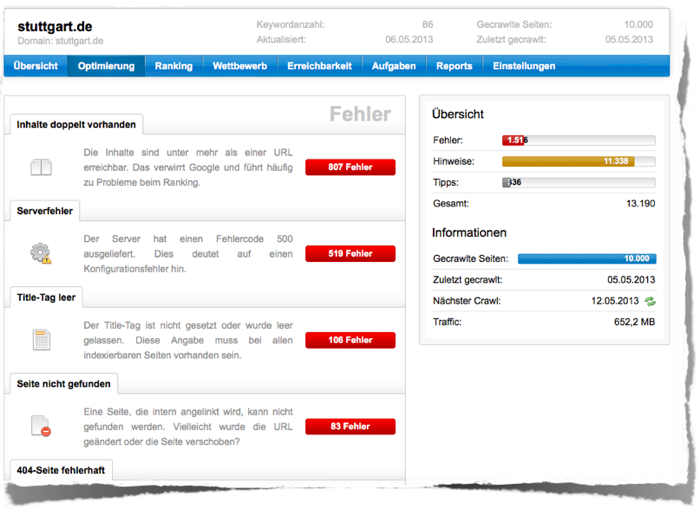
Auszug SISTRIX Optimizer Analyse stuttgart.de
In der Detailansicht sehen wir, dass der Server sehr häufig den HTTP-Status-Code 503 (Service Unavailable) ausliefert. Ruft man eine einzelne dieser Seiten manuell auf, ist dieses Problem hingegen nicht zu beobachten. Dieses Verhalten des Servers scheint nur beim Crawlen einer größeren Anzahl Seiten aufzutreten. Es ist zu vermuten, dass auch der Googlebot auf die gleichen Probleme stößt. Das wäre auch eine plausible Erklärung dafür, warum stuttgart.de für seine ureigensten Keywords komplett aus den Rankings verschwindet.
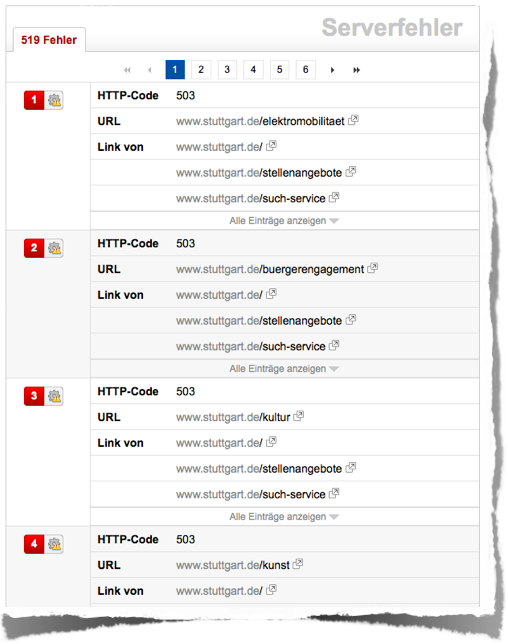
Auszug aus der Liste der Serverfehler von stuttgart.de
Suboptimal ist sicherlich auch die Tatsache, dass man alle URLs sowohl mit http als auch mit https aufrufen kann und dass viele URLs zu viele Parameter beinhalten. Diese SEO-Schwächen liegen aber wahrscheinlich schon länger vor und dürften für den aktuellen Absturz nicht verantwortlich sein.
In der robots.txt von stuttgart.de wird eine lange Liste von Crawlern ausgeschlossen. Das bestätigt die Vermutung, dass die sparsamen Schwaben eventuell auch mit den 503-Statuscodes datenhungrige Crawler sperren wollen, dabei aber nicht die Auswirkungen auf die Google-Rankings beachtet haben.
Damit hätten wir einen ähnlichen Fall wie bei apple.com vor ein paar Wochen mit dem einzigen Unterschied, dass der Server dort bei intensivem Crawling 403- anstatt 503-Statuscodes ausgeliefert hat. Die Domain apple.com hat sich übrigens inzwischen wieder gut erholt und kratzt aktuell an der 200-Punkte-Linie im Sichtbarkeitsindex.