
Mit der zunehmenden Integration von KI in die Google-Suche verändert sich nicht nur, wie Inhalte präsentiert werden, sondern auch, wie sie ausgewählt werden. Während klassische Suchsysteme primär Dokumente ranken, müssen KI-gestützte Antwortsysteme eine begrenzte Auswahl von Quellen treffen, die gemeinsam möglichst viel relevante Information liefern.
Ein aktuelles Forschungs-Paper von Google Research stellt mit GIST (Greedy Independent Set Thresholding) einen Algorithmus vor, der genau dieses Problem adressiert: die Auswahl einer informationsreichen, nicht redundanten Teilmenge aus großen Datenmengen.
Ob und in welcher Form GIST konkret in der Google-Suche oder in den AI Overviews eingesetzt wird, ist öffentlich nicht bestätigt. Das Paper liefert jedoch einen klaren Einblick in ein zentrales Optimierungsproblem moderner KI-Systeme: Wie lassen sich redundante Inhalte vermeiden, ohne relevanten Informationswert zu verlieren?
Unabhängig von einer konkreten Implementierung zeigt GIST damit, in welche Richtung sich Auswahlmechanismen von Suchmaschinen entwickeln könnten, weg vom reinen Ranking einzelner Dokumente, hin zur kuratierten Zusammenstellung komplementärer Informationsquellen.
Für SEO bedeutet das: Nicht nur Qualität zählt, sondern der zusätzliche Informationsgewinn, den ein Inhalt im Vergleich zu bereits vorhandenen Quellen bietet.
Was ist GIST?
GIST („Greedy Independent Set Thresholding”) ist ein Algorithmus zur Auswahl einer Teilmenge von Daten aus einem großen Datensatz. Er wurde von Forschern bei Google Research entwickelt und auf der Konferenz NeurIPS 2025 vorgestellt. Ziel ist es, große Datenmengen so zu reduzieren, dass möglichst viel Information erhalten bleibt, ohne redundante Inhalte zu berücksichtigen.
Die zentrale Fragestellung lautet:
Welche Datenpunkte liefern gemeinsam möglichst viel Information, ohne sich gegenseitig zu wiederholen?
Dazu kombiniert GIST zwei mathematische Konzepte:
- Diversity: Beschreibt den Abstand zwischen Datenpunkten. Inhalte gelten als divers, wenn sie sich semantisch deutlich voneinander unterscheiden.
- Utility: Beschreibt den Informationswert eines Datenpunkts im Kontext der bereits gewählten Inhalte. Entscheidend ist nicht nur, ob ein Inhalt „gut“ ist, sondern ob er komplementär nützlich ist, also neue Aspekte, Daten oder Perspektiven ergänzt, die im bestehenden Set noch fehlen.
Beispiel: Zehn Wanderführer beschreiben denselben Weg auf einen Berg. Neun davon erklären Route, Dauer und Schwierigkeitsgrad nahezu identisch. Einer ergänzt jedoch aktuelle Wetterdaten, alternative Zustiege und persönliche Erfahrungswerte.
GIST wählt nicht „den besten von zehn“, sondern erkennt, dass neun inhaltlich redundant sind und entscheidet sich für den einen, der dem bestehenden Informationsraum tatsächlich etwas Neues hinzufügt.
So entsteht eine Auswahl, die sowohl breit gefächert als auch inhaltlich relevant ist.
In der Praxis bedeutet das: Die ausgewählten Inhalte decken ein Thema zuverlässig ab und lassen nur wenig relevante Information unberücksichtigt.
Warum ist GIST für SEO relevant?
Google hat bereits vor Jahren das Konzept des Information Gain Score patentiert. Dabei geht es darum, wie stark ein Dokument zusätzliche Informationen im Vergleich zu bereits bekannten oder gelesenen Dokumenten liefert.
GIST lässt sich als mathematisch saubere Operationalisierung genau dieses Prinzips verstehen: Nicht absolute Qualität entscheidet, sondern der zusätzliche Informationsgewinn im Kontext der bereits ausgewählten Inhalte.
Moderne Suchmaschinen und insbesondere KI-Systeme können nicht beliebig viele Inhalte gleichzeitig verarbeiten: Kontextfenster sind begrenzt und jede zusätzliche Information verursacht Rechenkosten.
In KI-gestützten Systemen ist es naheliegend, dass bereits vor der eigentlichen Verarbeitung eine Auswahl stattfinden muss. Diese Auswahl folgt zunehmend nicht mehr der klassischen Ranking-Logik, sondern einer Effizienzlogik.
Es ist naheliegend, dass redundante Inhalte in KI-gestützten Auswahlprozessen geringere Chancen haben, berücksichtigt zu werden, selbst wenn sie korrekt, gut geschrieben oder stark verlinkt sind. Damit entsteht ein neuer Filter, der vor allem KI-generierte Inhalte ausfiltert, die nur vorhandenes Wissen neu zusammenfassen, ohne neue Informationen hinzuzufügen.
Welche Quellen wählt die KI und fehlt dein Inhalt dabei?
Genau das zeigt SISTRIX für AI/Chatbots. Wir liefern dir tiefgehende Einblicke in die Sichtbarkeit von Marken, Entitäten und Quellen innerhalb der wichtigsten KI-Chatbots.
Der entscheidende Hebel für die GIST-Logik steckt in der Quellen-Analyse: Das Tool zeigt, welche Websites die AI als vertrauenswürdige Quellen nutzt, um Antworten zu deinen Themen zu formulieren. Wer dort nicht auftaucht, liefert keinen zusätzlichen Informationswert – oder wird durch redundante Inhalte schlicht aussortiert.
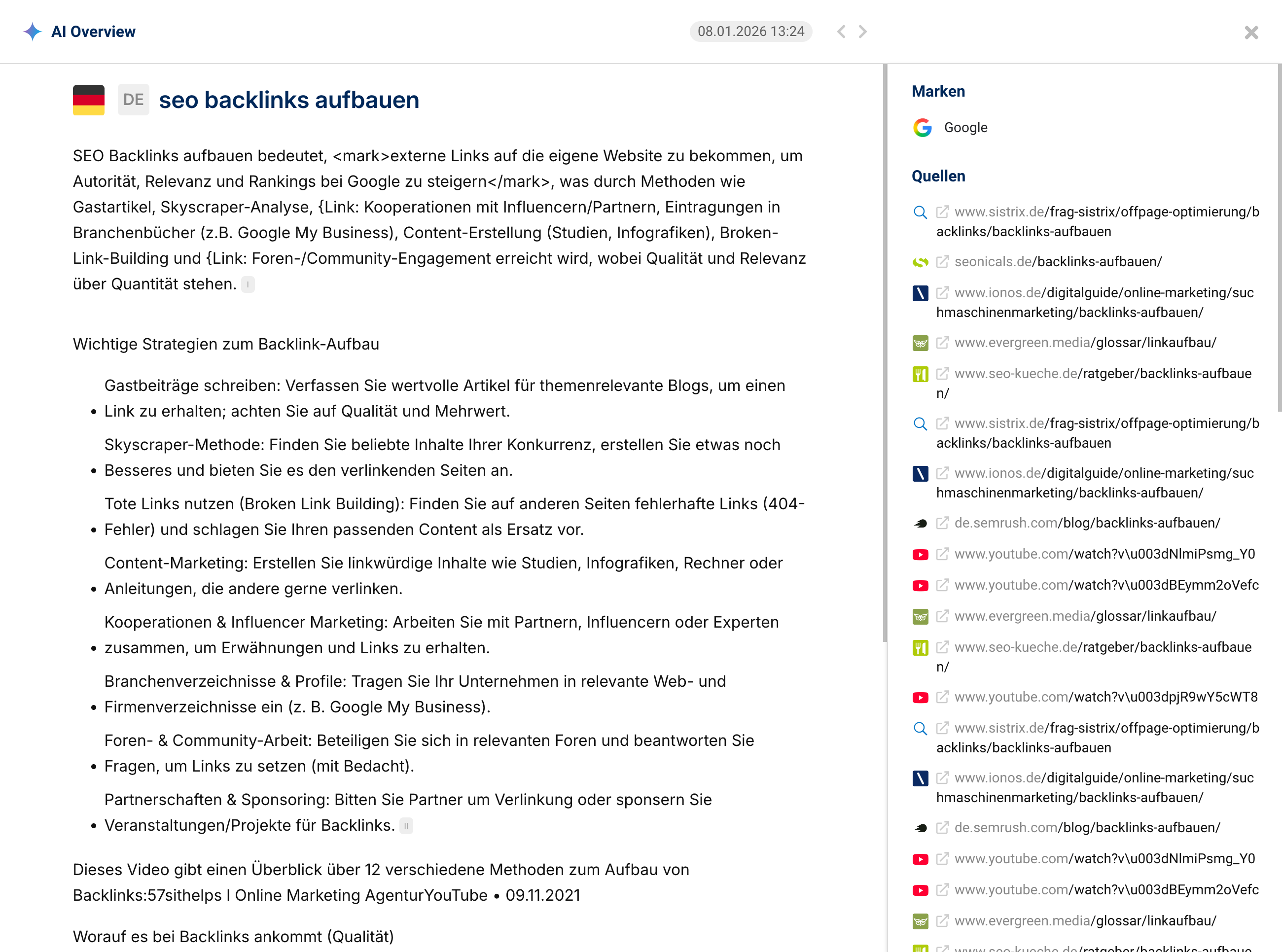
Teste SISTRIX 14 Tage kostenlos und finde heraus, ob deine Inhalte als Quelle zitiert werden oder ob deine Wettbewerber den Informationsraum bereits besetzen und es für dich noch Verbesserungspotenziale gibt.
Wie könnte GIST in der Suche wirken?
GIST ist besonders relevant in Systemen, die Inhalte aktiv auswählen müssen. Das betrifft vor allem:
- KI-generierte Antworten wie AI Overviews
- dialogbasierte Suchsysteme
- Retrieval-Prozesse für Large Language Models
- Empfehlungssysteme mit begrenzter Anzeigefläche
In all diesen Fällen entscheidet nicht mehr die Reihenfolge von Treffern, sondern die Zusammensetzung einer Auswahl von Inhalten verschiedener Quellen.
Für SEO verschiebt sich damit die zentrale Frage:
Nicht mehr „Wie komme ich auf Platz 1?“, sondern „Wie komme ich in die engere Auswahl für KI-Antworten?“
Was bedeutet das konkret für Inhalte?
Die bisherige SEO-Strategie basierte oft auf Annäherung: Inhalte wurden häufig entlang bestehender Top-Rankings strukturiert und optimiert. So entstanden mit der Zeit viele Variationen derselben Informationen ohne Neues hinzuzufügen.
Unter GIST führt genau diese Strategie zu einem Problem.
Wer sich zu stark an bestehenden Inhalten orientiert, bewegt sich innerhalb derselben semantischen Zone. Der Inhalt liefert dann keinen zusätzlichen Informationswert und wird aus der Auswahl entfernt.
Das betrifft insbesondere:
- überarbeitete Skyscraper-Inhalte
- generische SEO-Texte
- stark standardisierte Content-Templates
Diese Inhalte sind nicht falsch. Sie sind nur redundant und werden im KI-Zeitalter nicht mehr benötigt. Es braucht heute keine Inhalte mehr, die eine KI jederzeit in derselben Qualität und auf Basis derselben Informationen schreiben kann.
Handlungsempfehlungen für die Praxis
Entscheidend für die Optimierung unter GIST ist die gezielte Erweiterung des Informationsraums durch neue Erkenntnisse und Daten.
Fünf konkrete Maßnahmen lassen sich direkt ableiten:
- Analyse der bestehenden Inhalte: Untersuche die Top-Rankings nicht auf Qualität, sondern auf Abdeckung. Welche Aspekte werden behandelt und welche fehlen?
- Identifikation von Informationslücken: Suche gezielt nach Perspektiven, Datenpunkten oder Anwendungsfällen, die bisher nicht abgedeckt sind.
- Entwicklung eigenständiger Inhalte: Erstelle Inhalte, die sich strukturell und inhaltlich unterscheiden. Neue Fragestellungen sind dabei wichtiger als neue Formulierungen.
- Integration von Originaldaten und Erfahrungswerten: Eigene Analysen, Fallbeispiele oder Erfahrungswerte erhöhen den Utility-Anteil eines Inhalts deutlich. Eine Definition reicht nicht mehr aus, Erfahrungen aus der Praxis sind für Algorithmen interessanter, weil sie neue Perspektiven bringen.
- Klare Strukturierung in eigenständige Einheiten: Inhalte sollten so aufgebaut sein, dass einzelne Abschnitte als eigenständige Antworten funktionieren.
Auswirkungen auf Traffic und Sichtbarkeit
Die Einführung von Auswahlmechanismen wie GIST hat direkte Effekte auf die Performance von Websites.
Generische Inhalte verlieren künftig weiter an Reichweite, da sie seltener in KI-Antworten erscheinen und weniger häufig als Quelle genutzt werden. Alles, was KI-Chatbots bereits selbstständig korrekt beantworten können, wird künftig nicht mehr gebraucht. Das macht die inhaltliche Arbeit deutlich anspruchsvoller als bisher.
Einfache Definitionen, Glossare oder kurze oberflächliche Texte ohne E-E-A-T-Signale (Erfahrung, Expertise, Autorität, Trust) sind redundant und werden nicht mehr gebraucht.
Gleichzeitig gewinnen spezialisierte Inhalte mit Mehrwert an Bedeutung. Seiten, die eigene Perspektiven oder Daten liefern, werden häufiger ausgewählt und erreichen dadurch eine höhere Sichtbarkeit.
Langfristig führt das zu einer stärkeren Differenzierung im Markt: Wenige Inhalte erhalten sehr viel Aufmerksamkeit, während viele ähnliche Inhalte kaum noch berücksichtigt werden.
Suchmaschinen entwickeln sich von reinen Retrieval-Systemen zu kuratierten Antwortsystemen. Die Auswahl von Inhalten wird damit wichtiger als deren Reihenfolge.
Für Unternehmen bedeutet das: Content ist nicht mehr nur ein Rankingfaktor, sondern ein Bestandteil eines Auswahlprozesses. SEO bzw. GEO wird künftig viel komplexer und die Anforderungen an Web-Inhalte steigen deutlich. Einfache Antworten oder Zusammenfassungen bestehenden Wissens reichen nicht mehr aus. Wer keine neuen Antworten bietet, wird künftig nicht mehr berücksichtigt.
SEO sollte also nicht an KI-Tools oder Agenten ausgelagert werden, sondern neue Informationen produzieren, die bisher in dieser Form noch nicht zu finden sind. Und das funktioniert künftig nur noch mit Informationsvorsprung, nicht mit bereits vorhandenem Allgemeinwissen.
Je besser KI darin wird, Wissen zu reproduzieren, desto klarer wird: Der eigentliche Wettbewerbsvorteil ist das, was sich nicht einfach reproduzieren lässt: menschliche Kompetenz.
Häufige Fragen zu GIST
GIST wählt eine Teilmenge von Daten aus, die möglichst viel Information enthält und gleichzeitig keine redundanten Inhalte umfasst.
Ranking ordnet Ergebnisse, GIST reduziert die Menge der berücksichtigten Inhalte.
KI-Modelle haben begrenzte Kontextfenster. GIST hilft, nur die relevantesten und unterschiedlichsten Inhalte auszuwählen, wodurch generische Inhalte ohne Mehrwert benachteiligt werden.
Inhalte mit hoher inhaltlicher Überschneidung zu bestehenden Rankings, insbesondere generische Ratgebertexte.
Durch Analyse der Top-Ergebnisse und Bewertung der inhaltlichen Überschneidung. Tools wie SISTRIX helfen bei der Identifikation von Content-Lücken.
Eine konkrete Nutzung ist nicht öffentlich bestätigt. Die Logik des Verfahrens passt jedoch zu den Anforderungen moderner KI-Suchsysteme. Es ist also sinnvoll, Web-Inhalte unter dem Aspekt des Informationsgewinns zu betrachten.
Backlinks bleiben ein Signal für Autorität, ersetzen aber nicht den notwendigen Informationsgewinn.
Der Fokus sollte auf eigenständigen Perspektiven, neue Daten und spezifischen Anwendungsfällen liegen.
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten