
Ein neuer Vorschlag sorgt für Diskussionen: Mit llms.txt könnten Website-Betreiber erstmals gezielt steuern, welche Inhalte von KI-Systemen wie ChatGPT oder Gemini verarbeitet werden sollen. Was die Datei kann, wo Chancen und Risiken liegen und warum sich ein Test nur für wenige lohnt.
Die Datei llms.txt ist ein Vorschlag für einen neuen Standard zur Interaktion zwischen Websites und KI-Systemen. Sie richtet sich speziell an sogenannte Large Language Models (LLMs), also große Sprachmodelle wie ChatGPT, Claude oder Gemini, die Inhalte aus öffentlich zugänglichen Webquellen analysieren und verarbeiten.
Technisch gesehen handelt es sich um eine einfache Textdatei im Markdown-Format, die im Root-Verzeichnis einer Website abgelegt wird. Ihr Ziel ist es, KI-Bots gezielt auf bestimmte Inhalte hinzuweisen, ähnlich wie eine Sitemap dies für klassische Suchmaschinen tut. Sie soll helfen, relevante und hochwertige Inhalte schneller zu identifizieren und effizienter nutzbar zu machen.
Im Unterschied zu robots.txt, die den Zugriff regelt, und sitemap.xml, die eine vollständige Seitenstruktur aufzeigt, dient llms.txt der inhaltlichen Kuratierung. Website-Betreiber können dort genau angeben, welche Seiten für LLMs besonders relevant sind, etwa Leitfäden, FAQs oder thematisch zentrale Ratgeberartikel.
Sichtbarkeit in Chatbots: Wo llms.txt an Grenzen stößt
Die Idee hinter der llms.txt ist nachvollziehbar. Website-Betreiber sollen gezielt steuern können, welche Inhalte von Sprachmodellen wie ChatGPT oder Gemini verarbeitet werden. In der Praxis bleibt die Wirkung bislang allerdings gering. Aktuell nutzen die großen Anbieter die Datei nicht aktiv. Wer verstehen will, wo eine Marke tatsächlich in Chatbot Antworten auftaucht, braucht verlässliche Daten statt nur technischer Hinweise.
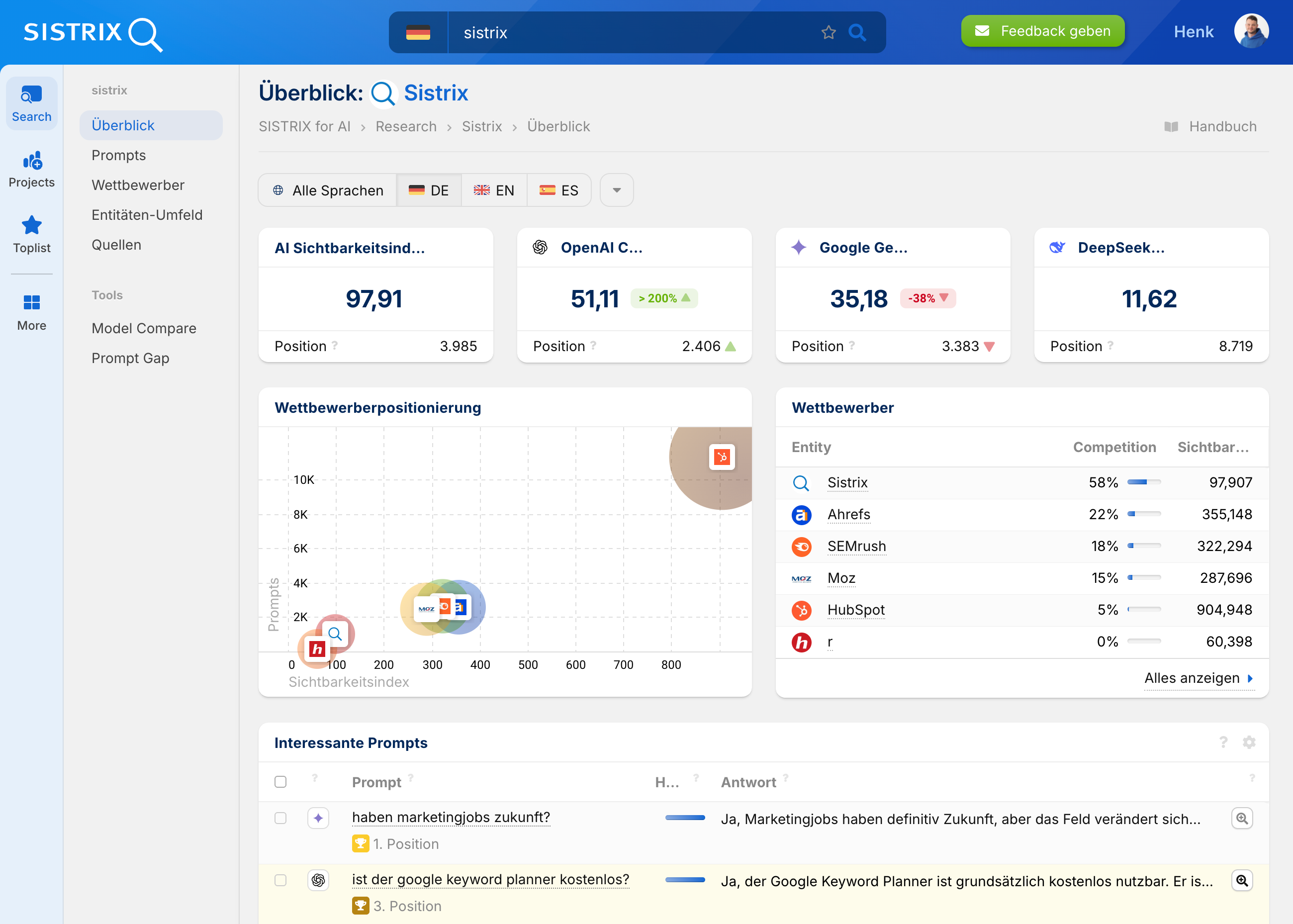
Genau hier setzt die neue SISTRIX Beta zur Chatbot Analyse an. Auf Basis von zehn Millionen sorgfältig ausgewählter Prompts analysieren wir, bei welchen Fragen Domains genannt werden, wie oft Marken erscheinen und welche Inhalte von den Modellen tatsächlich verarbeitet werden. So lässt sich erstmals systematisch nachvollziehen, wie sichtbar eine Marke in KI Systemen wirklich ist.
Die Analyse ist derzeit als Beta verfügbar und wird laufend erweitert. Wer frühzeitig Einblicke gewinnen möchte, kann sich jetzt einen 14-tägigen Testaccount erstellen und direkt loslegen.
Wer steckt hinter llms.txt?
Der Vorschlag zu llms.txt stammt von Jeremy Howard, Mitgründer des KI-Forschungslabors Fast.ai und des KI-Unternehmens Answer.ai. Die erste Veröffentlichung datiert auf den 3. September 2024. Auf Answer.ai und GitHub stellte Howard die Datei als mögliche Lösung vor, um LLMs gezielter mit qualitativ hochwertigen Webinhalten zu versorgen.
Die Struktur orientiert sich am Markdown-Format: klare Überschriften, ein beschreibender Abschnitt und eine Liste von URLs, die von den LLMs bevorzugt verarbeitet werden sollen. Die Idee ist, damit ein transparentes und einfach pflegbares Inhaltsverzeichnis für KI-Bots zu schaffen.
Beispiel für eine llms.txt-Datei
# llms.txt – Version 1.0
## Beschreibung
Beispiel.de bietet praxisnahe SEO- und Content-Marketing-Ressourcen für Einsteiger und Profis.
## Reference-Content:
- https://www.beispiel.de/seo-leitfaden
- https://www.beispiel.de/whitepaper/seo-tools-2025
- https://www.beispiel.de/faq/seo-häufige-fragen
## Sitemap:
- https://www.beispiel.de/sitemap.xml
## Richtlinien:
User-agent: *
AI-Crawling: Allow
AI-Training: Allow
AI-Summarization: Allow
AI-Generation: AllowPraktische Relevanz für SEO
Das Thema llms.txt berührt direkt den Bereich der sogenannten LLMO – also der Optimierung von Inhalten für KI-gestützte Antwortsysteme. Immer mehr Nutzer erhalten Informationen nicht mehr über klassische Suchergebnisseiten, sondern über direkt generierte Antworten von Sprachmodellen zum Beispiel in den Google AI Overviews oder ChatGPT. Wer dort sichtbar sein will, muss sicherstellen, dass seine Inhalte strukturiert, zitierfähig und klar auffindbar sind.
Die Idee hinter llms.txt ist, genau dabei zu unterstützen. Statt dass ein LLM sich durch komplexe Navigation, unstrukturierte Seiten oder eingebettete Pop-ups kämpfen muss, erhält es eine präzise Liste kuratierter URLs, gewissermaßen eine „Empfehlungsliste“ vom Website-Betreiber selbst.
In der Theorie können LLMs dadurch:
- schneller auf relevante Inhalte zugreifen,
- effizienter mit limitierten Kontextfenstern umgehen,
- gezielter hochwertige Inhalte extrahieren,
- und so den Website-Betreiber in der Antwortgenerierung sichtbarer machen.
Hinzu kommt ein technischer Vorteil: Wer für LLMs separate, abgespeckte Markdown-Versionen seiner Inhalte bereitstellt, kann Serverlast reduzieren, Ladezeiten optimieren und die Kommunikation mit Bots strukturieren, eine Art API-light für Text.
Argumente für den Einsatz
Auch wenn die llms.txt derzeit noch ein experimenteller Vorschlag ist, gibt es gute Gründe, über die Implementierung nachzudenken:
- Kurze Wege zu den besten Inhalten: Durch klare Verweise auf hochwertige URLs können LLMs schneller genau die Inhalte finden, die für sie relevant sind – ohne sich durch Navigationspfade oder irrelevante Seitenelemente arbeiten zu müssen.
- Niedriger technischer Aufwand: Die Datei ist einfach zu erstellen, leicht zu pflegen und kann ohne tiefe Eingriffe in das CMS oder bestehende SEO-Strukturen eingeführt werden.
- Potenzial zur Kontrolle der KI-Darstellung: Wer nicht möchte, dass veraltete Inhalte in KI-Antworten auftauchen, kann steuern, was in der Datei referenziert wird und was nicht.
- Technische Vorteile durch abgespeckte Inhalte: Wer mit KI-Traffic zu kämpfen hat, kann .md-Dateien mit reduziertem Markup und ohne visuelle Layouts bereitstellen und in llms.txt verlinken. Das spart Bandbreite und erhöht die Verständlichkeit.
- Frühe Positionierung bei neuen Standards: Auch Robots.txt, schema.org und AMP starteten ohne breite Unterstützung und entwickelten sich später zu etablierten Standards.
Kritik und Gegenargumente
Gleichzeitig gibt es zahlreiche Stimmen, die zur Vorsicht mahnen und gute Gründe, llms.txt nicht vorschnell zu implementieren:
- Geringe Verbreitung: Bisher nutzen weniger als 0,005 % aller Websites weltweit die Datei. Von einem Standard kann also noch gar keine Rede sein.
- Fehlende Unterstützung durch große Anbieter: Google selbst hat klargestellt, dass llms.txt derzeit von keinem der großen LLM-Anbieter verwendet wird. John Mueller verglich die Datei mit dem alten Meta-Keywords-Tag, einem Element, das wegen massiven Missbrauchs durch Seitenbetreiber und SEOs vollständig ignoriert wird.
- Missbrauchsgefahr: Theoretisch könnten Website-Betreiber andere Inhalte in llms.txt verlinken als jene, die für Nutzer oder Suchmaschinen sichtbar sind, ein potenzielles Cloaking-Risiko.
- Kein belegbarer SEO-Vorteil: Aktuell gibt es keine Hinweise darauf, dass die Datei in irgendeiner Weise das Ranking oder die Sichtbarkeit verbessert. Auch LLM-gestützte Antwortsysteme nutzen sie offenbar kaum bis gar nicht.
- Wartungsaufwand ohne klaren Nutzen: Wer viele Seiten hat, muss die llms.txt regelmäßig aktualisieren. Ohne erkennbare Wirkung lohnt sich dieser Aufwand kaum.
Was sagen Google, OpenAI und andere?
Google lehnt llms.txt derzeit als nicht zielführend ab. Auch OpenAI hat sich bisher nicht offiziell dazu bekannt, obwohl in Logfiles Hinweise auf Crawling durch den OAI-SearchBot zu finden sind.
Yoast hat den Vorschlag dennoch aufgenommen und bietet in seinem weit verbreiteten SEO-Plugin eine automatische Generierung an. Einige kleinere Anbieter experimentieren ebenfalls mit dem Format, aber von einem echten Ökosystem ist man weit entfernt.
Zudem empfiehlt Google, llms.txt auf „noindex“ zu setzen, damit sie nicht in den Suchergebnissen erscheint. Das macht deutlich: Auch aus Googles Sicht ist die Datei kein Rankingfaktor, sondern eine rein technische Ergänzung mit unklarem Nutzen.
Sollte man llms.txt jetzt einsetzen?
Die Antwort hängt stark von der jeweiligen Website ab. Eine pauschale Empfehlung ist wie immer (noch) nicht möglich. Einige Szenarien:
- Für experimentierfreudige Betreiber mit technischen Ressourcen und KI-bezogenem Traffic kann ein Testlauf sinnvoll sein. Dabei sollte man klar abgrenzen, was in die Datei aufgenommen wird, und die Wirkung über Logs oder Crawling-Statistiken überwachen.
- Für klassische Unternehmenswebsites ohne LLM-Fokus oder mit starkem Fokus auf organische Sichtbarkeit über Google ergibt sich aktuell kein Nutzen. Hier sollte der Aufwand besser in bewährte Maßnahmen wie Content-Qualität, Core Web Vitals oder strukturierte Daten investiert werden.
- Für Plattformen mit großem redaktionellen Angebot kann llms.txt ein zusätzlicher Layer sein, um besonders zitierfähige Inhalte in den Fokus zu rücken – sofern diese bereits optimal strukturiert und abrufbar sind.
llms.txt ist ein technisch interessanter, aber in der Praxis bislang weitgehend irrelevanter Vorschlag. Der Ursprung aus einem KI-nahen Unternehmen zeigt, dass wie so häufig beim Thema KI auch strategische und wirtschaftliche Interessen eine große Rolle spielen. Wer sich mit dem Thema beschäftigt, sollte das im Hinterkopf behalten und die Diskussion sachlich und faktenbasiert führen.
Aktuell besteht kein akuter Handlungsbedarf. Wer möchte, kann testen. Wer abwartet, bis sich neue Standards herausbilden, macht nichts falsch und spart sich ggf. unnötige Investitionen. Wichtig ist: Strukturierte, zitierfähige Inhalte, saubere Technik und klare Navigationspfade bleiben entscheidend, egal ob für Suchmaschinen oder Sprachmodelle.
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten