
Die inverse Dokumentenhäufigkeit – IDF – zählt wie häufig ein bestimmtes Wort in einer festgelegten Sammlung aus Dokumenten vorkommt. So kann die Einzigartigkeit eines Wort innerhalb dieser Dokumentengruppe errechnet werde.
Die inverse Dokumentenhäufigkeit stammt aus den Informationswissenschaften und hilft dort zu prüfen, ob bestimmte Worte in vielen oder wenigen Dokumenten einer, vorher in ihrer Größe festgelegten, Dokumentensammlung vorkommen.
Wo kommt die inverse Dokumentenhäufigkeit her?
Das Fundament für den IDF-Wert wurde bereits 1972 von der britischen Informatikerin Karen Spärck Jones gelegt. In ihrem Artikel „A statistical interpretation of term specificity and its application in retrieval“ definiert sie als erste in ihrem Feld, wie die Besonderheit eines Terms/Keywords kalkuliert werden kann.
Die Idee hinter diese Methode ist elegant und einfach verständlich: Ein Wort aus einer Suchanfrage, das in sehr vielen Dokumenten vorkommt, ist kein geeigneter Diskriminierer und sollte daher weniger stark im Vergleich zu einem Wort gewichtet werden, das in sehr wenigen Dokumenten vorkommt.
Was bringt mir die IDF bei Auswertungen?
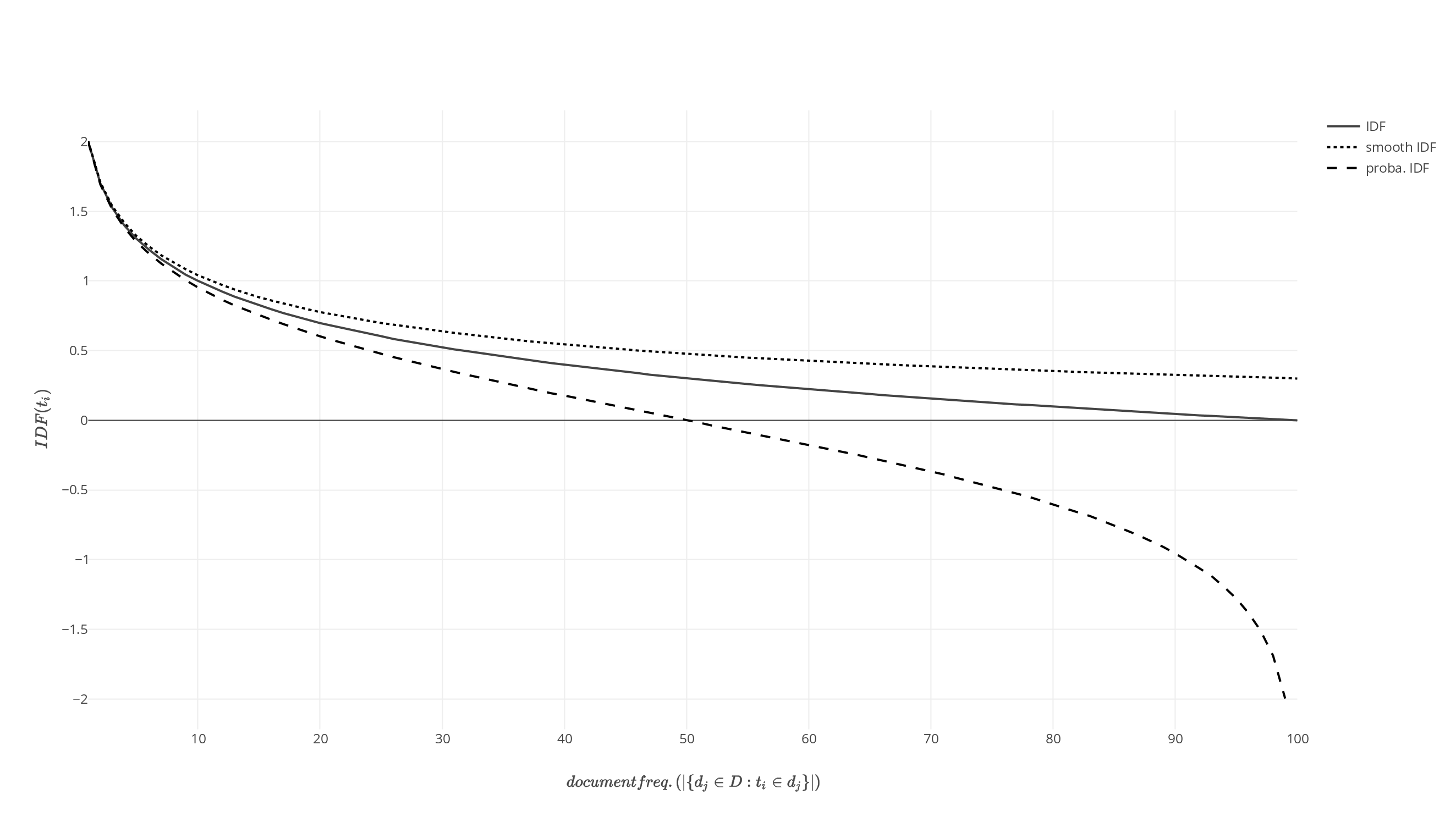
Mathematisch gesehen wird bei der Inverse Document Frequency für ein bestimmtes Wort (IDFt) die Anzahl der Dokumente der Dokumentensammlung (ND) druch die Anzahl der Dokumente derselben Sammlung geteilt, die dieses bestimmte Wort beinhalten (ƒt):
Der IDF-Wert für ein Wort wird geringer, je mehr Dokumente in der Sammlung dieses Wort beinhalten!
Damit lassen sich zB. Stoppworte sehr gut rausrechnen, da sie in einem sehr großen Teil der Dokumente vorkommen.
Beispiel 1 zur IDF
Ein Beispiel wäre eine Sammlung aus 100 Dokumenten, in denen das Wort „der“ in jedem Dokument vorkommt:
Das Wort „der“ hat in dieser Kollektion von Dokumenten keinerlei Alleinstellungsmerkmal.
Beispiel 2 zur IDF
In der gleichen Sammlung aus 100 Dokumenten kommt das Wort „es“ in 50 Dokumenten vor:
Durch den Logarithmus ist eine Vorkommnis in 50% der möglichen Fälle nicht mehr 50% der gesamt Uniqueness (was bei dem Wert 1 der Fall wäre), sondern einen Wert von 0.3.
Beispiel 3 zur IDF
Zu guter Letzt schauen nehmen wir noch an, dass das Wort „Xylophon“ im obigen Dokumenten-Korpus in genau einem Dokument vorkommt:
Die absolute Einzigartigkeit eines Wortes innerhalb einer Dokumentensammlung hat mit obiger Betrachtung maximal den Wert 2.
{kind=link}
Fazit zur inversen Dokumentenhäufigkeit
Die IDF lässt sich sehr gut als Gegenpol zu Termgewichtungen einsetzen, wenn es darum geht zu sagen: Welche Worte kommen zwar häufig ein einem einzelnen Dokument vor, sind jedoch, auf alle Dokumente die wir uns anschauen, relativ einzigartig? Oder welche Worte kommen in allen Dokumenten vor und sind damit wahrscheinlich uninteressanter?
Wobei es erst einmal egal ist, ob es sich um die reine Keyworddichte (Termfrequenz – TF) oder um einen gewichteten Wert (Within Document Frequency – WDF) handelt.
IDF als Gegenpol zur Termfrequenz und Within Document Frequency
In den beiden Gewichtungsauswertungen TF*IDF und auch WDF*IDF hat der IDF-Wert die Funktion Worte, die in allen Dokumenten vorkommen geringer zu bewerten.
Je öfter ein Wort in einem Doument vorkommt, desto höher ist der TF/WDF-Wert, je häufiger ein Wort über alle Dokumenten hinweg vorkommt, desto kleiner die IDF.
Stoppworte, die in (fast) allen Dokumenten vorkommen, verlieren somit an Wichtigkeit, egal wie häufig sie in einem einzelnen Dokument vorkommen, da der IDF-Wert bei diesen gegen 0 geht.