
Eine URL (Uniform Resource Locator) ist die eindeutige Adresse einer Ressource im Internet. Sie ermöglicht es, Webseiten, Bilder oder andere Inhalte gezielt aufzurufen. Eine gut strukturierte URL verbessert nicht nur die Nutzererfahrung, sondern spielt auch eine wichtige Rolle in der Suchmaschinenoptimierung.
- Der Aufbau und die Bestandteile einer URL
- Die Bedeutung der URL für die Suchmaschinenoptimierung
- Lesbarkeit und Nutzerfreundlichkeit
- Vermeidung von Duplicate Content
- Sonderzeichen und Schreibweise in URLs
- HTTP vs. HTTPS – Sicherheit und SEO
- URL-Weiterleitungen – richtig weiterleiten mit 301 und 302
- Wann sind Weiterleitungen nötig?
- Unterschied zwischen 301 und 302
- Best Practices für SEO-freundliche URLs
- URL Analyse mit SISTRIX
- Sprechende URLs sind sinnvoll, aber kein Rankingfaktor
- FAQ: Häufige Fragen zum Thema URL
- Wie gehe ich mit Leerzeichen in URLs um?
- Wie lang darf eine URL maximal sein?
- Sollte ich URLs nachträglich kürzen oder umbenennen?
- Sollte die URL die Kategorie beinhalten?
- Was ist besser – Unterstrich oder Bindestrich?
- Kann ich Umlaute in der URL verwenden?
- Ist die Groß- und Kleinschreibung in URLs relevant?
- Was passiert, wenn zwei URLs denselben Inhalt zeigen?
- Wie kann ich das URL-Format in WordPress anpassen?
Der Aufbau und die Bestandteile einer URL
Eine URL setzt sich meist aus mehreren Komponenten zusammen. Um den Aufbau einer URL und die jeweiligen Komponenten zu verstehen, zerlegen wir folgende Beispiel-URL in ihre Bestandteile:

- Das verwendete Protokoll – hier: HTTP (Hypertext Transfer Protocol). Andere Protokolle könnten HTTPS, FTP u.a. sein.
- Der Host oder Hostname: www.youtube.com
- Die Subdomain: www. (mittlerweile nicht mehr zwangsläufig)
- Der Domainname (Domain): youtube.com
- Die Top-Level-Domain (Endung von Webadressen): .com (abgekürzt auch TLD genannt)
- Der Pfad: /watch. Ein Pfad verweist meist auf eine Datei oder ein Ordner (Verzeichnis) auf dem Webserver (z.B. „/ordner/datei.html“)
- Parameter und Wert: v (Parameter), QhcwLyyEjOA (Parameterwert). Parameter werden durch das Zeichen „?“ innerhalb einer URL eingeleitet. Der Parametername in unserem Beispiel lautet „v“ und dessen Wert „QhcwLyyEjOA“ (Parametername und Parameterwert treten immer nach dem selben Schemata auf: Parametername=Parameterwert)
Die Bedeutung der URL für die Suchmaschinenoptimierung
Lesbarkeit und Nutzerfreundlichkeit
Klare und verständliche URLs helfen Nutzern und Suchmaschinen, den Inhalt einer Seite schnell zu erfassen. Sprechende URLs wie example.com/seo-tipps sind aussagekräftiger als kryptische Zeichenfolgen wie example.com/p=12345. Eine solche Struktur fördert das Vertrauen der Nutzer und kann die Klickrate erhöhen. Sprechende URLs lassen sich in SEO Tools wie Google Search Console, Google Analytics oder Sistrix außerdem besser analysieren und filtern.
Vermeidung von Duplicate Content
Dynamische URLs mit vielen Parametern können dazu führen, dass identische Inhalte unter verschiedenen Adressen erreichbar sind, was zu Duplicate Content führt. Dies kann das Ranking negativ beeinflussen. Die Verwendung von Canonical-Tags oder das Bereinigen der URL-Struktur hilft, dieses Problem zu vermeiden.
Sonderzeichen und Schreibweise in URLs
Bestimmte Zeichen wie Leerzeichen oder Umlaute sollten in URLs vermieden werden, da sie zu Darstellungsproblemen führen können. Stattdessen sollten Leerzeichen durch Bindestriche ersetzt und Umlaute umschrieben werden (z. B. müller.de zu mueller.de). Zudem ist es ratsam, stets Kleinbuchstaben zu verwenden und Sonderzeichen zu vermeiden.
HTTP vs. HTTPS – Sicherheit und SEO
Google bevorzugt sichere Webseiten mit HTTPS, da diese die Datenübertragung verschlüsseln und somit die Sicherheit der Nutzer erhöhen. Webseiten mit HTTPS genießen oft ein besseres Ranking und stärken das Vertrauen der Besucher.
URL-Weiterleitungen – richtig weiterleiten mit 301 und 302
Wann sind Weiterleitungen nötig?
Bei Änderungen der URL-Struktur, Umzügen von Inhalten oder Konsolidierungen sollten Weiterleitungen eingerichtet werden, um Nutzer und Suchmaschinen korrekt zu leiten.
Unterschied zwischen 301 und 302
- 301-Weiterleitung: Dauerhafte Umleitung, die Ranking-Signale überträgt.
- 302-Weiterleitung: Temporäre Umleitung, die nicht immer SEO-Vorteile bietet.
Für dauerhafte Änderungen sollte stets eine 301-Weiterleitung verwendet werden, um den Verlust von Rankings zu vermeiden.
Best Practices für SEO-freundliche URLs
- Vermeidung unnötiger Parameter: Halte die URL-Struktur sauber und vermeide überflüssige Parameter.
- Kurz und prägnant: Vermeide unnötige Wörter oder Zahlen.
- Sprechende Begriffe nutzen: Verwende klare und beschreibende Wörter.
- Kleinbuchstaben verwenden: URLs sollten konsistent in Kleinbuchstaben geschrieben sein.
- Bindestriche statt Unterstriche: Trenne Wörter mit Bindestrichen, nicht mit Unterstrichen.
URL Analyse mit SISTRIX
Die Analyse einzelner URLs ist ein wichtiger Bestandteil der Suchmaschinenoptimierung. Mit SISTRIX kannst du dir detaillierte Informationen zur Sichtbarkeit und zum Ranking einzelner Seiten deiner Website anzeigen lassen. Das hilft dabei, gezielte Optimierungen umzusetzen und die Performance einzelner Inhalte zu verbessern.
Im Bereich „URLs“ bekommst du eine Übersicht aller Seiten deiner Domain, die in den Top-10 oder Top-100 Suchergebnissen bei Google auftauchen – inklusive dem besten Keyword pro URL (also jenem, das die meisten organischen Klicks bringt). Zusätzlich siehst du, wie stark jede URL zur Gesamtsichtbarkeit deiner Domain beiträgt.
Wenn du gezielt eine bestimmte Seite analysieren möchtest, gib einfach die URL in die SISTRIX-Suche ein. Du erhältst dann unter anderem Daten zum Sichtbarkeitsindex, zu ein- und ausgehenden Links sowie zu den rankenden Keywords.
Mit praktischen Filtern – etwa nach Verzeichnistiefe, SSL oder URL-Parametern – kannst du die Analyse noch weiter verfeinern. So lassen sich technische Probleme identifizieren und die URL-Struktur optimieren.
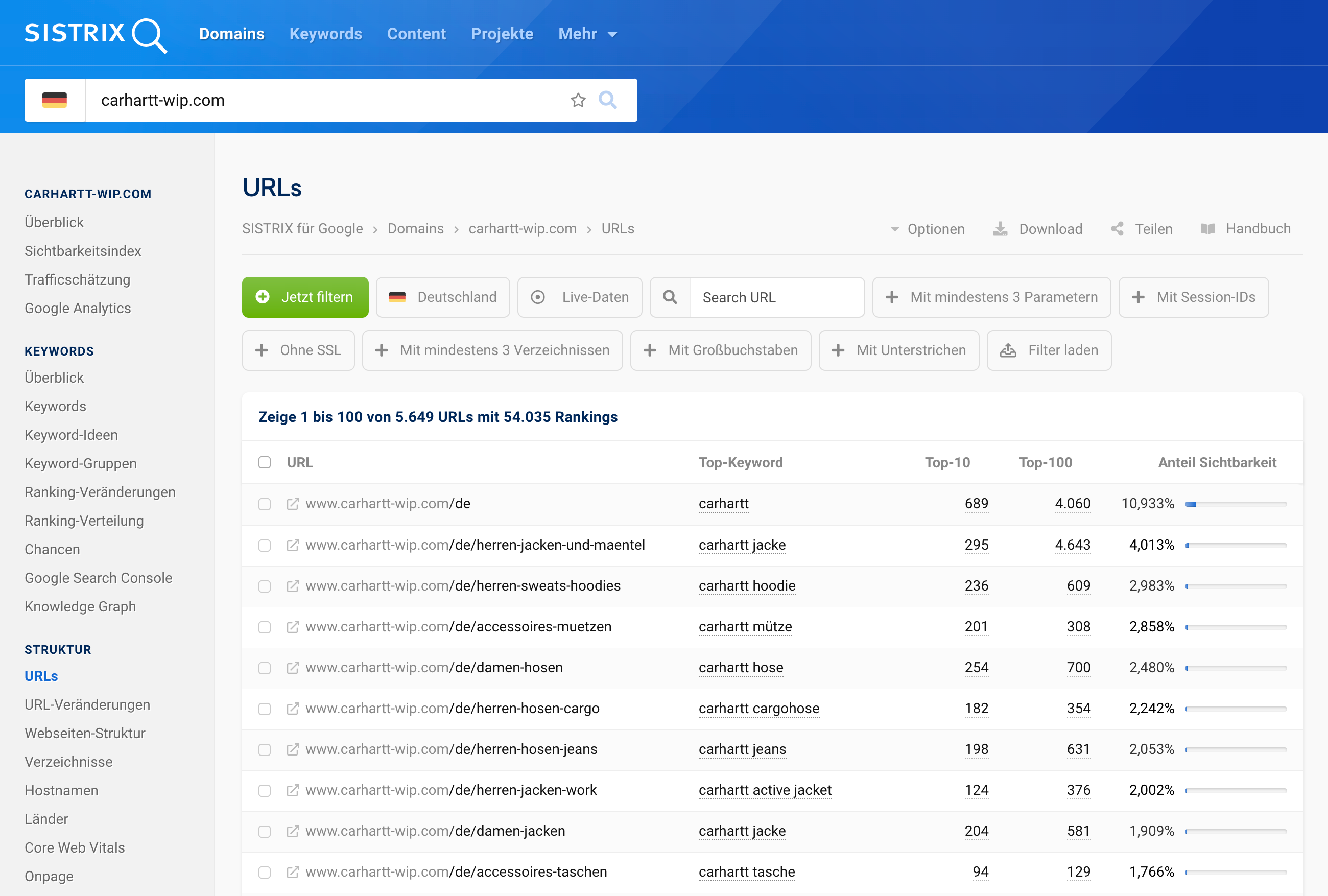
Mit SISTRIX kannst du gezielt analysieren, welche URLs deiner Website besonders erfolgreich sind – und an welchen Stellen noch Optimierungspotenzial besteht. Entdecke jetzt, wie du mit datenbasierten Insights deine Seitenstruktur verbessern und die Sichtbarkeit in der Google-Suche nachhaltig steigern kannst. Nutze die Chance und teste SISTRIX 14 Tage kostenlos, um deine wichtigsten URLs auf SEO-Potenziale zu prüfen.
Sprechende URLs sind sinnvoll, aber kein Rankingfaktor
URLs sind ein fundamentaler Bestandteil jeder Webseite, haben aber keinen unmittelbaren Einfluss auf die SEO-Performance. Sie sind in erster Linie nur eine Adresse. Diese muss eindeutig und für Suchmaschinen lesbar sein. Eine durchdachte und saubere URL-Struktur verbessert die Nutzererfahrung und hilft bei der Analyse der Daten.
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten