
Unter Duplicate Content versteht man Inhalte, die über mehrere URLs erreichbar sind und dabei entweder identisch oder sehr ähnlich sind. Dabei spielt es keine Rolle, ob sich die Duplikate auf einer einzigen Website oder über verschiedene Websites hinweg befinden. Google spricht in der Regel von „duplizierten Inhalten“, die entweder site-intern oder site-übergreifend vorkommen können.
- Warum ist Duplicate Content ein Problem für SEO?
- Duplicate Content erkennen mit einem SISTRIX-Projekt
- Wie entstehen doppelte Inhalte?
- Häufige Ursachen für Duplicate Content
- Was ist kein Duplicate Content?
- Wie geht Google mit Duplicate Content um?
- Wie kann Duplicate Content vermieden werden?
- Fazit: Duplicate Content vermeiden
Diese doppelten Inhalte stellen Google vor die Herausforderung zu entscheiden, welche URL in den Suchergebnissen angezeigt werden soll. Gleichzeitig muss bewertet werden, welche positiven Signale wie Backlinks oder Nutzerverhalten welcher URL zugeordnet werden. Das kann zu unerwünschten Schwankungen in den Rankings führen und die Sichtbarkeit einer Website insgesamt beeinträchtigen.
Typischerweise zeigt sich Duplicate Content darin, dass zwei URLs zu einem Keyword ranken, aber eher im hinteren Mittelfeld.
Warum ist Duplicate Content ein Problem für SEO?
Aus Sicht von Google und anderen Suchmaschinen bieten doppelte Inhalte keinen zusätzlichen Nutzen, sondern stellen ein Problem dar. Die Crawler möchten bevorzugt originelle, nützliche Inhalte indexieren und ausspielen. Duplicate Content erschwert diese Aufgabe, da Suchmaschinen mehr Aufwand betreiben müssen, um relevante Seiten zu identifizieren. Duplicate Content erzeugt internen Wettbewerb um Rankings, was unbedingt vermieden werden sollte.
Wird dieselbe Information unter verschiedenen URLs angeboten, kann es passieren, dass:
- die falsche URL in den Suchergebnissen landet
- die Rankingsignale sich auf mehrere Seiten verteilen
- das Crawl-Budget unnötig verbraucht wird, was die Indexierung wichtiger Seiten verzögert oder verhindert
Duplicate Content führt dabei nicht automatisch zu einer Abstrafung. Google hat mehrfach betont, dass der Algorithmus in vielen Fällen in der Lage ist, die beste Version selbst auszuwählen. Manipulativer Einsatz, etwa das massenhafte Kopieren fremder Inhalte, kann allerdings zu Rankingverlusten oder sogar zur Entfernung aus dem Index führen.
Duplicate Content erkennen mit einem SISTRIX-Projekt
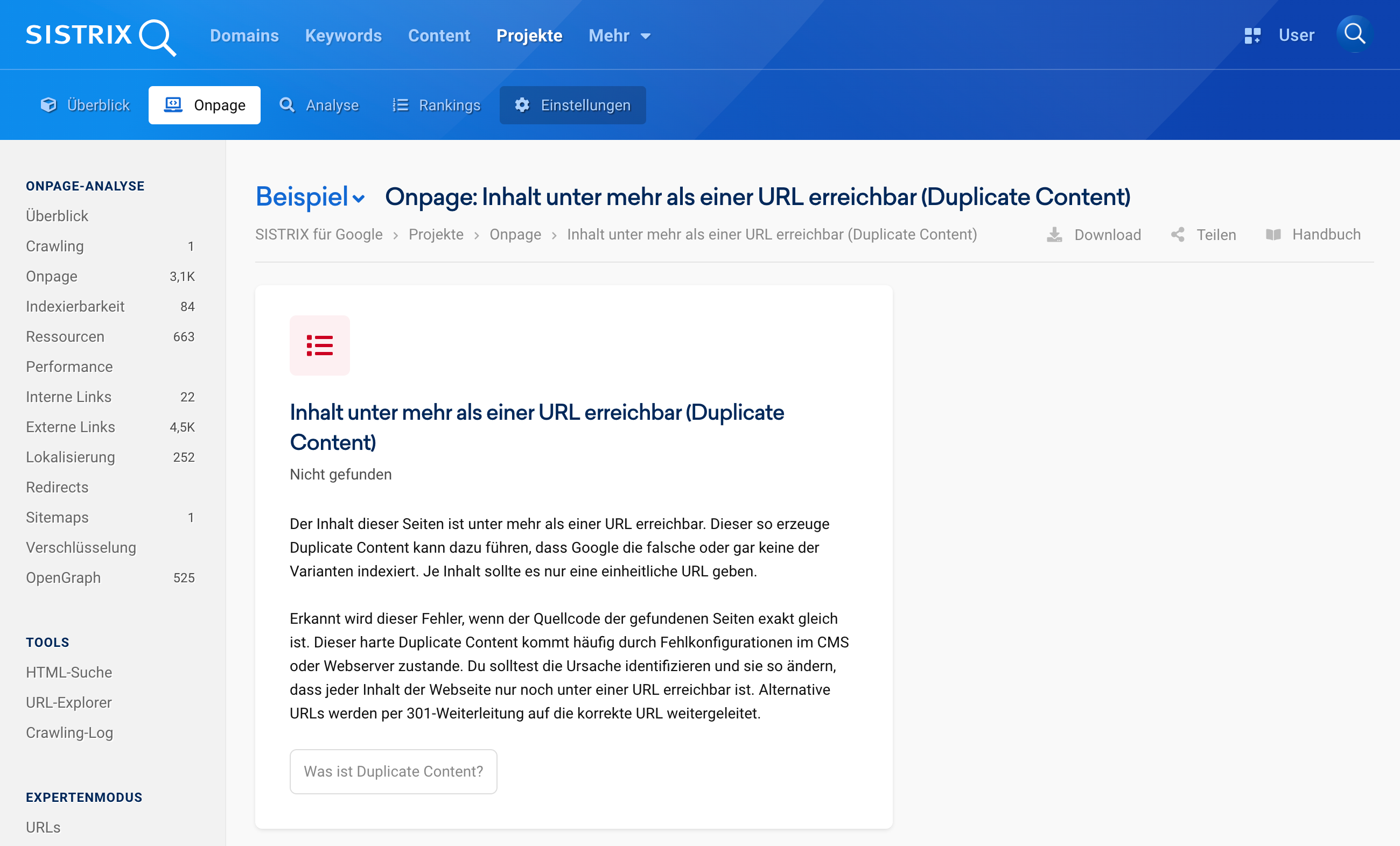
Duplicate Content gehört zu den häufigsten technischen Problemen auf Websites – und ist leider nicht immer leicht zu erkennen. Inhalte, die (fast) identisch unter mehreren URLs erreichbar sind, können die Indexierung erschweren und Rankings kosten. Besonders betroffen sind Seiten mit vielen URL-Varianten, z. B. durch Filter, Sortierungen oder Tracking-Parameter.
Ein Onpage-Projekt in SISTRIX analysiert deine Website automatisch und deckt doppelte Inhalte zuverlässig auf. Dabei werden alle betroffenen URLs übersichtlich aufgelistet – inklusive Hinweisen, warum es sich um Duplicate Content handelt und was du konkret tun kannst, um das Problem zu beheben. Zusätzlich kannst du in den Projekteinstellungen gezielt definieren, welche URL-Parameter ignoriert oder sortiert werden sollen, um unerwünschte Duplikate von vornherein zu vermeiden.
Die Ergebnisse lassen sich nach Priorität filtern, sodass du mit den wichtigsten Baustellen anfangen kannst. So wird Duplicate Content nicht nur sichtbar – sondern auch lösbar.
Während der 14-tägigen kostenlosen Testphase hast du vollen Zugriff auf alle Funktionen, inklusive der Onpage-Analyse. Du kannst direkt ein Projekt anlegen und prüfen, ob auf deiner Website doppelte Inhalte vorhanden sind.
Wie entstehen doppelte Inhalte?
Doppelte Inhalte entstehen meistens ungewollt. Gerade bei größeren Websites mit vielen Produkten, redaktionellen Inhalten oder technischen Filtermöglichkeiten ist das Risiko hoch. Typische Ursachen sind:
1. Technische Duplikate innerhalb einer Domain
Häufig kommt es vor, dass dieselbe Seite unter verschiedenen URLs erreichbar ist. Beispiele dafür sind:
- URL-Parameter (zum Beispiel ?ref=xyz)
- Sortier- und Filterfunktionen in Shops
- Session-IDs
- unterschiedliche Schreibweisen oder Pfadstrukturen (zum Beispiel /produkt und /produkt/)
2. Duplikate durch unterschiedliche Domains
Eine Website ist oft unter mehreren Adressen erreichbar, zum Beispiel mit und ohne „www“, mit verschiedenen Länderdomains oder über alternative URLs. Wenn keine Weiterleitungen eingerichtet sind, erkennt Google dies als separate Seiten mit identischem Inhalt.
3. Inhalte auf mehreren Websites
Wenn Texte auf mehreren Domains veröffentlicht oder syndiziert werden, ohne klare Kennzeichnung der Originalquelle, entsteht ebenfalls Duplicate Content. Besonders problematisch ist das, wenn alle Versionen im gleichen Sprach- und Zielmarkt (zum Beispiel google.de) indexiert werden.
Häufige Ursachen für Duplicate Content
| Ursache | Beispiel |
|---|---|
| URL-Parameter | ?ref=123, &sort=preis, ?utm_source=xyz |
| Mehrere Domains / Protokolle | http:// vs. https://, www. vs. ohne |
| Canonical fehlt oder falsch gesetzt | fehlt oder verweist auf sich selbst |
| Druck- oder Mobilversionen indexierbar | /seite/print, /m/seite ohne noindex |
| Trailing Slash uneinheitlich | /seite vs. /seite/ |
| Groß- und Kleinschreibung in URLs | /Produkt ≠ /produkt |
| Inhalte auf mehreren Domains | identische Texte auf seite.de und seite.net |
| Keine hreflang-Kennzeichnung bei Sprachversionen | example.com/de und example.de im selben Markt |
| Session-IDs oder Tracking-Parameter | ?sessionid=abc123, ?track=456 |
| Doppelte Pfade durch Kategorien oder Tags | /tag/seo, /kategorie/seo mit gleichem Inhalt |
Was ist kein Duplicate Content?
Nicht alle inhaltlichen Überschneidungen sind problematisch. Google erkennt und toleriert bestimmte Formen von Duplizierung, darunter:
Zitate: Richtig ausgezeichnete Zitate mit Quellenangabe stellen kein Problem dar
Übersetzungen: Inhalte in unterschiedlichen Sprachen gelten nicht als Duplikate, sofern sie sprachlich korrekt differenziert sind und per hreflang-Tag gekennzeichnet wurden
Paginierung: Bei sauberer technischer Umsetzung sind paginierte Seiten, zum Beispiel in Blogs oder Kategorieseiten, ebenfalls unkritisch. Google erkennt das heute ohne Probleme.
Wichtig ist immer, dass Google erkennen kann, ob es sich um originären oder kopierten Inhalt handelt und welche URL bevorzugt werden soll.
Wie geht Google mit Duplicate Content um?
Google ist heute sehr gut darin, doppelte Inhalte zu erkennen und automatisch die aus Sicht der Nutzer beste Version auszuwählen. Das kann eine Seite innerhalb einer Domain sein oder die Version auf einer anderen Domain. Dabei analysiert Google unter anderem:
- die technische Struktur der Seite
- vorhandene Canonical-Tags
- die interne Verlinkung
- externe Signale wie Backlinks
- sowie das Nutzerverhalten
In den meisten Fällen zeigt Google dann nur eine Version der Inhalte in den Suchergebnissen an. Trotzdem kann es zu unerwünschten Schwankungen kommen, wenn sich die Signale nicht eindeutig zuordnen lassen, insbesondere dann, wenn viele Versionen existieren und keine klare Präferenz kommuniziert wird.
Wie kann Duplicate Content vermieden werden?
Google empfiehlt, klare Signale zu setzen, um Duplicate Content zu vermeiden. Dazu zählen insbesondere:
Canonical-Tags
Mit dem Canonical-Tag wird im <head> einer Seite die bevorzugte URL angegeben:
<link rel=“canonical“ href=“https://www.beispiel.de/bevorzugte-seite“ />
Damit wird Google mitgeteilt, welche Version indexiert werden soll. Dies ist besonders wichtig bei Produktseiten, Filteransichten und Varianteninhalten.
301-Weiterleitungen
Alle alternativen URLs, zum Beispiel www. und non-www., http und https, sollten dauerhaft per 301 auf eine Haupt-URL weitergeleitet werden. Auch doppelte Inhalte auf mehreren Domains lassen sich so konsolidieren.
Saubere URL-Struktur und interne Verlinkung
Verlinkungen sollten immer auf die kanonische Version einer Seite zeigen. Interne Inkonsistenzen sind eine häufige Quelle für Duplicate Content.
Parameterverwaltung in der Google Search Console
Für Websites mit vielen URL-Parametern, zum Beispiel Shops mit Sortierfunktionen, empfiehlt sich die gezielte Verwaltung dieser Parameter in der Search Console. Hier kann Google mitgeteilt werden, welche Parameter die Inhalte verändern und welche nicht.
Fazit: Duplicate Content vermeiden
Duplicate Content lässt sich in den meisten Fällen durch saubere technische Umsetzung und klare Struktur vermeiden. Google ist zwar heute deutlich besser darin, mit doppelten Inhalten umzugehen. Dennoch ist es aus SEO-Sicht sinnvoll, selbst die Kontrolle zu behalten: Jede URL sollte einzigartigen Content enthalten, der nicht auf anderen URLs zu finden ist.
Wer seine Inhalte klar strukturiert, bevorzugte URLs kommuniziert und Duplikate konsequent reduziert, profitiert langfristig von stabileren Rankings, besserer Sichtbarkeit und einem effizienteren Crawl-Budget.
SISTRIX kostenlos testen
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten