
Das Crawling-Log zeigt dir in Echtzeit, wie unser Crawler deine Webseite analysiert. Du erhältst mit diesem Logfile einen genauen Einblick in das Crawling deines Onpage-Projektes.
Auf der Auswertung „Crawling-Log“ liefert dir der SISTRIX Crawler einen Einblick in das aktuell laufende Crawling deines Projektes. Ist derzeit kein Crawling aktiv, siehst du die Daten des letzten Crawls.
Die ersten vier Boxen zeigen dir die wichtigsten Informationen im Überblick. Läuft derzeit ein aktiver Crawl, werden alle Informationen auf diese Seite sekündlich aktualisiert.
- Crawler-Status: Aktueller Status des SISTRIX Crawler für dieses Projekt. Mögliche Werte sind:
- Starte: der Crawl wurde gestartet. Er wird derzeit einem freien Crawlserver zugewiesen. Das dauert in der Regel nur wenige Sekunden, kann bei besonderen Einstellungen (sehr hohe Anzahl URLs, feste IP-Adresse) allerdings auch etwas länger dauern.
- Crawling: der Crawl dieses Projektes läuft derzeit. Die Daten auf der Seite werden jetzt jede Sekunde automatisch aktualisiert.
- Analyse: der Crawl ist abgeschlossen. Jetzt werden noch einige abschließende Auswertungen und Analysen durchgeführt, so dass du die Crawling-Daten im Projekt nutzen kannst.
- Abgeschlossen: derzeit läuft kein Crawl für dieses Projekt. Du kannst jederzeit einen Crawl über den grünen Button „Crawling starten“ initiieren.
- Laufzeit: Vollständige Laufzeit des derzeitigen Crawls vom Start bis zum Ende der Analyse.
- Gecrawlte URLs: Anzahl der gecrawlten URLs. Es werden alle vom Crawler erfassten URLs gezählt, also sowohl HTML-Seiten als auch Weiterleitungen, Ressourcen und externe Verweise.
- URL-Limit: Maximale Anzahl der URLs, die in diesem Projekt erfasst werden. Stößt der SISTRIX Crawler an dieses Limit, beendet er den Crawl und wertet die erfassten Daten aus. Du kannst das URL-Limit in den Projekt-Einstellungen erhöhen.
Du kanst den Crawl jederzeit im Bereich „Onpage > Überblick“ deaktivieren.
Crawling-Statistiken
In dieser Tabelle erfährst du weitere Informationen zum Umfang des aktuell laufenden Crawls. Die Zeilen im Detail:
- Gecrawlte URLs (korrektes HTML): Anzahl der HTML-Seiten, die der Crawler gefunden hat und die einen Statuscode 200 ausgeliefert haben.
- Gecrawlte URLs (Alle): Gesamtzahl aller vom Crawler erfassten URLs in diesem Projekt. Hier werden alle HTTP-Requests gezählt. Diese Zahl ergibt sich aus der Summe der drei folgenden Werte.
- Gecrawlte URLs (HTML): Anzahl der HTML-Seiten in deinem Projekt, die der Crawler gefunden hat. Gezählt wird die Zahl der HTML-Dokumente, die innerhalb deines Projekt-Umfangs liegen und den korrekten HTML-Dateityp haben.
- Gecrawlte URLs (Ressourcen): Anzahl der Ressourcen, die gecrawlt wurden. Ressourcen sind sowohl Bilder aber auch CSS- und JavaScript-Dateien, die in deine HTML-Seiten eingebunden sind.
- Gecrawlte URLs (Externe Links): Anzahl externer Seiten, die gecrawlt wurden. Der SISTRIX Crawler kann überprüfen, ob die auf deiner Webseite gesetzten Links weiterhin korrekt sind.
- URLs in Warteschlange: Anzahl der URLs, die der Crawler noch bearbeiten wird, die aber noch nicht gecrawlt wurden.
- Blockierte URLs: Anzahl der URLs, die vom Crawler nicht erfasst werden konnten. Das tritt auf, wenn URLs über die robots.txt gesperrt werden. Gezählt werden nur HTML-Seiten des Projektes.
- Fehlgeschlagene URLs: Anzahl der URLs, die einen 400er oder 500er-Statuscode zurück geben. Gezählt werden nur HTML-Seiten des Projektes.
- Indexierbare URLs: Anzahl der gecrawlten URLs, die von Google indexiert werden können. Diese URLs sind also weder in der robots.txt gesperrt noch verhindern Anweisungen auf der Seite selber eine Indexierung.
- Datenvolumen: Bei diesem Crawl übertragenes Datenvolumen.
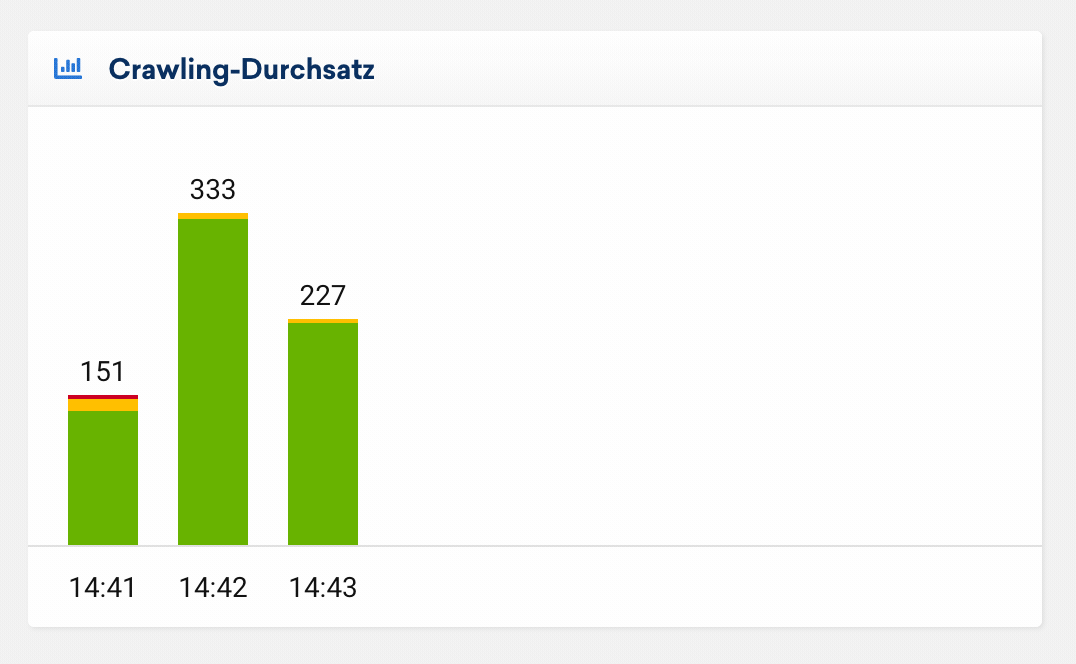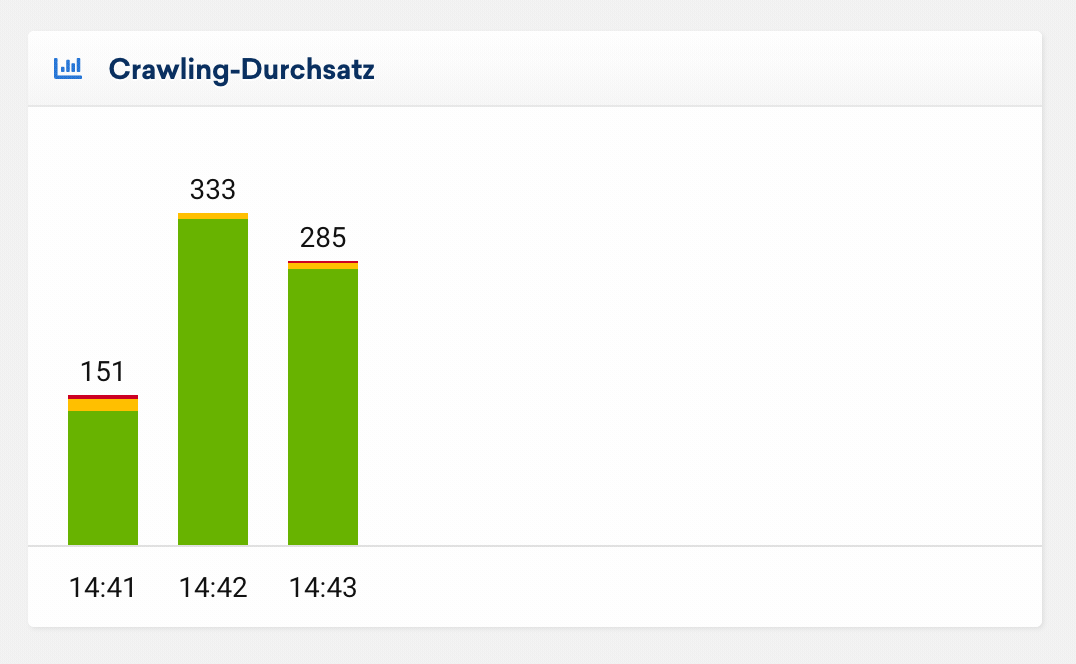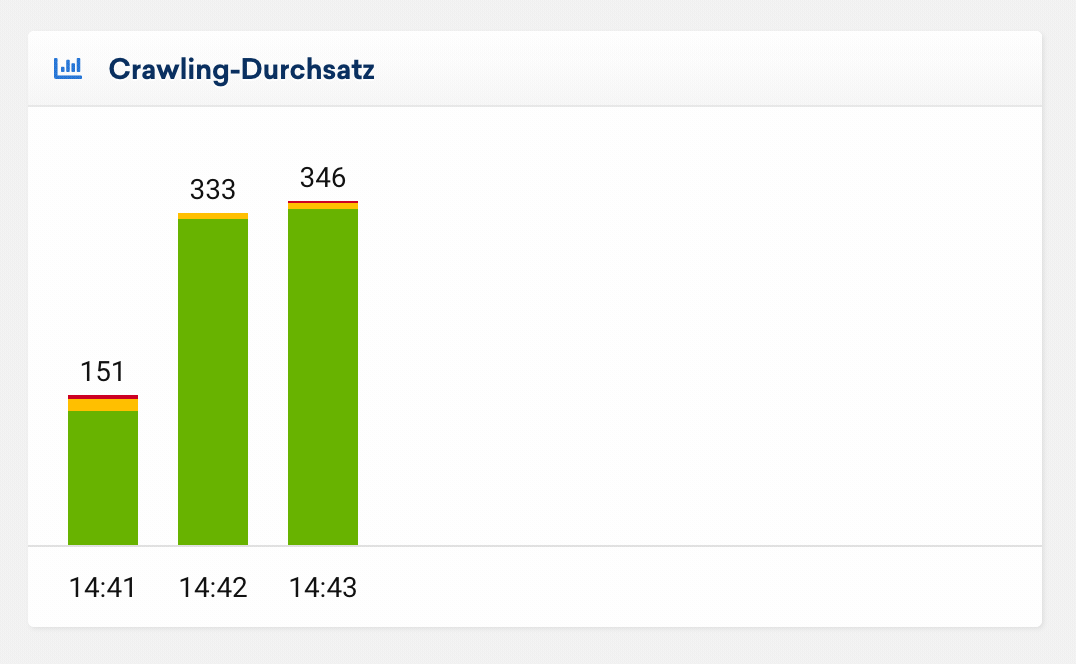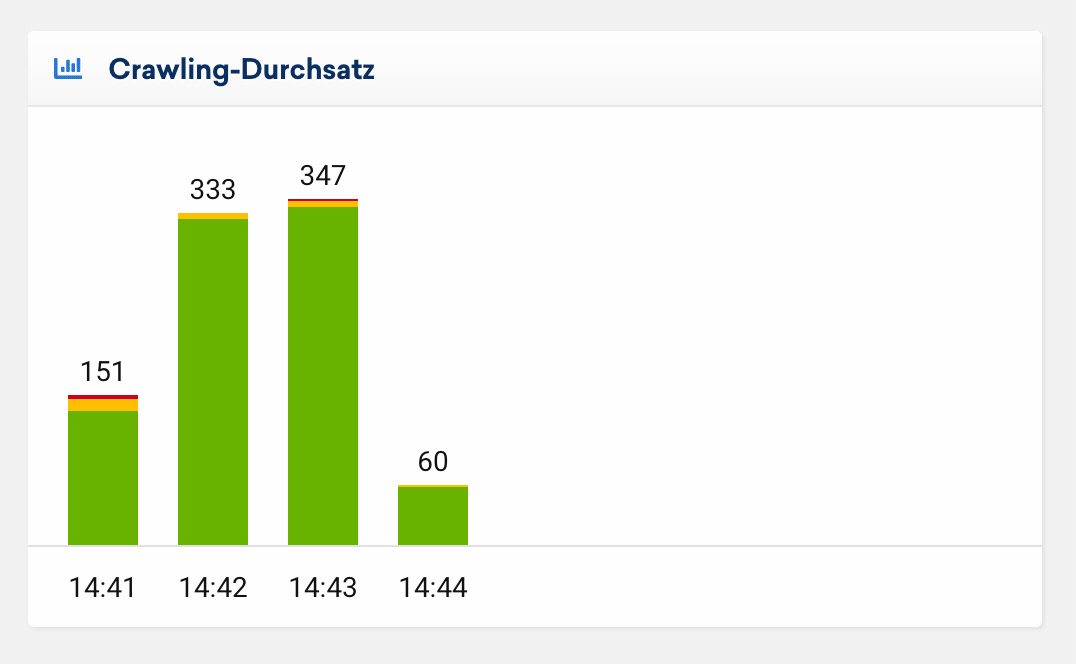
Crawling-Durchsatz
Diese Auswertung zeigt dir die Anzahl gecrawlter URLs je Minute. So lässt sich der zeitliche Verlauf deines Onpage-Crawls auf einen Blick erfassen. Seiten mit einem 200er-Statuscode werden grün dargestellt, Weiterleitungen (300er-Statuscode) in gelb und fehlerhafte Seiten (400er- und 500er-Statuscode) in rot.
Crawler Live Logfile
In dieser Tabelle siehst du die zuletzt gecrawlten URLs deines Onpage-Projektes. Neben dem Zeitpunkt des Crawlings siehst du den Statuscode der URL, die Ladezeit in Sekunden sowie die konkrete URL.
Nach Abschluss des Crawlings kannst du alle URLs in deinem Projekt durchsuchen und sortieren.