
In diesem Tutorial zeigen wir dir, wie du reguläre Ausdrücke nutzen kannst, um ihre Vorteile bei der Filterung von Tabellen in der SISTRIX Toolbox zu genießen. Dies gilt insbesondere für URLs, Snippets und Keywords.
- Was ist ein regulärer Ausdruck?
- Wie kann ich reguläre Ausdrücke zusammenbauen?
- SEO-Beispiele mit regulären Ausdrücken
- Keyword-Filter mit Regex
- Wie viele Keywords haben einen Brand-Bezug oder nicht?
- Inkorrekte schreibweisen einer Marke mit einbeziehen oder ausschließen
- Keywords einbeziehen oder ausschließen die mit bestimmten Worten startend und enden
- Keywords ein- oder ausschließen die mit bestimmten Worten beginnen
- Bestimmte Attribute auswählen oder verstecken
- Zeige nur Keywords mit bestimmten Städten an oder schließe diese aus
- Reguläre Ausdrücke logisch miteinander verknüpfen
- URLs mit regulären Ausdrücken filtern
- Bestimmte Subdomains einbeziehen oder ausschließen
- URLs die mit einem / enden oder nicht
- URLs mit Zahlen einbeziehen oder ausschließen
- Bestimmte Dateiformate in URLs einbeziehen oder ausschließen
- URLs einbeziehen oder ausschließen die auf falsche Märkte zeigen
- Zusammenfassung
Was ist ein regulärer Ausdruck?
Reguläre Ausdrücke werden genutzt um bestimmte Muster zu finden. Die Hauptnutzung findet sich in der Filterung von Elementen und das Finden von Übereinstimmungen in verschiedenen Umgebungen:
- Analytics: hier kann Regex genutzt werden um Besucher zu segmentieren.
- .htaccess: URLs können auf effiziente Weise umgeschrieben werden.
- SISTRIX: genauere Filterung der Tabellen und Reports, besonders für URLs, Snippets und Keywords.
Reguläre Ausdrücke – gerne auch mit *Regex* abgekürzt, was sich aus dem englischen regular expressions zusammensetzt – können in vielen Programiersprachen eingesetzt werden. Die Umsetzung in der Toolbox nutzt den Umfang der Perl Compatible Regular Expressions (PCRE). Das ist der Quasi-Standard zur Regex-Nutzung.
Wie kann ich reguläre Ausdrücke zusammenbauen?
Die Regulären Ausdrücke setzen sich aus verschiedenen Zeichen, Gruppen, Quantifikatoren und Klassen zusammen. Die Syntax zur Erstellung der Regex ist dabei folgendermaßen:
| Zeichen | Verhalten | Beispiel |
|---|---|---|
| ? | Sucht das vorhergegangene Zeichen 1 oder 0 Mal. | https? |
| * | Sucht das vorhergegangene Zeichen 0 Mal oder häufiger. | 30* |
| + | Sucht das vorhergegangene Zeichen 1 Mal oder häufiger. | [0-9]+ |
| | | Sucht nach dem einen Element oder dem anderen (or). | (jpg|jpeg) |
| ^ | Kennzeichnet den Anfang eines Musters. | ^https |
| $ | Kennzeichnet das Ende eines Musters. | html$ |
| · | Sucht nach einem beliebigen Zeichen (Platzhalter). | 4.. |
| \ | Stellt sicher, dass ein spezielles Zeichen nicht ausgeführt wird (Zeichen überspringen). | \/ |
| Gruppierung | Verhalten | Beispiel |
|---|---|---|
| ( ) | Fängt bestimmte Inhalte ein. | (sistrix) entspricht sistrix |
| [ ] | Fängt die Zeichen innerhalb der eckigen Klammern ein. | [0-9] entspricht irgendeiner Zahl zwischen 0 bis 9. [a-z] entspricht irgendeinem kleingeschriebenen Buchstaben zwischen a bis z. |
| { } | Zeigt an wie viele Wiederholungen es gibt oder was das Minimum oder Maximum ist. | .{1,3} entspricht irgendeinem Zeichen, welches sich 1 bis 3 Mal wiederholt. |
In diesem Tutorial werden wir keine Quantifikatoren nutzen, da diese jedoch für andere Auswertungen interessant sein können, bleiben wir euch diese natürlich nicht schuldig:
| Quantifikatoren | Verhalten |
|---|---|
| \w | Sucht nach einem Wort, einer Zahl oder einem _ -Zeichen. |
| \d | Sucht nach einer Zahl |
| \s | Sucht nach einem Leerzeichen-Zeichen. |
| \b | Entspricht dem Start oder dem Ende eines Wortes. |
| \W | Sucht nach einem Zeichen, welches kein Wort, keine Zahl und kein _-Zeichen ist |
| \D | Sucht nach einem Zeichen, dass keine Zahl ist. |
| \S | Sucht nach einem Zeichen, dass kein Leerzeichen-Zeichen ist. |
SEO-Beispiele mit regulären Ausdrücken
Alle Beispiele die wir in diesem Tutorial nutzen, lassen sich natürlich nicht nur auf Keywords oder URLs anwenden, sondern auch auf Titles, Descriptions, Linktexte etc.
Keyword-Filter mit Regex
Gib eine Domain in den Suchschlitz ein 1 und gehe dann, in der linken Navigation, auf „Keywords“ 2. Dort öffnest Du über den grünen „Jetzt filtern“ Button 3 die Filter-Auswahl.
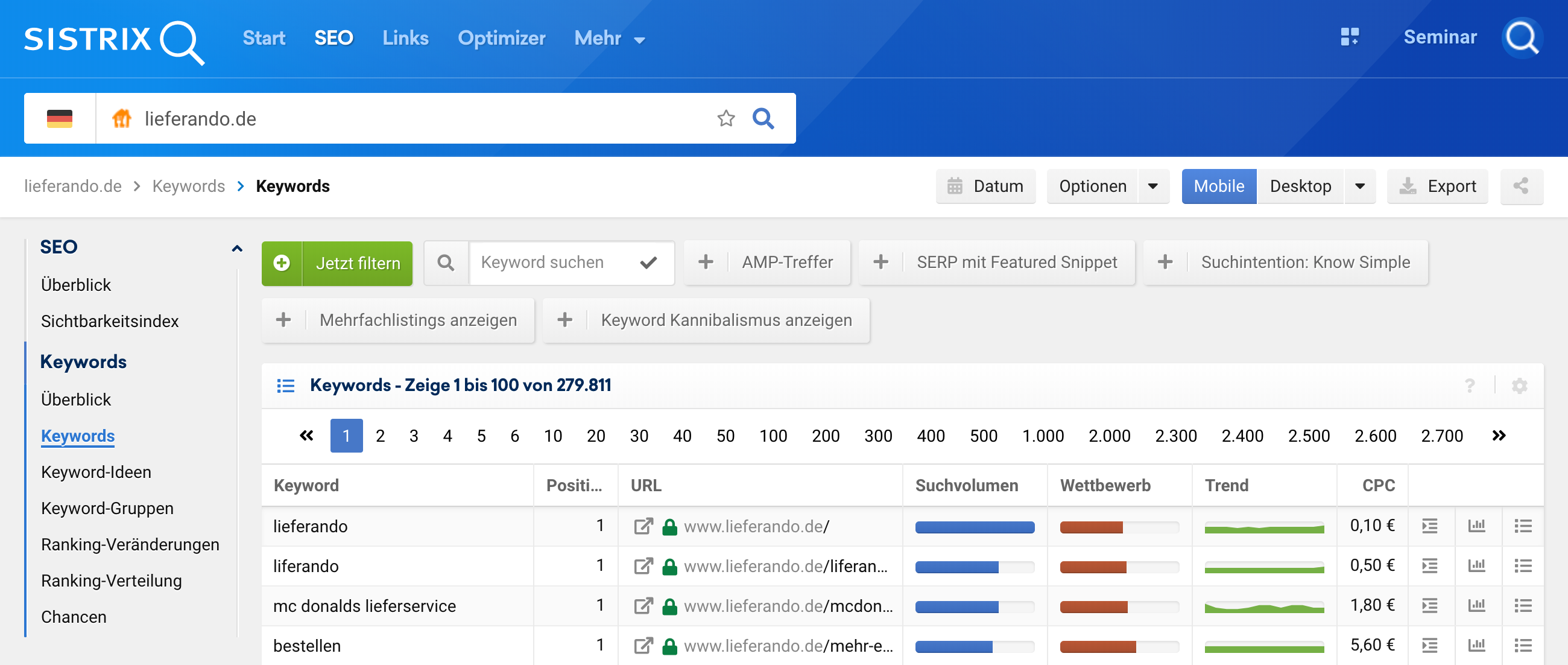
Wähle den Keyword-Filter und dort den Menüpunkt „Regulärer Ausdruck“ 4
Jetzt können wir uns verschiedene Anwendungsfälle anschauen, bei denen die Keyword-Analyse der eigenen Domain oder der Konkurrenz durch die Nutzung von Regex vereinfacht werden kann.
Wie viele Keywords haben einen Brand-Bezug oder nicht?
Stell dir vor, eine Marke hat verschiedene Schreibweisen oder verschiedene Markennamen wurden konsolidiert. Mit einem regulären Ausdruck ist es nun möglich alle Keywords, die diese Markennamen beinhalten aufzuzeigen.
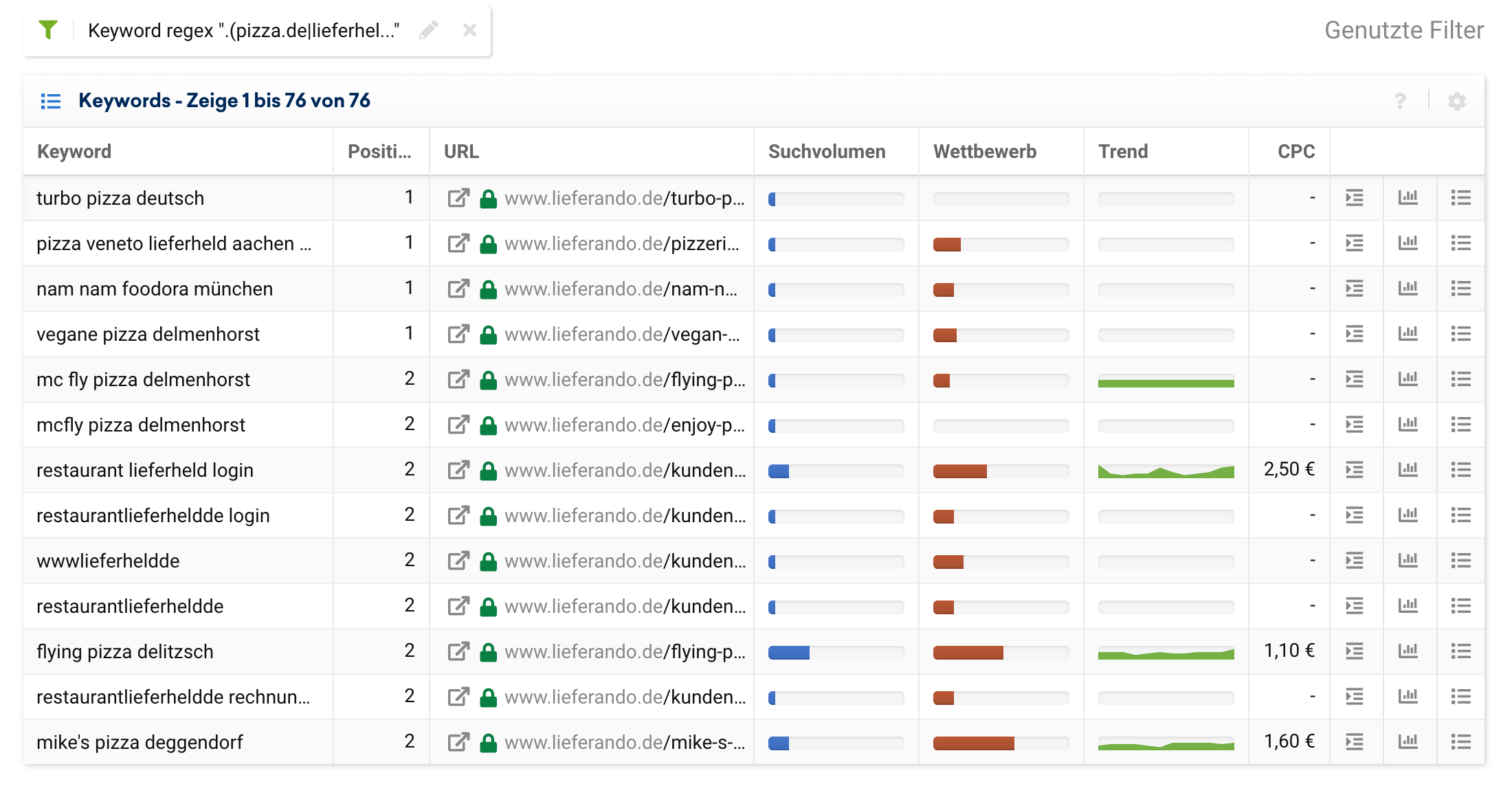
Wir nehmen in unserem Beispiel die Seiten von pizza.de, Lieferando und Foodora, welche nach ihrer Übernahme in 2019 allsamt in die Marke Lieferando konsolidiert wurden.
Wir können jetzt mit folgendem Regex alle Keywords anzeigen lassen, die eine dieser Marken enthalten:
.(pizza.de|lieferheld|foodora).Bei diesem Filter erhalten wir die folgenden Ergebnisse:
Natürlich können wir den Filter auf umdrehen, um zu sehen wie viele non-Brand Keywords die Domain von Lieferando sich erkämpft hat:
^(?!(pizza.de|lieferheld|foodora|lieferando).*$)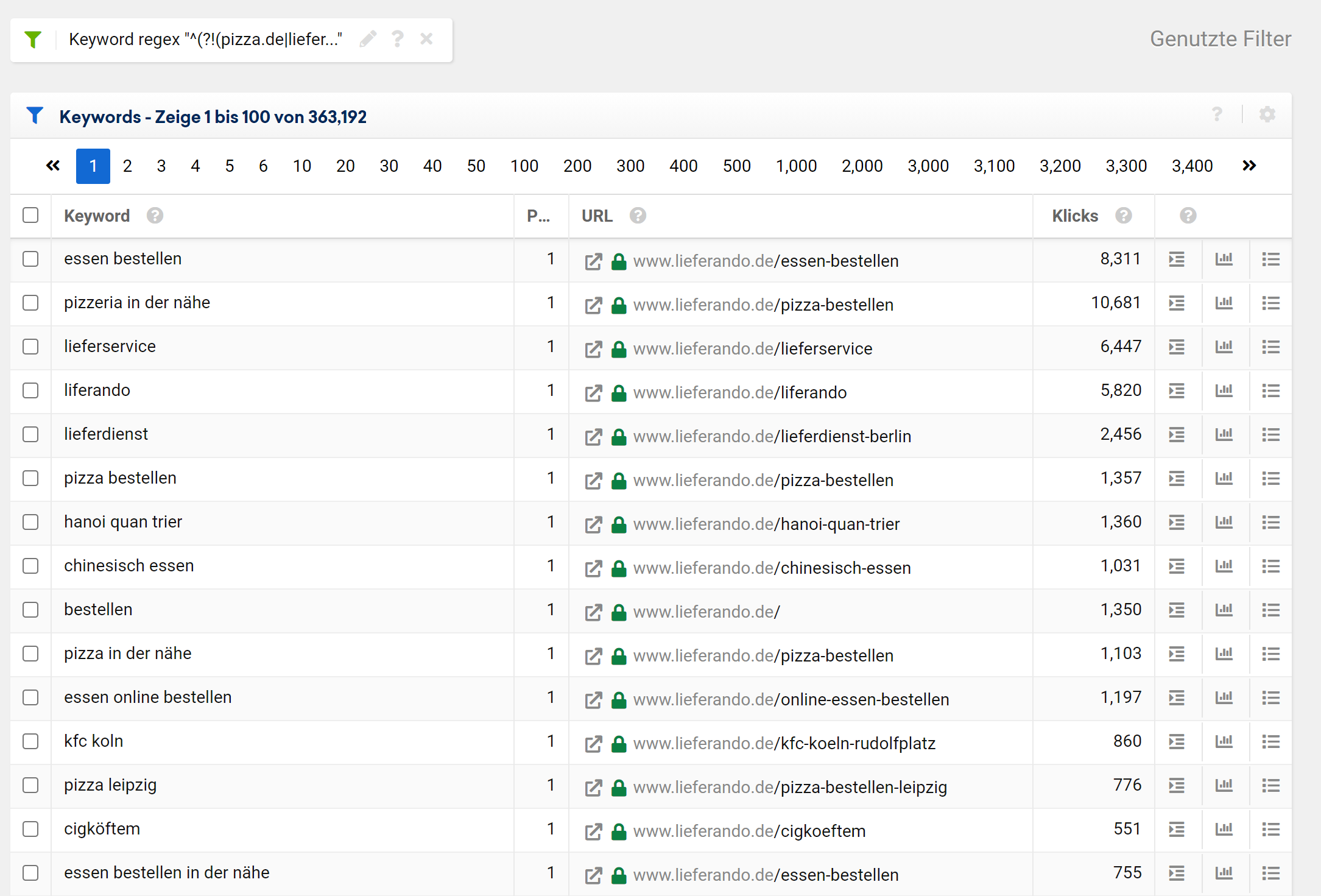
Inkorrekte schreibweisen einer Marke mit einbeziehen oder ausschließen
Es ist nicht selten der Fall, dass ein Markenname auch mit falscher Schreibweise berücksichtigt werden soll. Ein schönes Beispiel hierfür ist Ryanair.
Es gibt verschiedene Schreibweisen, die bei der Suche nach der Airline genutzt werden. Hier sind einige davon:
- ryanair
- rayaner
- ryan ir
- rayan ir
- rayana eir
- raya nair
- rayan ari
- rayar air
Insgesamt haben wir über 35 verschiedene Schreibweisen des Brandnamens gefunden. Diese können wir dank regulären Ausdrücken in einem einzigen Filter zusammenfassen:
(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?![Keyword Tabelle für die Domain ryanair.com mit einem Keyword-Filter mit dem regulären Ausdruck "(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?". Es wurden 29965 Ergebnisse gefunden.](https://www.sistrix.de/wp-content/uploads/sites/20/2019/09/ryanair-regex-1.png)
Um nur Nonbrand Keywords zu prüfen, können wir auch einen ausschließenden Filter erstellen:
^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$![Keyword Tabelle für die Domain ryanair.com mit einem Keyword-Filter mit dem regulären Ausdruck "^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$". Es wurden 101867 Ergebnisse gefunden.](https://www.sistrix.de/wp-content/uploads/sites/20/2019/09/ryanair-regex-2.png)
Wie bei allen Filtern, können weitere Keyword-Filter – wie zB. „Beinhaltet den Text“, „Beinhaltet den Text nicht“, „Beginnt mit dem Text“ – aufbauend hinzugefügt werden.
Keywords einbeziehen oder ausschließen die mit bestimmten Worten startend und enden
Wenn wir nur ein spezifisches Keyword suchen, reicht ein einfacher Filter. Möchten wir jedoch alle Keywords finden die mit „online“ starten und „kaufen“ enden, hilft uns folgender regulärer Ausdruck:
^online.*kaufen$Ein Beispiel kann ein großes Warenhaus wie otto.de sein:
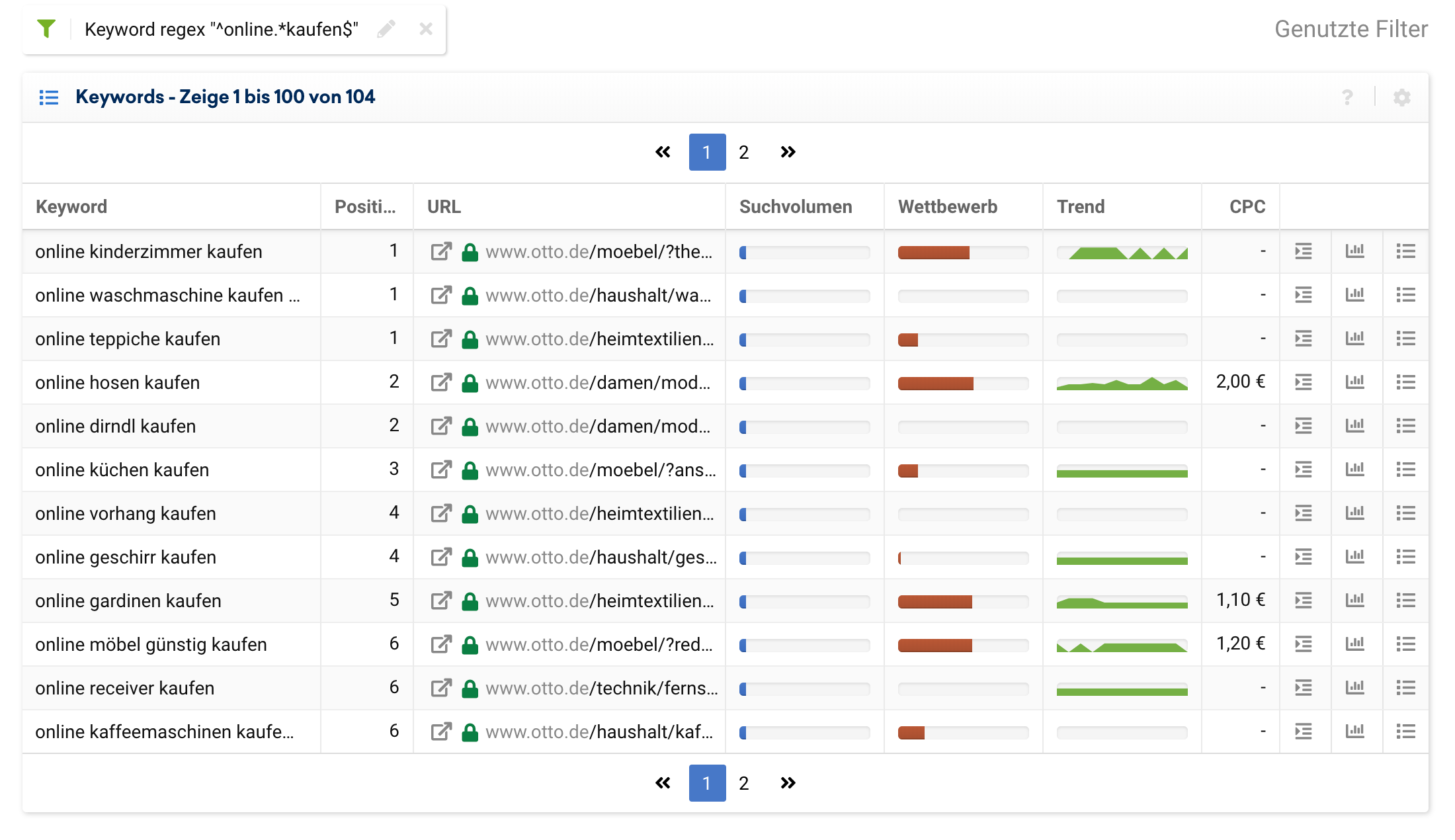
Keywords ein- oder ausschließen die mit bestimmten Worten beginnen
Besonders bei der Konkurrenzanalyse kann es spannend sein, alle Keywords für eine Liste von mehreren Herstellern zu finden.
Möchten wir zum Beispiel herausfinden welche Keywords einer Autobörse mit einer Premium-Marke starten, können wir mit folgendem regulären Ausdruck arbeiten:
^(mercedes|jaguar|bmw|audi|porsche|aston.martin).*Natürlich lässt sich der Ausdruck auch umdrehen um nur Keywords zu zeigen, die nicht mit den Marken beginnen:
^(?!(mercedes|jaguar|bmw|audi|porsche|aston.martin).*) Bestimmte Attribute auswählen oder verstecken
Nehmen wir ein Attribut, dass in vielen Projekten häufig von Interesse ist: der Preis.
Es gibt viele Suchanfragen die sich auf den Preis beziehen. Preisbezogenen Keywords können Worte wie „billig“, „Angebot“, „Outlet“, „Rabatt“, „preiswert“, „preisgünstig“ und viele weitere sein.
Wenn wir jetzt Keywords mit diesen Bestandteilen nicht in unsere Auswertung mit aufnehmen möchten, geht das folgendermaßen:
.(billig|angebot|outlet|rabatt|preiswert|preisgünstig).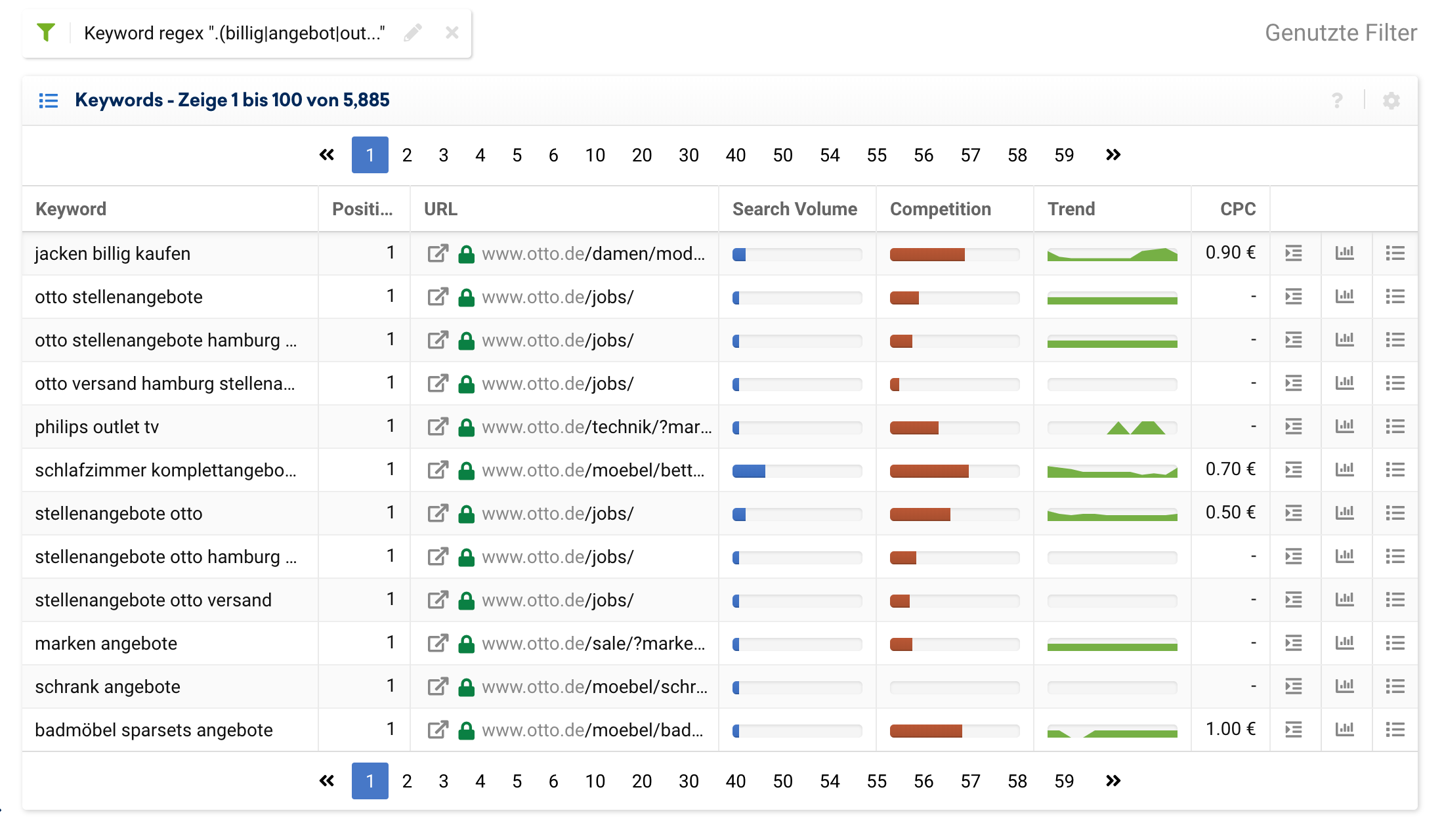
Dank der dynamischen Tabellen, lassen sich die Ergebnisse zum Beispiel auch noch nach Suchvolumen sortieren. Dazu einfach auf die Spaltenüberschrift klicken.
Neben dem Preis sind weitere, gern genutzte Attribute die der „Farbe“, „Form“, „Größe“, „Zielgruppe“ uvm.
Zeige nur Keywords mit bestimmten Städten an oder schließe diese aus
In vielen Projekten ist es wichtig, Stadtspezifische Anfragen mit auszuwerten. Mit der Hilfe von regulären Ausdrücken, können wir Keywords nach Städten, Regionen, Provinzen, Bundesländern oder Staaten filtern.
Nehmen wir für unser Beispiel nochmal Lieferando. Wenn wir wissen wollen, für wie viele Keywords Lieferando rankt, die eine der 10 größten Städte in NRW beinhalten, lässt sich das einfach mit folgendem Regex ausdrücken:
.(köln|düsseldorf|dortmund|essen|duisburg|bochum|wuppertal|bielefeld|bonn|münster).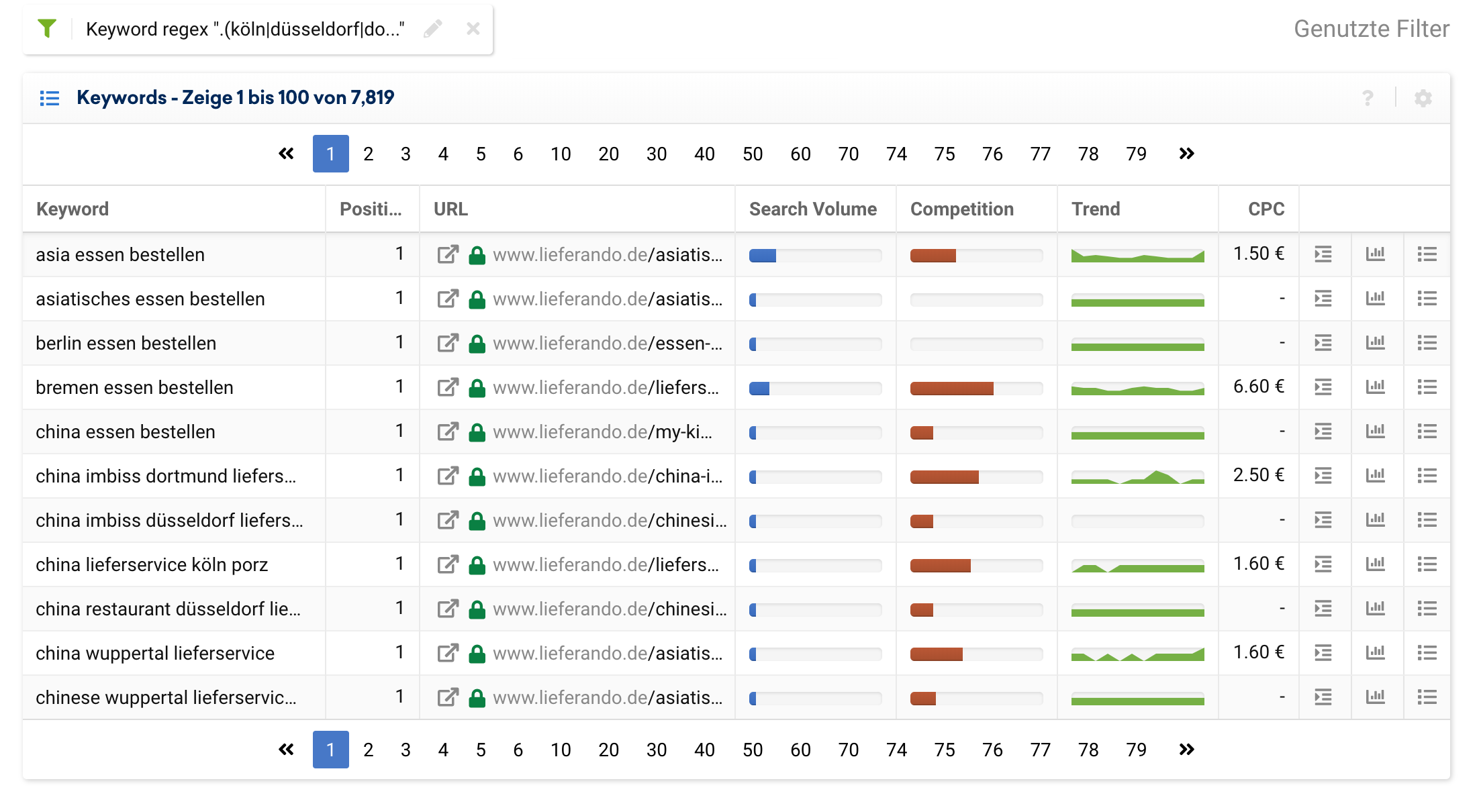
Wie bei den anderen Beispielen auch, lässt sich der Filter einfach umschreiben, um Keywords mit diesen Städten auszuschließen:
^(?!(.(köln|düsseldorf|dortmund|essen|duisburg|bochum|wuppertal|bielefeld|bonn|münster).))Reguläre Ausdrücke logisch miteinander verknüpfen
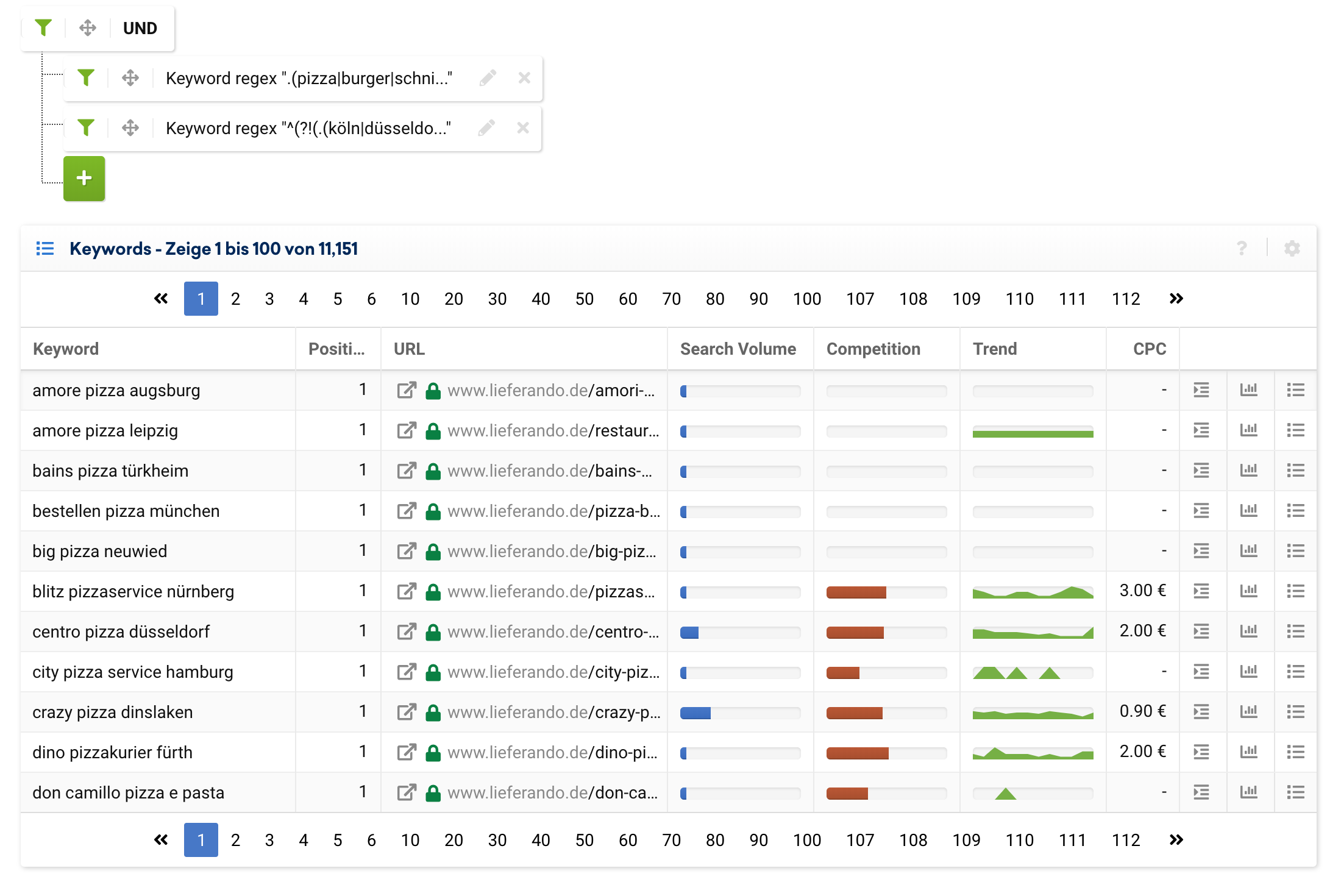
Die Filter in der Toolbox lassen sich mithilfe von „UND“ sowie „ODER“ Operatoren miteinander verknüpfen. Damit können wir noch genauere Filterkombinationen zusammenstellen.
Die Expertenfilter lassen sich über den „Optionen“-Button, oberhalb der Filter neben der Datumsauswahl, aktivieren.
Ein Beispiel hierfür wäre eine Suche nach Keywords, bei denen entweder Pizza, Burger oder Schnitzel auftaucht aber gleichzeitig nicht eine der 10 größten Städte in NRW beinhaltet sind:
URLs mit regulären Ausdrücken filtern
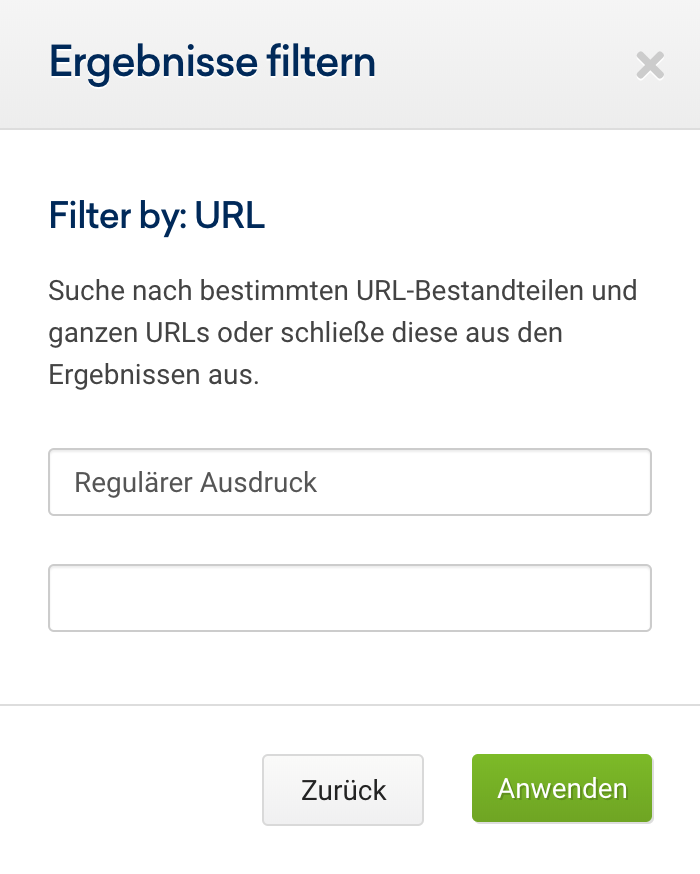
Da du jetzt gelernt hast, wie reguläre Ausdrücke zur Filterung von Keywords genutzt werden, schauen wir uns als nächstes einige Anwendungsfälle an, bei denen nach URLs gefiltert wird.
Um die URL-Spalte zu filtern, muss als Filter nur der Typ „URL“ anstelle von „Keyword“ ausgewählt werden. Auch dort findet sich die Auswahlmöglichkeit „Regulärer Ausdruck“.
Bestimmte Subdomains einbeziehen oder ausschließen
Ein praktischer Ansatz ist es, nur URLs von bestimmten Subdomains in die Auswahl mit einzubeziehen:
(www|support)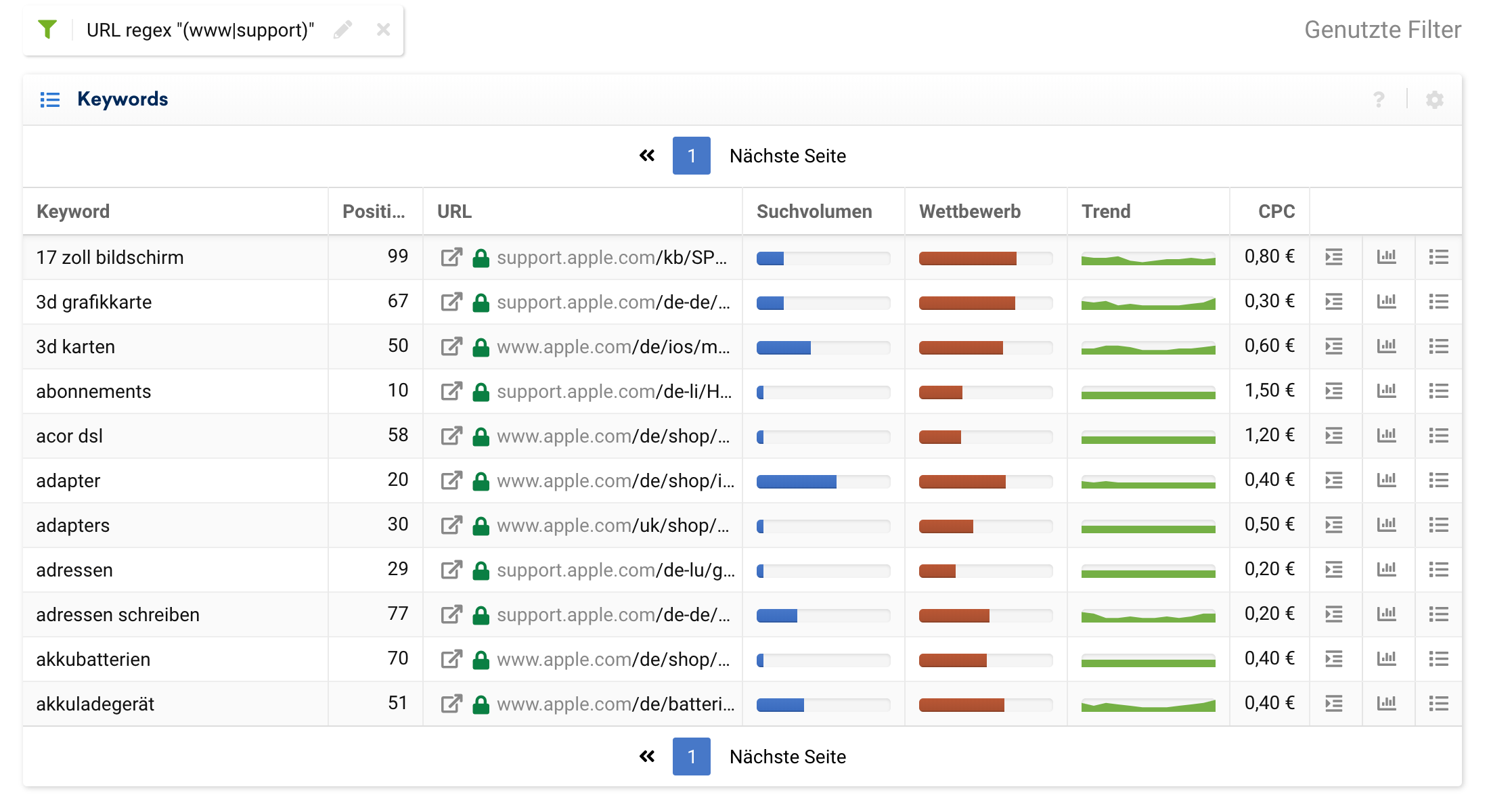
Umgekehrt können wir uns nur für transaktional interessante Subdomains interessieren. In diesem Fall können wir dann die Subdomains rausfiltern, bei denen wir wissen, dass es sich um informationelle Inhalte handelt:
^(?!.(www|support).?)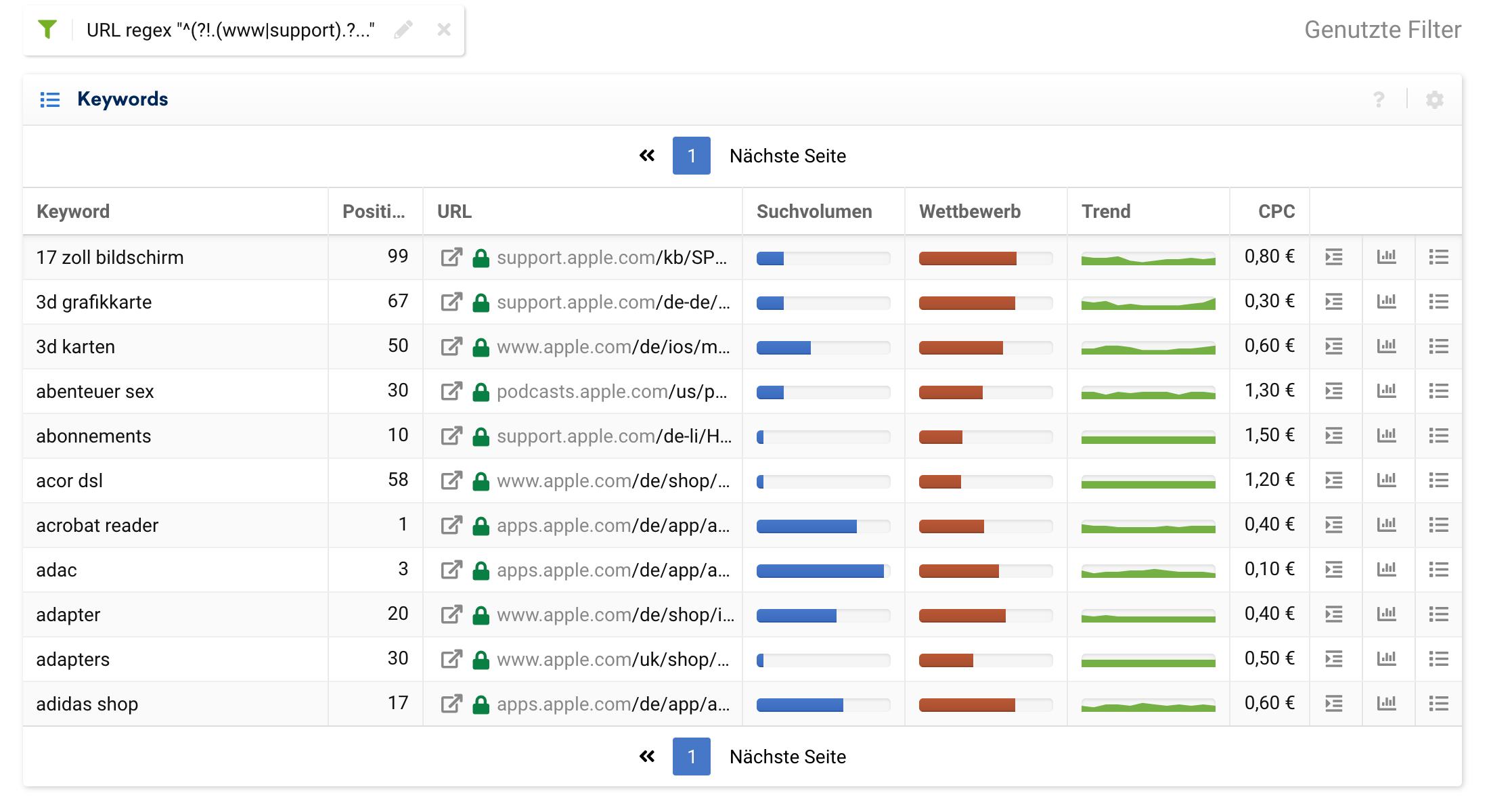
URLs die mit einem / enden oder nicht
Wir können uns nur URLs anzeigen lassen, die die Startseite einer .com-Domain ausmachen indem wir folgen Filter einstellen:
^.*.com/$Um genau diese Startseiten URLs auszuschließen reicht ein:
^(?!(.*.com/$))Für einen generelleren Filter, der alle URLs auflistet, die in einem / enden wird folgender Regex genutzt:
.*/$Schauen wir uns bei Apple an, wie viele URLs mit einem / enden und wie viele nicht? Hierzu geben wir apple.com in die Suchleiste ein 1, gehen in der linken Navigation auf URLs 2, klicken dort wieder auf „Jetzt filtern“ 3 und tragen beim URL-Filter den obigen regulären Ausdruck ein 4:
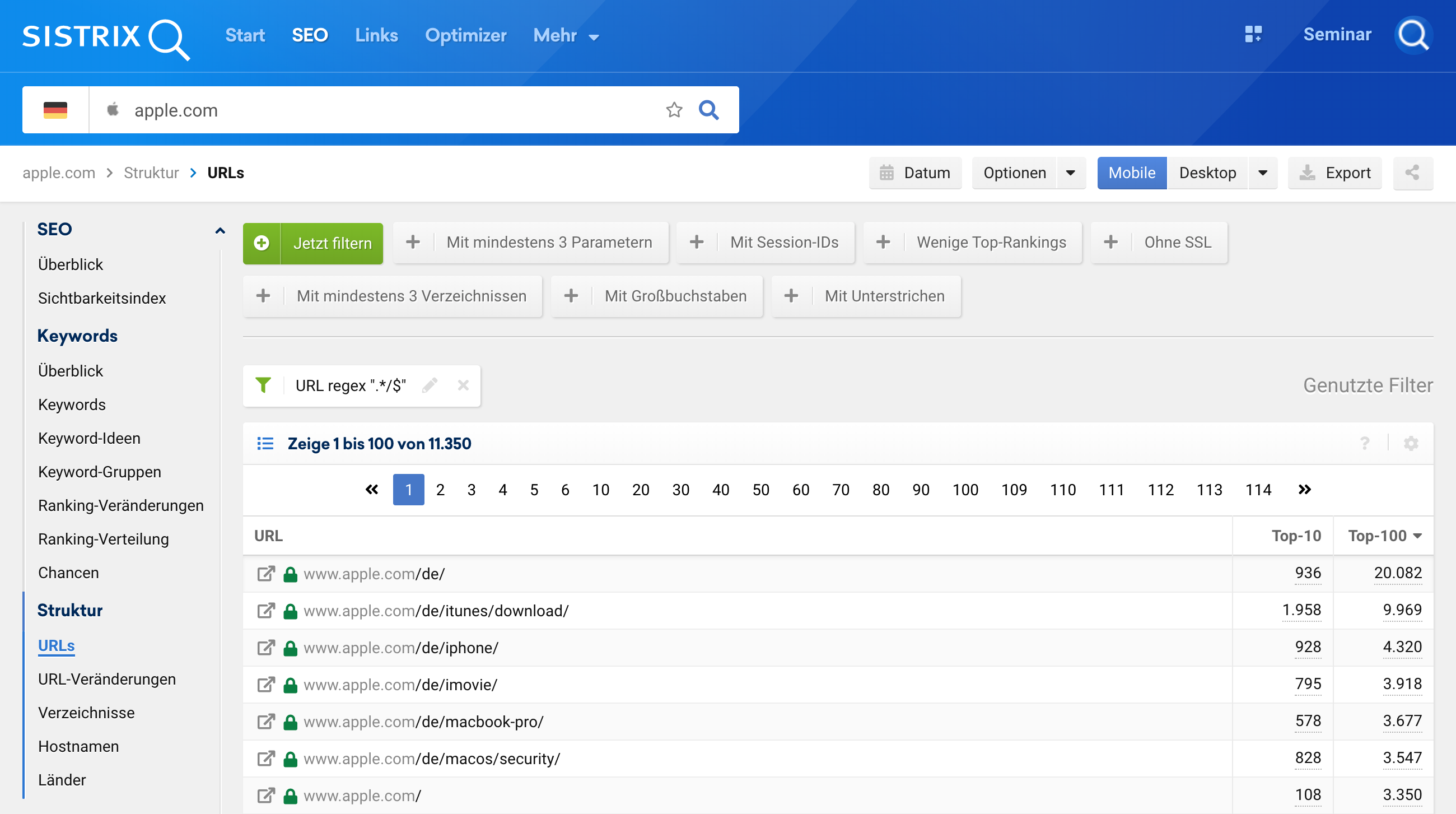
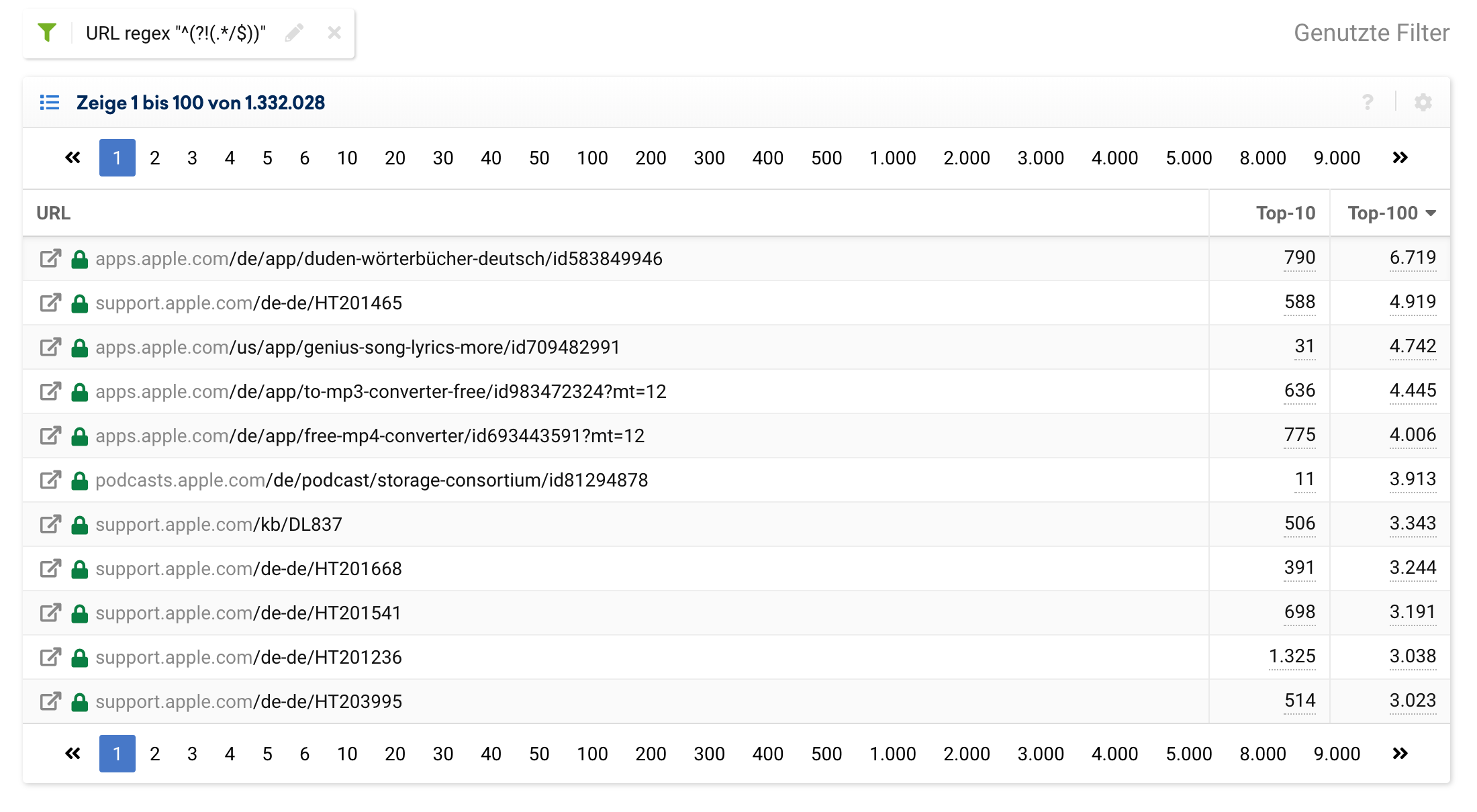
Um wiederum zu sehen, wie viele URLs apple.com besitzt, die nicht mit einem / enden, können wir den Filter anpassen:
^(?!(.*/$))
URLs mit Zahlen einbeziehen oder ausschließen
Wir können mit der Zusammenstellung der URLs arbeiten, um solche zu finden die Zahlen enthalten, oder nicht:
.-[0-9].^(?!(.-[0-9].))Wenn wir genau wissen wollen, welche URLs mit einer Zahl enden oder nicht, können wir dies auch:
.*-[0-9]+$^(?!(.*-[0-9]+$))Wenn wir wissen, dass die gewünschten URls immer mit 8 Zahlen vor einer .html Dateiendung enden, lässt sich auch dies genau abfragen und unterbinden:
.*[0-9]{8}.html$^(?!(.*[0-9]{8}.html$))Bestimmte Dateiformate in URLs einbeziehen oder ausschließen
Mit Regex lassen sich auch bestimmte Dateiformate ausfindig machen. Sei es .htm .html oder auch .pdf
Einzelne Dateiendungen lassen sich auch noch per „Text ended mit“ Filter finden, um diese als Regex darzustellen reicht ein einfaches:
.*htm.?$
.*pdf$Das Ausschließen dieser Dateiendungen funktioniert per:
^(?!(.*htm.?$).)
^(?!(.*pdf.?$).)Der Vorteil von Regex zeigt sich jedoch dann, wenn mehrere Formate gleichzeitig geprüft werden sollen. Wenn ich alle HTML-Dokumente sehen möchte geht dies über diesen Filter:
.(htm|html)$Ein weiterer Ansatzpunkt sind verschiedene Bilder, die in einem Ausdruck, mit gefiltert werden können:
.(jpg|jpeg|gif|png)$Und auch diese Formate lassen sich jeweils wieder ausschließen:
^(?!(.*(htm|html)$).)
^(?!(.*(jpg|jpeg|gif|png)$).)URLs einbeziehen oder ausschließen die auf falsche Märkte zeigen
Bei Domains die in verschiedenen Märkten unterwegs sind, ist es wichtig zu wissen, ob in einem Länderindex URLs ranken, die eigentlich zu anderen Ländern gehören. Ein Beispiel wären Englische URLs in einem Deutschen Onlineshop.
Nehmen wir an wir wollen für hm.com URLs finden, die eine bestimmte Land-Sprach Kombination in der URL hat.
Einige der Möglichkeiten sind:
Deutsch für Deutschland:
Spanisch für Spanien:
UK Englisch
US Englisch
Italienisch für Italien
uvm.
Wir können jetzt, per Regex, alle Urls rausfiltern, die nicht den Ordner /de-de/ in der URL beinhalten:
^(?!(.*[de]_[a-z].*)|(.*[a-z]_[de].*).)In unserem Fall sehen wir dann jedoch, dass bei 1 die Startseite auch auftaucht:
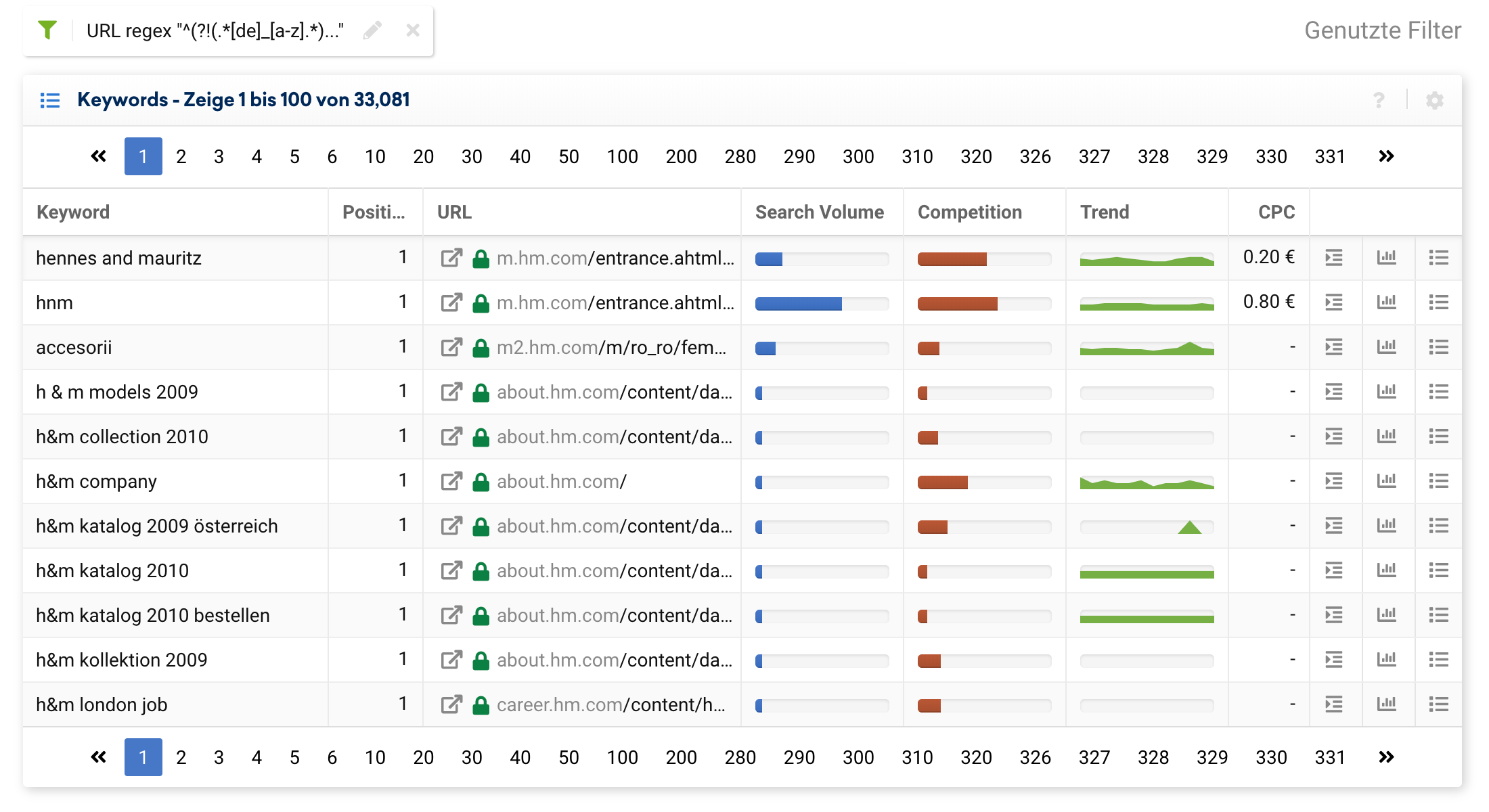
Um dies zu umgehen, können wir den Filter erweitern:
^(?!(.*.com/$)|(.*[de]_[a-z].*)|(.*[a-z]_[de].*).)![Keyword Tabelle für die Domain hm.com mit einem URL-Filter mit dem regulären Ausdruck "^(?!(.*.com/$)|(.*[de]_[a-z].*)|(.*[a-z]_[de].*).)". Es wurden 33010 Ergebnisse gefunden.](https://www.sistrix.de/wp-content/uploads/sites/20/2019/09/hm_com-regex-2.png)
Zusammenfassung
Die Parameter die du in diesem Tutorial kennengelernt hast, geben dir die Möglichkeit eigene reguläre Ausdrücke zu erstellen, die dich bei deiner täglichen SEO-Arbeit unterstützen können.
Probiere einfach verschiedene Filter mit regulären Ausdrücken aus. Wenn du prüfen möchtest, ob ein Ausdruck so funktioniert wie du dir vorstellst, kannst du https://www.regextester.com/ zur Hilfe nehmen.
Wir werden dieses Tutorial mit der Zeit um weitere hilfreiche SEO Auswertungen updaten. Einen Support für Regex können wir jedoch nicht anbieten.