
Was ist die Definition von SEO bei Google? „Indem Sie sicherstellen, dass Suchmaschinen Ihre Inhalte finden und automatisch verstehen können, verbessern Sie die Sichtbarkeit Ihrer Website für relevante Suchanfragen. Dies wird als SEO bezeichnet.“ (13.11.2018). Hier erfährst Du alle wichtigen Grundlagen der Suchmaschinenoptimierung.
- Wie funktioniert Google Suche?
- Der crawler, indexierung und SERPs Prozess vereinfacht dargestellt:
- Crawler
- Index
- Ranking-Algorithmus
- SERPs
- Die Google SERPs
- SEA (Google Ads)
- SEO
- Universal Search
- Weitere SERP-Features
- Featured Snippet
- Knowledge-Graph
- Google Shopping
- Domain, Subdomain, Host und URL
- Google-Rankingfaktoren
- Google als Quelle für erfolgreiches SEO
- Google beim Finden der Website unterstützen
- Google beim Erkennen der Website unterstützen
- Besucher beim Verwenden der Seite unterstützen
- Grundprinzipien der Qualitätsrichtlinien
- Vermeiden folgender Methoden
- Um was geht es bei den Search Quality Rating Guidelines?
- 6 gute Gründe für SEO
- Glossar
- Weiterführende Quellen
- SISTRIX für Google kostenlos ausprobieren
Wie funktioniert Google Suche?
Google ist die meistgenutzte Suchmaschine in Europa – in Deutschland liegt der Marktanteil sogar bei über neunzig Prozent. Daher hat Google die Hoheit über den Suchmarkt und bestimmt, welche SEO-Methoden erlaubt sind und welche nicht.
Wenn eine Suche bei Google durchgeführt wird, spielt Google fast in Echtzeit die Ergebnislisten aus. Aber wie sucht Google die Webseiten aus, die der Suchanfrage entsprechen? Und wie wird die Reihenfolge der Suchergebnisse festgelegt?
Der crawler, indexierung und SERPs Prozess vereinfacht dargestellt:

Crawler
Der Google-Bot crawlt (durchsucht) täglich Milliarden von Webseiten auf der Suche nach neuen und aktualisierten Inhalten & fügt diese dem Index zu.
Index
Google kann sich nun entscheiden, ob die gecrawlten Seiten im Index gespeichert werden. Dieser Index wird bei einer Suche als Grundlage für die Ergebnisse durchsucht.
Ranking-Algorithmus
Wird eine Suche gestartet, wird anhand des Ranking-Algorithmus eine passende Antwort gesucht.
SERPs
Anhand von 200 Signalen überprüft Google den Index, auf das beste Ergebnis für die gestellte Suchanfrage. Als Ergebnis werden die Suchergebnisse (SERPs) ausgespielt.
Mehr zum Thema findest Du in unserem Frag-SISTRIX Artikel „Crawling und Indexierung umfangreicher Webseiten„
Die Google SERPs
Eine typische Suchergebnisseite bei Google, oder auch auf englisch SERP (Search Engine Result Page) genannt, besteht in der Regel aus den folgenden drei Elementen:
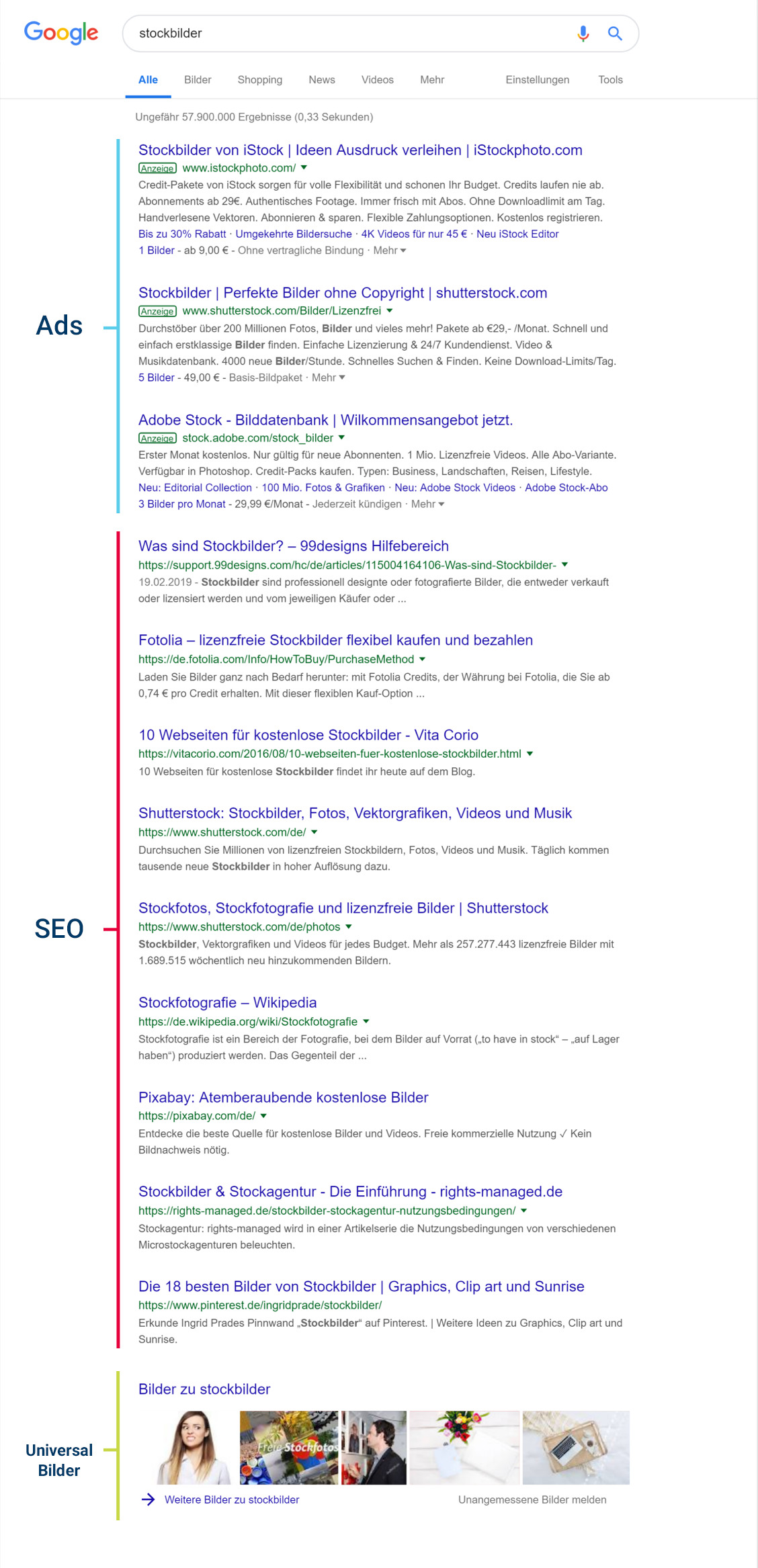
SEA (Google Ads)
Die meisten kommerziell interessanten SERPs weisen vier Google Ads oberhalb und bis zu drei Anzeigen unterhalb der organischen Suchtreffer auf. Diese bezahlten Treffer sind von Google mit „Anzeige” gekennzeichnet.
SEO
Zwischen den bezahlten Suchtreffern (Google Ads) findest Du die organischen Suchtreffer. In der Regel befinden sich auf einer Suchergebnisseite bei Google zehn dieser organischen Treffer.
Universal Search
Das dritte Element ist ein Universal-Search-Treffer. Diese Treffer stammen direkt aus einen der anderen Google-Suchen (News, Bilder, Maps, Blogs usw.) und werden von Google automatisch in die Websuche integriert.
Weitere SERP-Features
Zusätzlich zu den drei oben beschriebenen Elementen gibt es noch eine Menge zusätzlicher SERP-Treffer, die je nach Suchanfrage auftreten. Einige davon sind folgende:
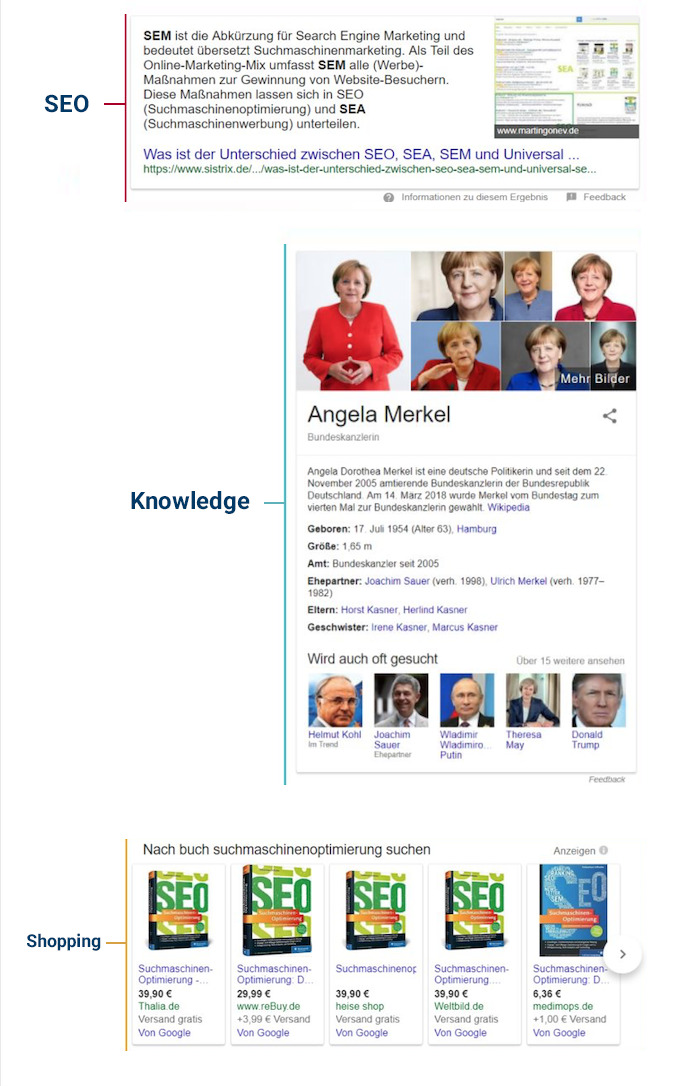
Featured Snippet
Ein Featured Snippet ist ein erweitertes SERP-Snippet. Die zusätzlichen Informationen können in Text-, Video-, Listen- oder Tabellenformat auftauchen. Das Featured Snippet befindet sich auf Position null, oberhalb der organischen Treffer.
Knowledge-Graph
Der Knowledge-Graph befindet sich immer rechts neben den Suchergebnissen und beinhaltet von Google zusammengeführte Informationen zu Orten, Menschen und Sachverhalten (auch Entitäten genannt).
Google Shopping
Eine Google-Shopping-Einblendung befindet sich i. d. R. rechts neben den Suchtreffern oder oberhalb der organischen Suchtreffer. Dabei sind die Shopping-Einblendungen meistens als Karussel oder im Kachelformat angeordnet. Hierbei handelt es sich um bezahlte Anzeigen.
Domain, Subdomain, Host und URL
Eine Internetadresse oder Webadresse besteht aus verschiedenen Komponenten.

- das verwendete Protokoll: HTTP, auch Hypertext Transfer Protocol genannt. Es empfiehlt sich die Verwendung des verschlüsselten Protokolls, HTTPS, zu verwenden.
- Der Host oder Hostname: www.youtube.com
- Die Subdomain: www. (blog. , news. , support. , …)
- Der Domainname: youtube.com
- Die Endung von Internetadressen, oder auch Top-Level-Domain (TLD) genannt: .com
- Der Pfad: /watch. Dieser verweist meist auf eine Datei oder einen Ordner auf dem Webserver
- Parameter & Wert: Parameter werden durch “?” innerhalb einer URL eingeleitet. Der Parametername lautet im obigen Beispiel “v”. Der Parameterwert folgt dahinter und lautet “QhcwLyyEjOA”. Das Schema beider Komponenten ist immer Parametername = Parameterwert.
Im allgemeinen Sprachgebrauch kommt es vor, dass, wenn von einer URL gesprochen wird, meistens ein konkreter Pfad auf ein Verzeichnis (https://www.sistrix.de/frag-sistrix/) oder aber eine Datei (file:///C:/Users/Downloads/SEO-Analysen-mit-dem-SISTRIX-Sichtbarkeitsindex.pdf) gemeint ist.
Weitere Informationen hierzu finden sich auf dem Artikel „Was ist der Unterschied zwischen einer URL, Domain, Subdomain, Hostnamen usw.?„
Google-Rankingfaktoren
Wenn es um die Google-Suche und den Algorithmus geht, gibt es einige Faktoren, welche die Zusammensetzung und Ausspielung der Suchergebnisse beeinflussen. Eine verlässliche Quelle zum Thema Google-Rankingfaktoren zu finden, ist nicht trivial – es kursieren viele falsche Informationen umher.
Daher ist es hilfreich, sich bei Google über wichtige Faktoren der Suchmaschinenoptimierung zu informieren – wir empfehlen den Google eigenen Guide Startleitfaden zur Suchmaschinenoptimierung (SEO).
- Title-Tag: Eindeutige und korrekte Seitentitel erstellen.
- Meta-Description: Meta-Tag »description« verwenden.
- Überschriften: Überschrifts-Tag verwenden, um wichtigen Text hervorzuheben.
- URL: Einfache URLs vermitteln Informationen zu Inhalten.
- Content: Inhalte der Webseite interessant und nützlich gestalten.
- Links: Links sinnvoll verwenden.
- Bilder: Bilder optimieren.
- Mobile friendly: Webseite für Mobilgeräte optimieren.
Unter anderem geht Google dort auf die oben hervorgehobenen Faktoren näher ein.
Google als Quelle für erfolgreiches SEO
Für erfolgreiches und nachhaltiges SEO sollte sich jeder, neben dem Guide Startleitfaden zur Suchmaschinenoptimierung (SEO), zunächst mit den Richtlinien für Webmaster sowie mit den Search Quality Evaluator Guidelines auseinander setzen. Hier erfährst Du nützliche Tipps von der Suchmaschine und worauf es bei der Suche ankommt.
Werfen wir an dieser Stelle einen kurzen Blick auf die Richtlinien für Webmaster. Welche Kriterien nennt Google? Hier ein kurzer Ausschnitt:
Google beim Finden der Website unterstützen
- Verlinkung aller Seiten der Website ermöglichen
- Nutze eine Sitemap-Datei
- Anzahl der Links auf einer Seite beschränken
- Nutze den HTTP-Header If-Modified-Since
- Crawling-Budget verwalten (robots.txt)
- Website bei Google einreichen
Google beim Erkennen der Website unterstützen
- hilfreiche und informative Website erstellen
- Suchintention der Zielgruppe kennen und Website darauf ausrichten
- klare Seitenhierarchie der Website anwenden
- CMS-Konformität zur Crawlbarkeit der Seiten und Links sicherstellen
- Crawlbarkeit der Assets der Website sicherstellen (darunter bspw. CSS, JavaScript-Datei
- Session IDs und URL-Parameter für Suchrobots vermeiden
- Crawlen von Werbelinks vermeiden (bspw. mit Hilfe der robots.txt-Datei oder rel=”nofollow”
Besucher beim Verwenden der Seite unterstützen
- alle Links sollten auf Live-Webseiten verweisen
- Ladezeit der Website optimieren
- Website für verschiedene Gerätetypen kompatibel gestalten
- Website für verschiedene Browser-Typen gestalten
- Barrierefreie Website gestalten
Grundprinzipien der Qualitätsrichtlinien
- Website für den Nutzer erstellen (nicht für die Suchmaschine)
- Nutzer nicht täuschen (Cloaking)
- Manipulierende Tricks für das Suchmaschinen-Ranking vermeiden
- Website einzigartig gestalten
Vermeiden folgender Methoden
- Linktauschprogramme
- Cloaking
- Brückenseiten
- Verborgene Links
- Kopierte Inhalte
- (…)
Um was geht es bei den Search Quality Rating Guidelines?
Im Kern geht es darum, auf welche Qualitätskriterien eine Website von den Google Quality Ratern manuell geprüft wird. Dadurch können SEOs, Webmaster und Marketeer mit dem 160-seitigen Dokument von Google nachvollziehen, auf was es der Suchmaschine bei qualitativ wertvollen Websites ankommt. Das vollständige PDF-Dokument findest du hier.
6 gute Gründe für SEO
- SEO ist kostenlos. Es entstehen in erster Linie keine Kosten (im Vergleich zu Google Adwords), um in den organischen Suchergebnissen von Google ausgespielt zu werden.
- SEO bringt relevanten Traffic. Interpretiert man die Suchintention seiner Nutzer richtig und stellt dazu die passende Antwort (Seite) bereit, ist SEO die qualitativ wertvollste Traffic-Quelle.
- SEO ist relevanter als SEA. 93,21% der Klicks in den Google-Suchergebnissen gehen auf organischen Ergebnisse.

- Wettbewerbsverdrängung durch SEO. Die Rankingpositionen in den SERP sind limitiert (i. d. R. 10 Treffer). Mit gutem SEO verdrängt man die Konkurrenz, gewinnt an Keyword-Rankings und generiert eine höhere Präsenz in den Ergebnislisten von Google.
- SEO stärkt das Image. Durch bessere Rankings gewinnt man an Sichtbarkeit. Dadurch wird die Brand Awareness bei der Zielgruppe in einer bestimmten Branche gesteigert.
- SEO ist messbar. Die SEO-Performance einer Website lässt sich durch die SISTRIX Toolbox genau bemessen. Unter anderem durch die Anzahl Keyword-Rankings und die Entwicklung des Sichtbarkeitsindex einer Domain.
Glossar
In der Suchmaschinenoptimierung werden viele Fachtermini benutzt. Damit Du den Durchblick behältst, findest Du hier eine Auflistung der wichtigsten Begriffe und deren Definition.
Alt-Attribut. Hierbei handelt es sich um die alternative Benennung eines Bildes – Google kann dadurch das Bild “verstehen”. In dem Bereich sollten die wichtigsten Keywords bzw. eine kurze und prägnante Beschreibung des Bildes gesetzt sein.
Ankertext. Die Benennung eines Links nennt man Ankertext oder oft auch Linktext. Praktisch gesehen handelt es sich hierbei um den sichtbaren und anklickbaren Text einer Verlinkung.
Backlinks. Bei Backlinks handelt es sich um Verweise von einer Domain auf eine andere. Nutzer können diese Links klicken um auf die verlinkte Domain zu gelangen. Backlinks sind weiterhin ein wichtiger Ranking-Faktor für Google.
Bounce-Rate. Dieser Wert, auch Absprungrate genannt, zeigt, wie oft ein Nutzer eine Webseite verlassen hat, ohne mehr als eine Unterseite besucht zu haben.
Canonical Tag. Mit dem Canonical Tag lässt sich eine Original-URL festlegen. Gibt es mehrere URLs mit gleichen Inhalten, wird Google durch das Canonical Tag die Standard-URL mitgeteilt. Dadurch werden die Kopie(n) hinsichtlich Duplicate Content ignoriert. Hinweis: es gibt nur wenige legitime Anwendungsfälle des Canonical Tags. Es dient meistens nur als “Pflaster” in solchen Fällen, bei dem das eigentliche Problem nicht gelöst werden kann.
Conversion. Ein Vorgang im Online-Marketing, bei dem eine gewünschte Aktion durchgeführt wird. Eine Conversion ist damit bspw. ein Kauf, ein Download oder das Absenden einer Anmeldung.
Duplicate Content. Werden Inhalte über mehrere URLs gefunden, dann spricht man von doppelten Inhalten. Dieser sogenannte Duplicate Content sollte unbedingt vermieden werden. Der Inhalt einer Seite darf immer nur über eine eindeutige URL erreichbar sein. Ansonsten stellt man Google vor das Problem, welche der URLs in den Rankings angezeigt werden soll und welche positiven Rankingsignale welcher URL zugeordnet werden sollen.
Crawler. Automatisierte Software, die Seiten aus dem Web crawlt bzw. abruft und indexiert.
Crawling. Der Prozess, bei dem nach neuen oder aktualisierten Webseiten gesucht wird. Google folgt Links, liest Sitemaps und nutzt viele andere Methoden, um URLs zu finden. Google crawlt das Web, sucht nach neuen Seiten und indexiert diesen dann bei Bedarf.
Featured Snippet. Bei dem auf deutsch hervorgehobenen Snippets, handelt es sich um ein Format eines Snippets (Schnipsel), welches durch eine direkte Antwort auf die Suchphrase des Nutzer erweitert wird. Das Featured Snippet besteht aus Title Tag, URL und der Antwort auf die Suchphrase und kann in Form von Text, Liste, Tabelle oder Video vorkommen.
follow-Attributwert. Mit dem follow-Tag kommuniziert man der Suchmaschine einem oder mehreren Links auf einer Seite zu folgen. Die verlinkte Seite wird somit von Google gecrawlt und der Linkgeber überträgt an den Linkempfänger Linkjuice.
Google PageRank. Hinter dem PageRank steht ein Algorithmus von Larry Page und Sergei Brin. Dieser bewertet und gewichtet die Reputation einer Seite anhand der Anzahl eingehender Links und bildete in den frühen Zeiten von Google die Grundlage des Algorithmus zur Ausspielung der Suchergebnisseiten. Der PageRank wird intern bei Google noch verwendet, ist jedoch extern nicht mehr zugänglich.
Googlebot. Der allgemeine Name des Crawlers von Google. Der Googlebot crawlt ständig das Internet.
HTTP-Statuscode. Ein HTTP-Statuscode wird von einem Server auf jede HTTP-Anfrage als Antwort geliefert. Dabei ist HTTPS das sichere Kommunikationsprotokoll zur Datenübertragung im Internet. Der Server kann nun verschiedene Antworten ausliefern, wie bspw. 200, 3xx, 4xx oder 5xx uvm.
hreflang-Attribut. Mit der hreflang-Anmerkung kann sichergestellt werden, dass Google die jeweilige geografische Ausrichtung der Website versteht und die jeweils passende Sprachversion oder regionale URL eines Inhalts dem User ausliefert.
Index. Alle Webseiten, die Google bekannt sind, werden im Index von Google gespeichert. Im Indexeintrag für jede Seite werden deren Inhalt und Speicherort (URL) beschrieben. Indexieren ist der Vorgang, bei dem Google eine Seite abruft, liest und dem Index hinzufügt: “Heute hat Google mehrere Seiten auf meiner Website indexiert.”
JavaScript. Mit JavaScript, einer Skriptsprache, lassen sich manigfaltige Gestaltungs- und Umsetzungsmöglichkeiten, wie zum Beispiel Bilderkarusselle und automatisch nachladende Seiteninhalte, in eine Webseite einbauen.
Meta Description. Im Meta-Tag „description“ sind die auf der betreffenden Seite behandelten Themen für Google und andere Suchmaschinen zusammengefasst. Der Titel einer Seite kann einige Wörter oder einen Ausdruck umfassen. Das „description“-Meta-Tag einer Seite hingegen kann ein oder zwei Sätze oder sogar einen kurzen Absatz enthalten. Die Google Search Console bietet einen praktischen Bericht zu HTML-Verbesserungen, in dem über zu kurze, zu lange oder zu oft duplizierte „description“-Meta-Tags informiert wird. Dieselben Informationen sind auch für <title>-Tags verfügbar. Wie das <title>-Tag wird auch die Meta-Description innerhalb des <head>-Elements des HTML-Dokuments platziert.
Meta-Tags. Mit Meta-Tags können Webmaster Informationen über ihre Websites für Suchmaschinen bereitstellen. Meta-Tags können verwendet werden, um die verschiedensten Clients mit Informationen zu versorgen. Jedes System verarbeitet nur die jeweils bekannten Meta-Tags und ignoriert die unbekannten Tags. Meta-Tags werden im <head>-Abschnitt des HTML-Dokuments platziert.
Mobile-Friendly. Hiermit ist die Nutzbarkeit einer Seite auf dem mobilen Endgerät gemeint. Dahinter steht die Optimierung der Webseite für Smartphones.
nofollow-Attributwert. Mit dem nofollow-Tag kommuniziert man der Suchmaschine, einem oder mehreren Links auf einer Seite nicht zu folgen. Somit wird die verlinkte Seite nicht gecrawlt. Darüber hinaus wird durch den nofollow-Attributwert auch kein PageRank auf die verlinkte Zielseite übermittelt, weshalb das nofollow-Attribut niemals für interne Links verwendet werden sollte.
noindex-Wert. Mit dem Meta-Robots-Wert “noindex” weist man eine Suchmaschine an, die entsprechende Seite nicht in den Google Index mit aufzunehmen. Das Indexieren einer Seite (URL) kann somit vom Webmaster aktiv beeinflusst werden.
Robots.txt Eine robots.txt-Datei ist eine Datei im Stammverzeichnis der Website, in der die Teile der Website angegeben sind, auf die Suchmaschinen-Crawler nicht zugreifen sollen. Die Datei verwendet den Robots Exclusion Standard, ein Protokoll mit einigen Befehlen. Damit werden die Zugriffsmöglichkeiten auf die Website für einzelne Abschnitte und für verschiedene Typen von Web-Crawlern angegeben, wie z. B. mobile Crawler im Gegensatz zu Desktop-Crawlern.
SERP. Die SERP oder zu deutsch Search Engine Result Page, stellt eine Suchergebnisseite von Google dar. Diese listet die Suchergebnisse (auch Treffer genannt) zu einer Suchanfrage (Keyword) bei einer Suchmaschine (Google) auf. In der Regel findet man dort 10 natürliche oder organische Treffer und 3 bis 5 bezahlte Google-Anzeigen Treffer.
SERP-Features. Unter dem Begriff SERP-Features verstehen wir innerhalb der Toolbox, die verschiedenen Formen von Snippets, die in den Suchergebnislisten von Google auftauchen können, bspw. eine Bild-Integration, eine Google-Adwords Anzeige, News-Boxen, Knowledge-Graphen, Karten-Integration usw.
SEO. Alle Maßnahmen zur Steigerung der Wirtschaftlichkeit einer Website durch die gezielte Gewinnung von Besuchern über die organischen Suchtreffer von Suchmaschinen.
TLD. Die Abkürzung TLD steht für Top Level Domain. Diese ist ein Bestandteil innerhalb einer URL und befindet sich am Ende dieser, beispielsweise www.sistrix.de, www.sistrix.com, www.sistrix.es, www.sistrix.it usw. Die Kürzel der TLDs haben verschiedene Bedeutungen: so stehen bspw. die Abkürzungen .de, .es oder .it für länderspezifische Top Level Domains.
Title-Tag. Der Title-Tag stellt den Titel einer URL dar und wird bspw. in den Webbrowser Tags angezeigt. In den meisten Fällen zeigt Google den Title-Tag auch als Überschrift eines Treffers in den Suchergebnissen (engl. SERPs) an. Der Inhalt des Title-Elements einer Seite (URL) ist ein starker Rankingfaktor und sollte demnach immer gesetzt werden.
301-Weiterleitung. Bei einer 301-Weiterleitung handelt es sich um einen HTTP-Statuscode 301 Moved Permanently. Dies bedeutet, dass der Inhalt einer URL dauerhaft verschoben wurde und nun unter einer anderen (neuen) URL zu finden ist.
302-Weiterleitung. Bei einer 302-Weiterleitung handelt es sich um einen HTTP-Statuscode 302 Moved Temporary. Dies bedeutet, dass der Inhalt einer URL zeitlich begrenzt verschoben wurde und nun unter einer anderen (neuen) URL zu finden ist.
Weiterführende Quellen
- Frag SISTRIX – Deine SEO Wissensdatenbank
- Google – Crawling & Indexierung
- Google – Wie funktioniert die Google-Suche?
SISTRIX für Google kostenlos ausprobieren
Beginne noch heute, mit SISTRIX deine Rankings zu verbessern.
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten