
Die meisten der Analysen und Funktionen in SISTRIX basieren bereits auf den umfangreichen SERP-Daten der erweiterten Datenbank. Jetzt nutzen wir diese Daten auch als Default-Einstellung für den Verlauf gefundener Keywords und rankender URLs.
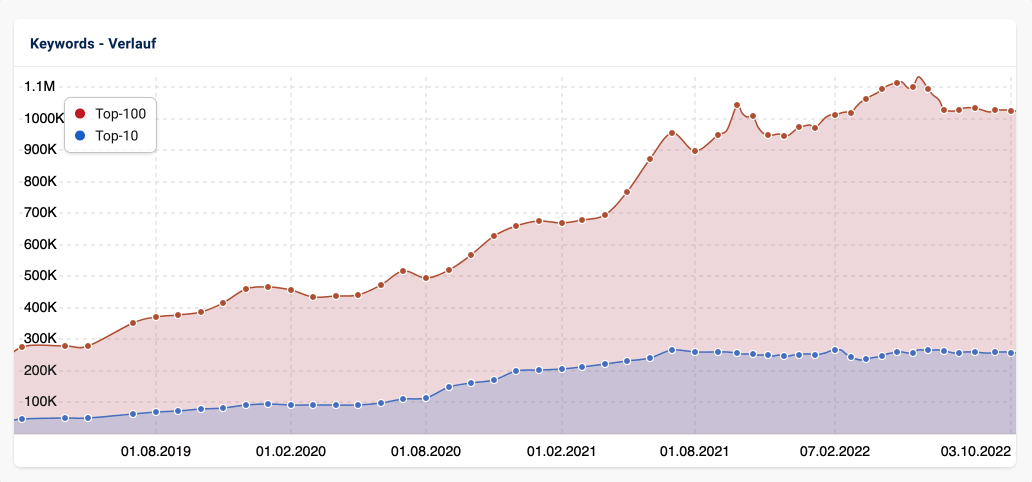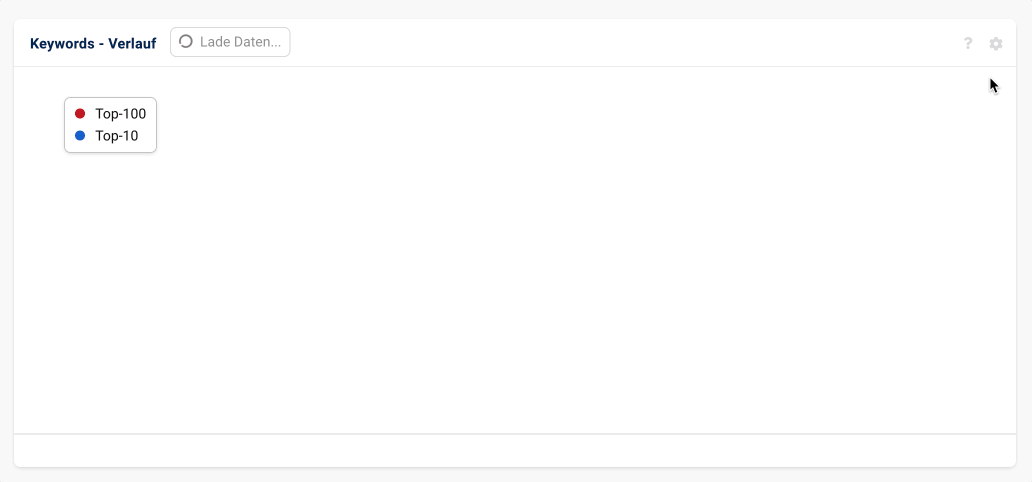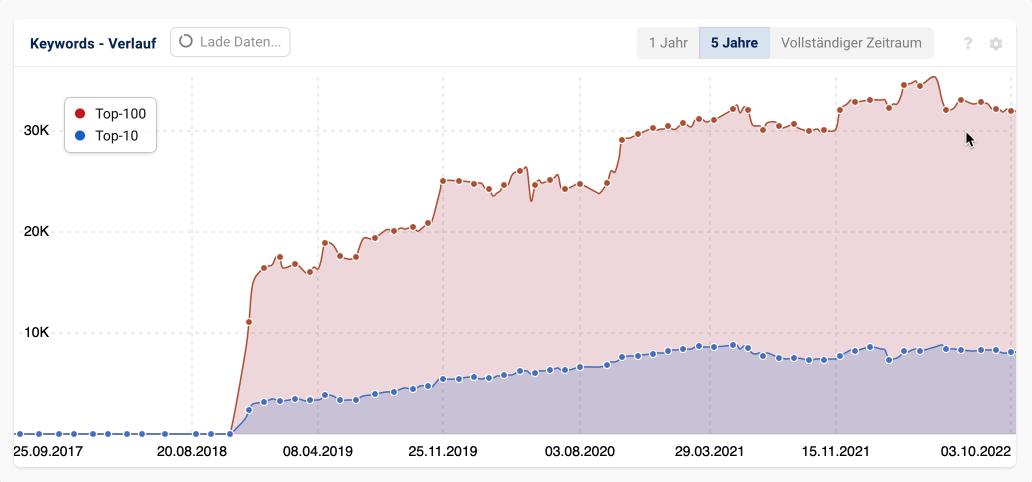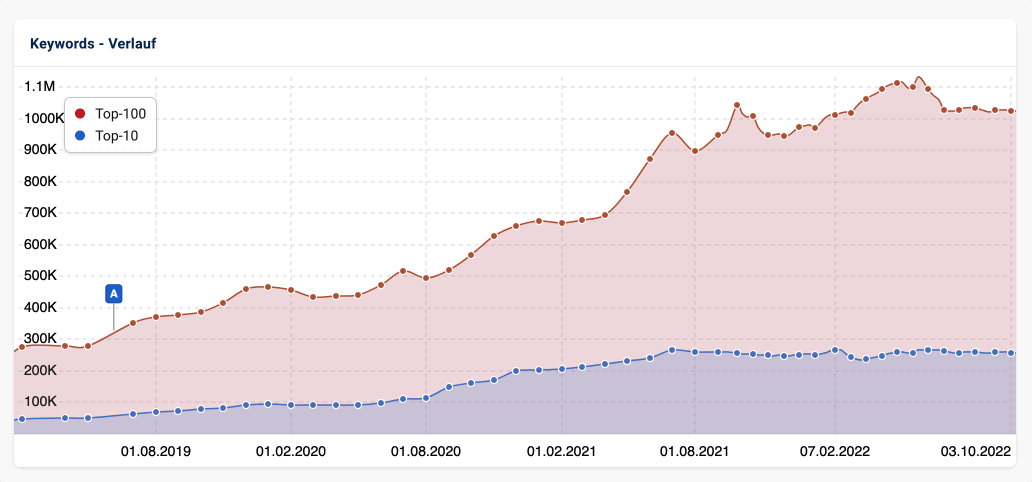
Wie viele Rankings eine Seite in den Top-10 und Top-100 bei Google hat, sowie wie viele unterschiedliche URLs dafür verantwortlich sind, ist gerade im zeitlichen Verlauf eine interessante SEO-Informationen.
Während wir diese Daten bislang standardmäßig auf Grundlage von einer Millionen Keywords angezeigt haben, basiert die neue Default-Einstellung auf den Erweiterten Daten.

Dafür bewahren wir für die letzten zwölf Monate jeweils einen wöchentlichen Snapshot der ermittelten Ranking-Daten auf, für vorherige Zeitpunkte reduzieren wir das auf einen Datenpunkt je Monat.
Wie von SISTRIX gewohnt, lassen sich diese Daten weiterhin nicht nur für ganze Domains, sondern auch für Hostnamen (Subdomains), Pfade oder einzelne URLs auch rückwirkend in zeitlichen Verlauf aufrufen und analysieren.
Standard-Daten für Smartphone und Desktop weiterhin abrufbar
Die bislang angezeigten Verläufe auf Grundlage der Standarddaten (eine Millionen Keywords) für Smartphone- und Desktop-SERPs sind natürlich weiterhin nutzbar. Im Optionsmenü des Diagramms kannst du zwischen den drei Datenquellen jederzeit hin- und herwechseln:
Wann sollte ich welche Datenbank nutzen?
Wie so oft in der Suchmaschinenoptimierung, gibt es leider keine einfache Pauschalantwort, sondern “es kommt drauf an”. Hier die wichtigsten Vor- und Nachteile der beiden Datenbank-Typen:
Die täglich aktualisierten Daten haben den Vorteil, dass sie sehr aktuell sind. Du siehst Veränderungen durch Algorithmus-Updates, Relaunches und andere Verschiebungen mit ihnen sofort. Auch sind sie im zeitlichen Verlauf statistisch sauber vergleichbar: es sind je Land und Device immer eine Millionen Keywords.
Der Nachteil der täglich aktualisierten Daten ist, dass es “nur” eine Millionen Keywords sind. Gerade bei kleineren Nischendomains deckt dieses Keywordset nicht immer alle Sonderfälle, Schreibweisen und Longtail-Begriffe ab. Ähnliches gilt, wenn man von der Domain in einzelne Verzeichnisse oder gar URLs einsteigt: auf Grundlage der eine Millionen Keywords kann die Datenbasis dann etwas dünn werden.
Hier liegt der Vorteil der Erweiterten Daten, die jetzt als Standard für diese Auswertung genutzt werden: so basiert diese Analyse beispielsweise in Deutschland nicht auf einer Millionen Keywords, sondern auf über 100 Millionen Keywords. Eine aktuelle Auflistung der Datenbankgrößen für alle Länder kannst du auf dieser Seite einsehen.
Ein Nachteil der Erweiterten Daten ist die Aktualisierungsfrequenz: zwar werden alle “wichtigen” Keywords ebenfalls täglich aktualisiert, selten gesuchte Keywords aus dem Longtail allerdings nur monatlich. Daher können sich Veränderungen im Verlauf der erweiterten Daten erst nach ein paar Wochen deutlich zeigen.
Auch vergrößern wir die Erweiterten Datenbanken in den unterstützten Ländern regelmäßig. Mehr Keywords heisst dann aber auch, dass die Charts nach oben gehen – ohne, dass sich am realen Status Quo etwas geändert hat. Wir kommunizieren diese Erweiterungen der Datenbank und werden Ereignis-PIN einfügen.